Hi @gonhaddock , for the challenge, it’s been mentioned: ‘Also don’t worry about getting 100% accuracy.’ I think the intention behind this particular challenge is to show different methods to achieve a simple task of categorization. Any method including yours will fit into this intention, as long as it uses the categories provided.
4 Likes
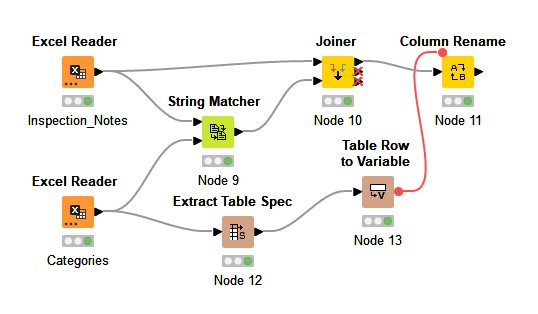
Here’s my solution. Uses three nodes by embedding the categories with appropriate widlcards in a Rule Engine node.
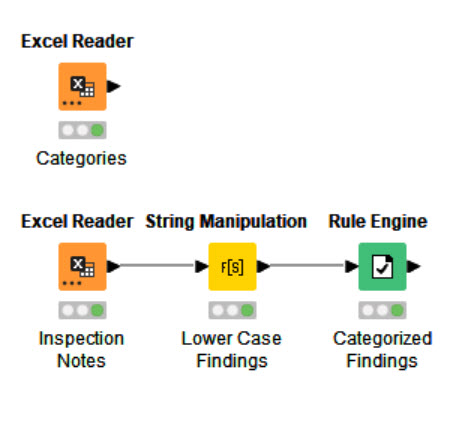
REF Challenge 18.knwf (42.9 KB)
1 Like
Hello @badger101
Thanks for the clarification; I already was aware of that. However in my case, I take the challenge as an opportunity to learn subjects that are out of the scope of my daily duty, I’m not taking it as a goal itself; then I learn from all your different approaches to the same tasks.
Then my question is just because I’m curious on the subject: if is there an preconfigured node/component, or in a more abstract way a method; that can return a king of fuzzy approach on quantifying every possible matching combination? and and then a tolerance cut…
I don’t think that a classical NLP method like Bag of Words fits for this challenge as the approach requires extensive data to be trained…
BR
@gonhaddock I’ve never worked with any supervised ML project, so I can’t answer from experience. I have only worked with unlabeled corpus. If we are to obtain as much matching as possible without human labeling, the misspelled words should be addressed first. Our matching tool is just as good as the dataset. I saw one of the solutions had already addressed this the simple way, which is by using wildcards. That’s one way to do it, but it still requires human intervention. Works like a charm for a small dataset like this, but won’t be the case for large datasets. (Although, if one uses stemming tool which gives a similar effect and doesn’t require human intervention, stemming won’t be accurate for large datasets since there’ll be so many English words that start with the same characters e.g. referral, reference, refill, refund)
3 Likes
@gonhaddock Also: Fun fact, there is a spellchecker node available exclusively via NodePit. Spell Checker (simple) — NodePit
but since it’s an ‘unsigned software’ (whatever that means), I’ll get this notification when trying to install the extension:
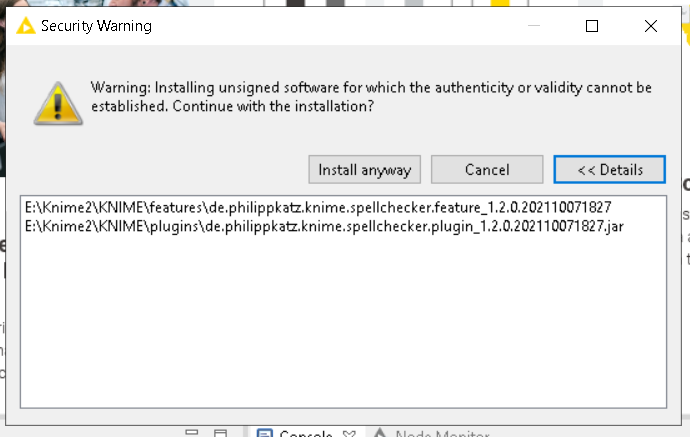
As of this date, if I go to the page and click on the Developer section to reveal the source code, it’s not available. As I sometimes can be a risk-avoiding individual, I’ve never proceeded. I wonder if there’s an active user of that node who could share their experience here.
3 Likes
hi @badger101
Sure, security first.
For the time being, not cool but, maybe the easiest is to aggregate /append the misspellings detected as an additional Table Creator with the correlated Wildcard; as suggested (I’m not saying that I’ll do, as it doesn’t add value to the approach).
Test the similarities could be another option ![]() but I’d need the full understanding of it or full develop a kind of fuzzy probability check…
but I’d need the full understanding of it or full develop a kind of fuzzy probability check…
Thanks for your time.
2 Likes
@gonhaddock Addressing the misspelled terms can also be done in various other ways. Advanced KNIME users like you might want to check out this thread and somehow find a way to integrate it into KNIME by creating a new component. It’s a possibility.
2 Likes
Hehehehe the differences can be subtle sometimes, but they’re still there! ![]()
![]()
2 Likes
Hi everyone,
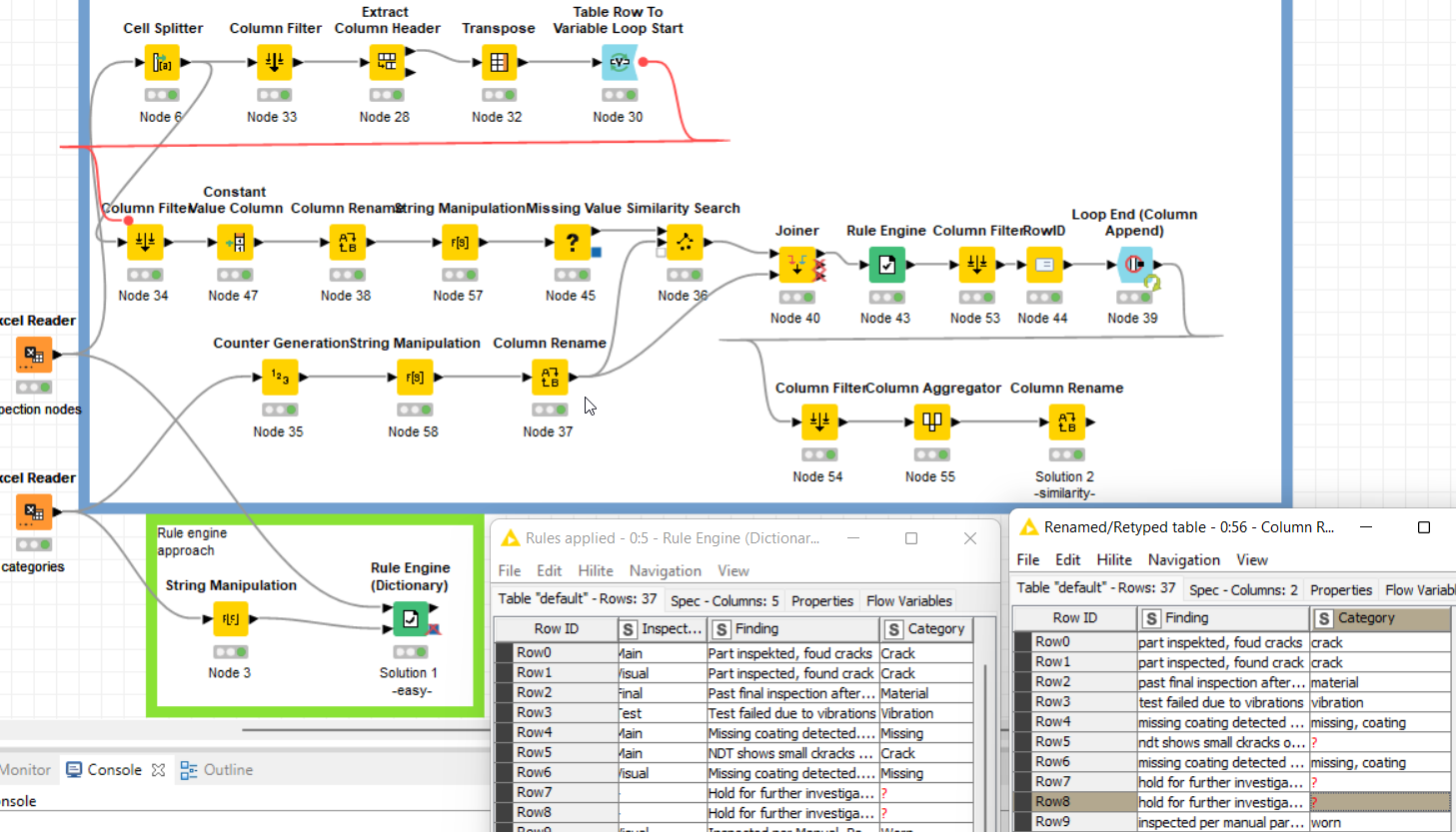
here is my solution.
Probably low perfomance on large datasets.
Not used engine rule.
1 Like
Hi here is my solution. I used some nodes that are new for me and it results in tags.
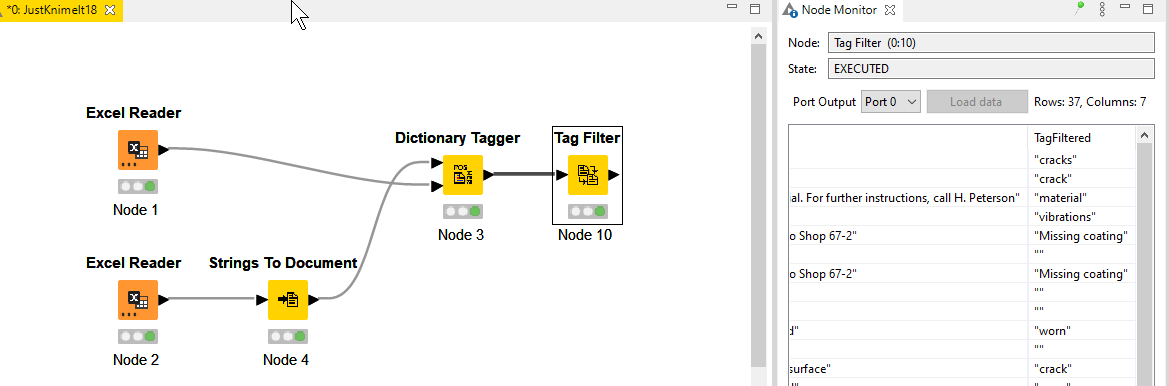
I would not be happy if I would need to use these tags as input for any following workflows so I’m happy to see all your solutions have a different approach.
1 Like
@badger101 That’s a quite common pattern for free and open source nodes. We developers who create such nodes in our spare time with limited resources usually don’t want to spend much money on expensive certificates to sign the nodes. So if you know the source (URL, HTTPS, reliable vendor), you can safely install such nodes.
NodePit says this:
You might see a warning regarding missing signing/certificates. You can safely ignore this. Most community developers of free and open source products do not sign their products to avoid large costs for acquiring certificates.
The Spellchecker Nodes are developed by @qqilihq who also develops the Palladian Nodes and the Selenium Nodes. So I would consider them safe ![]()
Best regards,
Daniel
3 Likes
![]() Thank you so much for the explanation. Really appreciate it. I was busy these last 2 days creating tools to address my previous concern, which now is not a concern anymore based from what you just wrote.
Thank you so much for the explanation. Really appreciate it. I was busy these last 2 days creating tools to address my previous concern, which now is not a concern anymore based from what you just wrote.
I’m deciding now whether I should keep these to myself, or to publish them on the hub as an alternative:

4 Likes
2 Likes
Thanks for the great explanation, @danielesser and thanks for rising that question @badger101. Here’s some additional 5 cents about that topic (from the maker of the Spellchecker nodes perspective):
We (NodePit and Selenium Nodes) currently do not sign the jars (no matter if it’s for free or for paid nodes). Signing them gives little objective security benefits but it’s a big hassle on top of the plenty of big hassles one faces in the Eclipse/KNIME development ecosystem (and which we rather invest in building great software).
Why no security benefits? As seen above, most users do not really know what “signing” exactly means. Facts: It will not protect you from bad/malevolent software. There is no external entity involved which “validates”, “authenticates” or “reviews” the “signed” software at all. At the end, the main reason for signing the software would just be about getting rid of that annoying dialog (which is definitely frightening).
So. Should you “trust” the Spellchecker nodes? This question I cannot answer ![]()
Should you make your decision based on that unsigned content dialog? I think no.
By the way: For any questions about these nodes, don’t hesitate to get in touch!
–Philipp
3 Likes
@qqilihq Update: I just downloaded and tested your node. It worked remarkably well! Will definitely keep it as my permanent collection to use when it matters ![]()
4 Likes
Whoah! This is super cool and insightful!
2 Likes
Hey
Here’s my solution.
I tried a few of the purpose build nodes, however I wasn’t pleased with the result. The most accurate that I got, was using a simple contains().
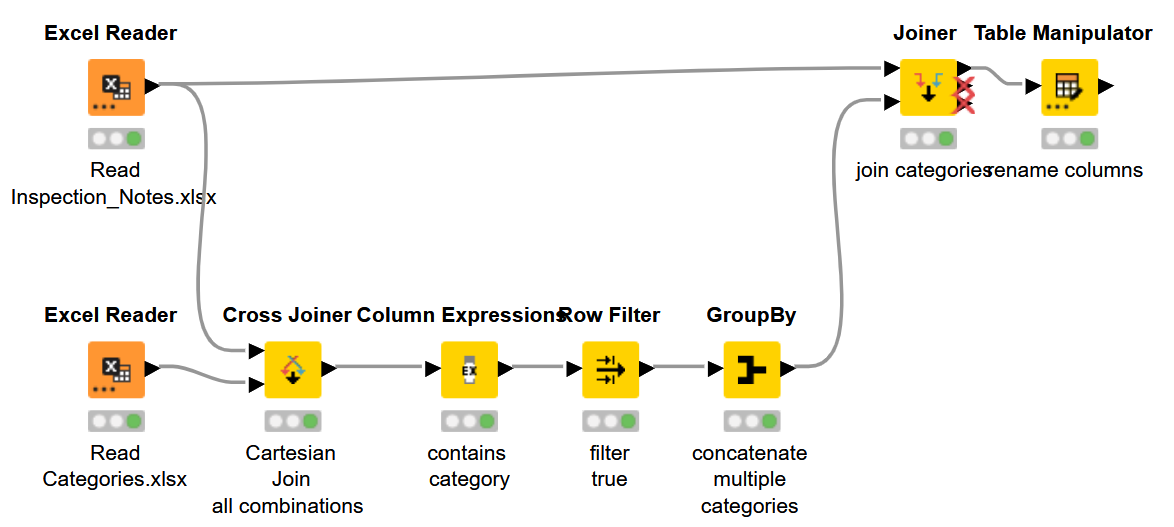
/MMU
2 Likes
MY take on this weeks challenge.
2 Likes