Dear all,
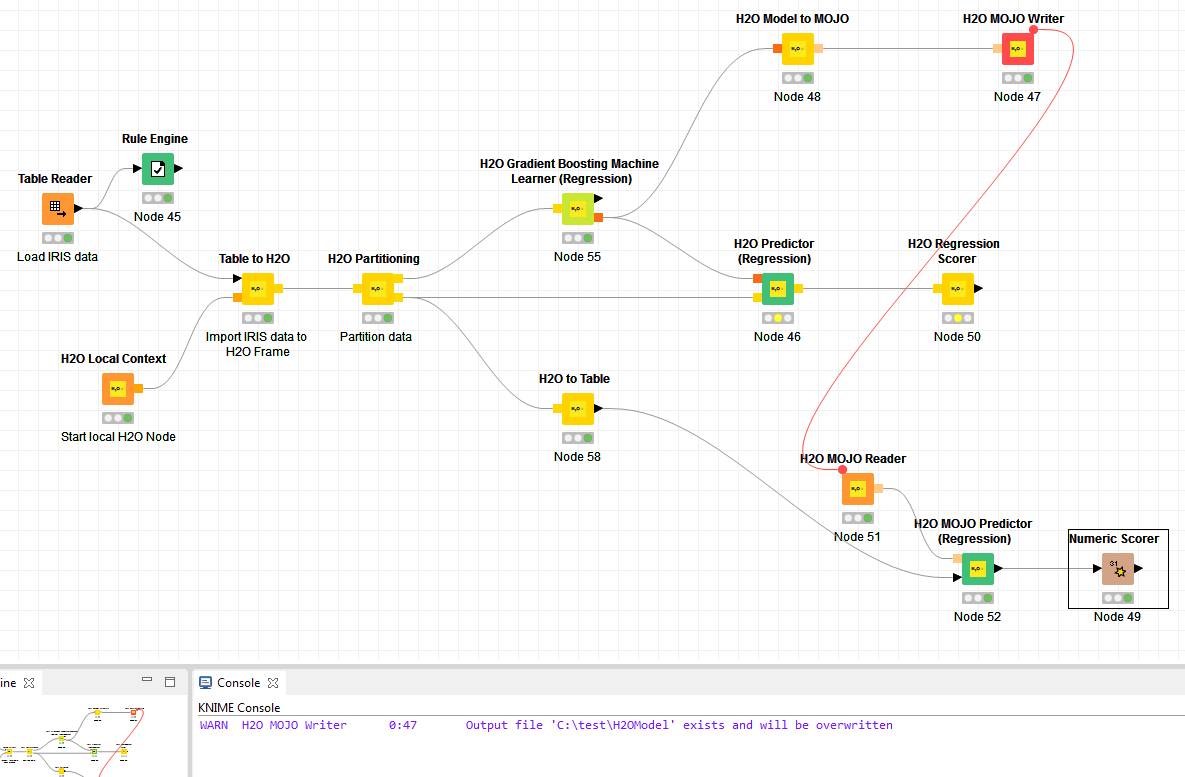
there is a bug in Knime H2O MOJO Predictor (in both v 3.5.3 and v 3.6 ). As you can see in the workflow attached “H2O Predictor (Regression)” is able to do prediction on Column names or Column content that contains accents.
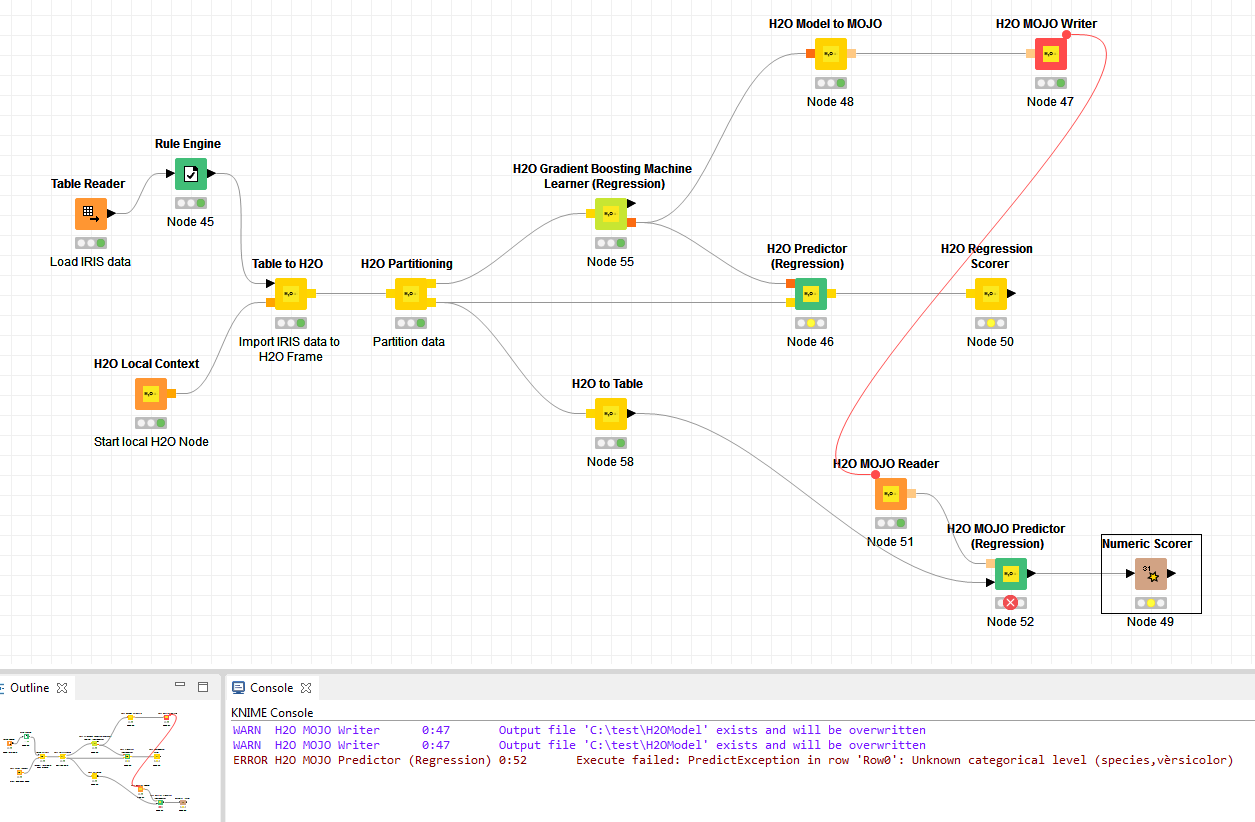
But “H2O MOJO Predictor (Regression)” is not able to do prediction on Column names or Column content that contains accents and provide me the following error:
I would be really interested in following the resolution of this bug since I cannot proceed in my work because of that.
Thanks for your prompt feedback!
Kind regards
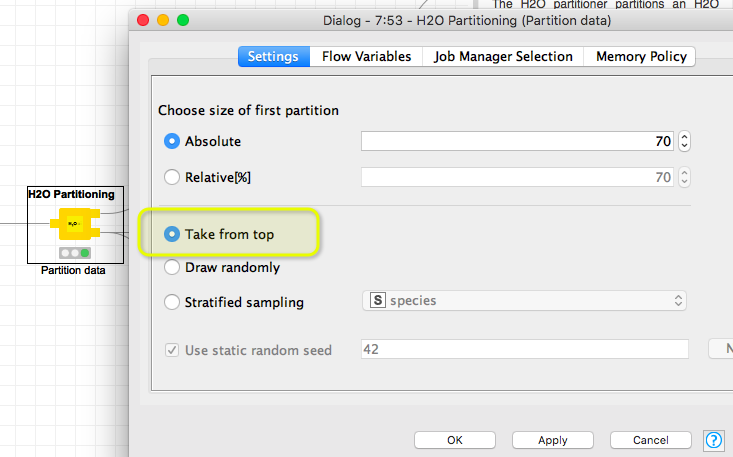
as far as I can see the error message means that the model found a categorical level it has not seen before. This might be due to the fact that in your sample workflow with the partitioning you just took values from the top so in the 30% test cases this level might no be included. As far as I remember the working of the H2O models you could either let it fail or it would apply a missing value (which I think makes sense).
In the workflow you try to predict the petal_width by providing the species.
Dear mlauber,
many thanks for your reply. But I think that the error message is misleading and it is not a problem if the model find a categorical level it has not seen before.
It is a problem of accents.
In fact if you disconnect the Rule Engine node that insert accents (connecting directly the “Table Reader” to the “Table to H2O”) everything works well.
Please find attached the workflow.
I guess actually it is a problem if a categorical level is detected which was not present in the training data as H2O automatically encodes categorical data into numerical data and saves the encoding model alongside with the prediction model. If a categorical value was not present during training, the encoding can’t be done. Can you confirm that all categorical levels are present during training which are presented during testing?
Dear Christian,
many thanks for your reply. If you open the workflow “H2O Pojo to Mojo_v4.knwf” you will see that H2O is able to do prediction on a category not seen before (at least it does not produce any error).
The error is produced if you connect Rule Engine node that inserts accents.
So it seems it is a matter of accents and not a matter of new category.
Could you confirm it is a bug?
Thanks
Regards
I cannot reproduce the error. With my installation it works with or without accents. Could you check which OS and version you have (mine is below). As far as I know there is no special unicode setting in KNIME it should just work like it is.
You could check your local H2O context. After upgrading to 3.6 I had some problems and hat to restart KNIME once with an option “-clean” at the very top of the knime.ini
I have the same error in both Knime v 3.5.3 and Knime v 3.6. I have the same error with a local PC with Windows 7 64 bit OS and with a powerful Windows Server 2016 64 bit.
Indeed, this looks like a bug to me as well. There seems to be an issue when domain values contain special characters. If you check the output port of the H2O Model to Mojo node, you see that the column domain values look somewhat deformed. We will continue investigating on this and let you know as soon as we know more.