Hello Knimers,
here is my solution:
AutoML node left me speechless! D:
Have a nice day,
RB
Hello Knimers,
here is my solution:
AutoML node left me speechless! D:
Have a nice day,
RB
Hi everyone,
Here is my solution.
Using AutoML component made the workflow folder ~60 MB in size.
However just using one learner like decision trees folder size end up ~1MB
Automation causes 60x growth in folder size.
Hi everyone! Just finished the challenge and decided to change a little bit what you guys were doing. I decided to go for a random forest learner, for that, I used the SMOTE Node to oversample the input data. With this methodology, I reached to an accuracy of 95.502% with Cohen’s kappa ~~ 0,8% ![]()
You guys can check it out here!
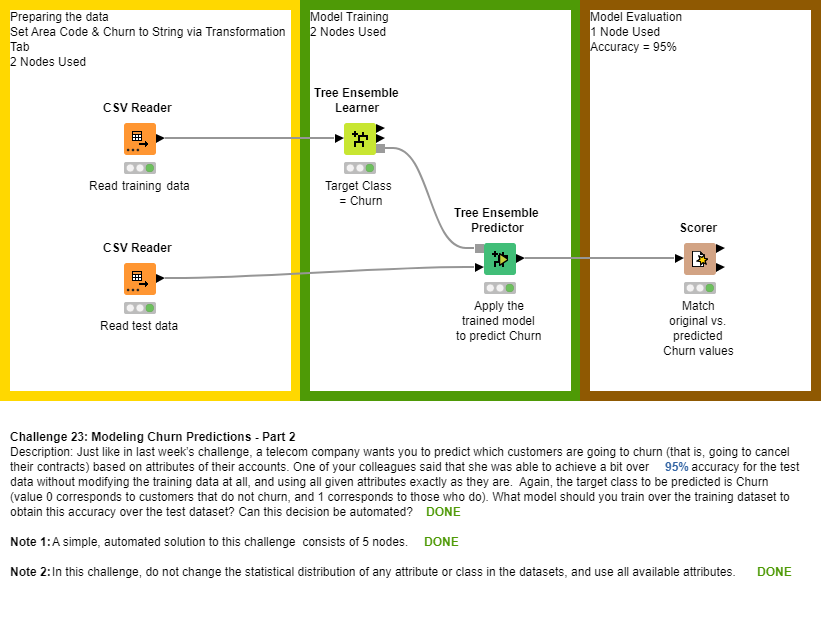
Here is my entry for this challenge, using Ensemble Learner and Predictor Nodes which achieved 95% accuracy by tweaking the split criterion and number of models

You’re welcome! A curiosity: how did you get to the decision of using XGBoost? ![]()
Hey @ersy, thanks for the feedback! Did you try resetting your workflow before uploading it to the Hub?
Hi @alinebessa,
In the previous part, I had already tried XGBoost for performance tuning (even if it wasn’t really the target of last challenge).
Since Tree methods look quite relevant for this dataset, Boosted Tree are very effective at optimizing accuracy/performances, and XGBoost is one of the best performing Gradient Boosted Tree model, XGBoost was the most interesting model for me here.
It combines good performances, explainability, and relative low size (compared to using AutoML for example), so easy to use and deploy, and providing fast computations ![]()
Another idea I had in mind was to choose several Tree models and fine-tuning them with the Hyperparameters optimization component, I might give it a try for curiosity ![]()
hi
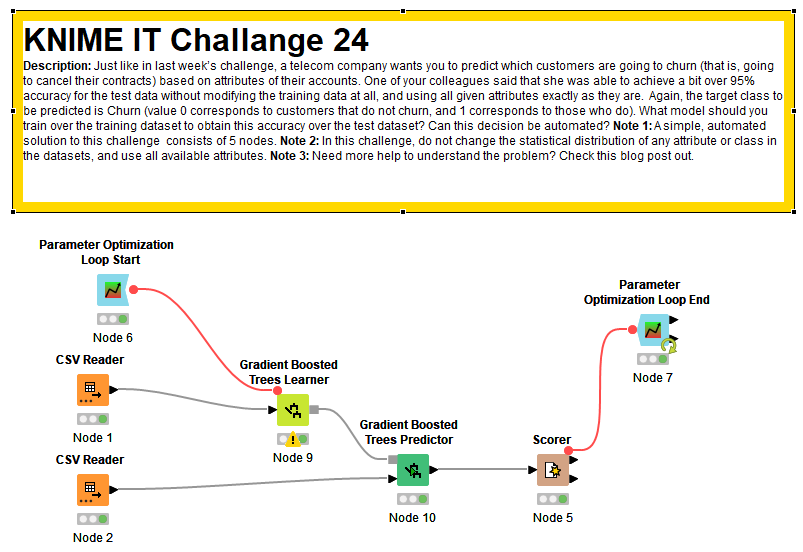
Here’s my solution to challenge 24.
I coincidentally solved this in previous challenge 23 Solutions to "Just KNIME It!" Challenge 23 - #10 by martinmunch
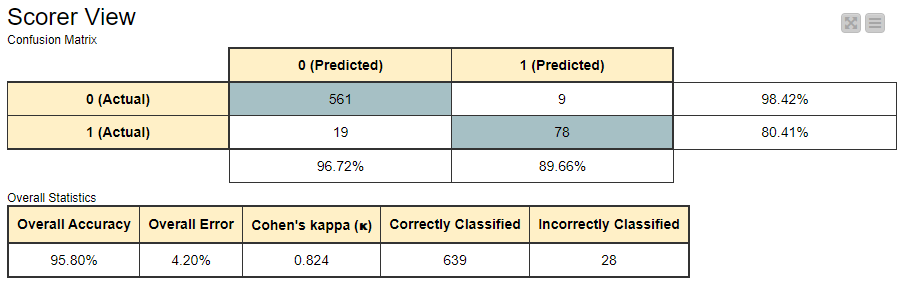
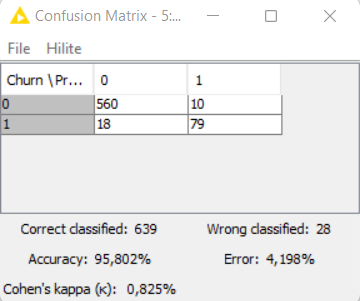
So compensate for time saved, I played briefly with feature engineering and normalization. (potentially a topic for future challenges?). I managed to get accuracy 95.80% Unfortunately I forgot to save and only have a screenshot to show for it ![]()
I used a “simple” SMOTE node with fixed seeding (so that results can be recreated) and scored 95.65% in accuracy, close but no cigar ![]()
cheers!
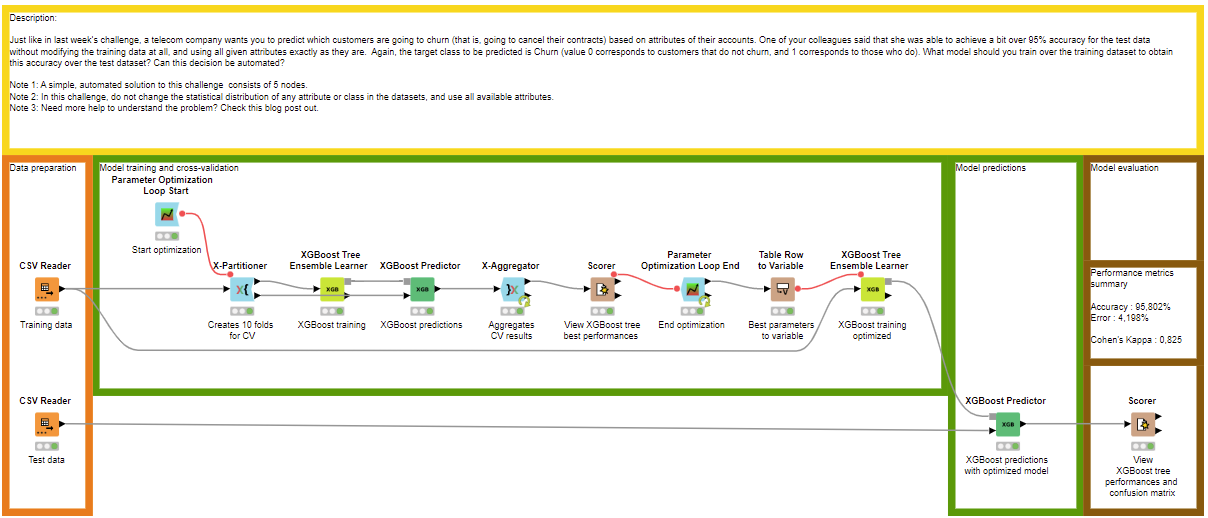
Hi Martin and KNIME enthusiasts,
By optimizing two hyperparameters in an XGBoost Tree model, without touching at the raw data (no transformation, no SMOTE, etc … as mentioned in the challenge), I can get an accuracy very close to 96% (it’s actually 95,952%).
I guess that’s worth a cigar ? ![]()
Did you try to save the workflow after reset?
A new feature should come up soon where you can require components to not save data inside the component at each node output. This should improve the issue you are facing. I also heard the representation of workflows might be different from the current folder system at some point.
Until then try to write the output of the automl component via a workflow writer node. After that reset the workflow and then save it. It should become lighter if size is an issue. In your case (60MB) it should be all right for most systems.
Very nice. Will surely check it out.
How did you tune parameters? By hand or some node supported parameter optimizer / X-Aggressor?
Hi @martinmunch,
I used the nodes Parameter Optimization Loop Start and End (Parameter Optimization Loop Start — NodePit and Parameter Optimization Loop End — NodePit), just like @Rubendg did in his workflow.
The optimization was done on two hyperparameters “Maximum Depth” and “Minimum Child weight”, with a Bayesian Optimization (TPE) strategy.
I got the following optimized values for the hyperparameters : Maximum Depth = 10 and Minimum Child weight = 4,802. As I didn’t fixed a random seed (shame on me), I’m not sure this exact results will be reproducible, but with this framework and the use of XGBoost you should be able to boost your accuracy results.
With a proper training-validation-test workflow (and still without data transformation, SMOTE or anything), always with XGBoost and the fine-tuning of same two hyperparameters and with (hopefully) all nodes with a fixed random seed, I can get an accuracy to 95,802%, exactly what you had previously ![]()
Here is the link to the workflow : justknimeit-23part2_optimization_Victor – KNIME Hub
Definitely out of scope for this challenge regarding the number of nodes, but still interesting to look at model optimization.
I prefer this optimization version than the simple one with the fine-tuning on test set (@Rubendg), as the final accuracy result obtained the simple way won’t be a fair metric/assessment : the test set, which is supposed to be independant from training and validation of a model to properly assess its performance on unseen data, is used to fine-tune a model, so the assessment is not reliable, independant and generalizable.
With the cross-validation on the training set, test set remains independant and only used at the end for model assessment, so the performance and accuracy metric is reliable.
Still, you can remove all the model optimization nodes to just keep the 5 main needed nodes (and properly configure optimized hyperparameters of XGBoost training node) to enter the challenge with a high accuracy ![]()
Oh wow! Really interesting to see how so many of you are already exploring optimization techniques and data engineering for this problem! ![]() We’ll be exploring this more in the coming weeks.
We’ll be exploring this more in the coming weeks.
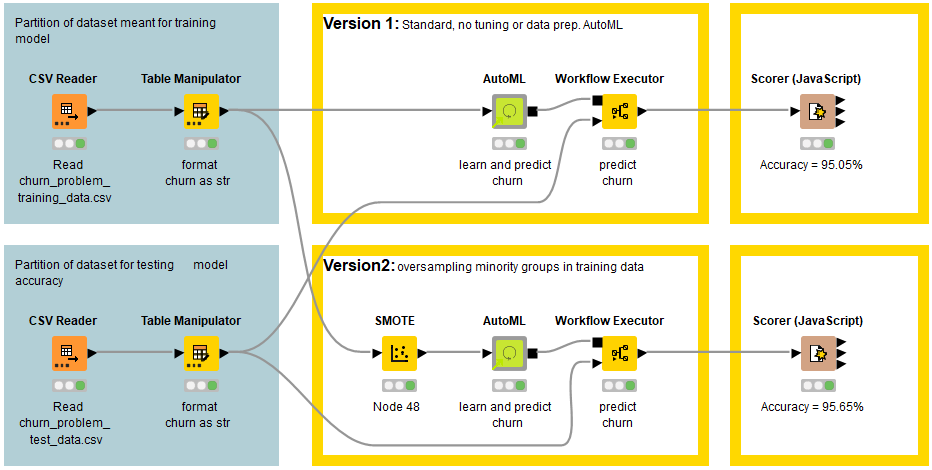
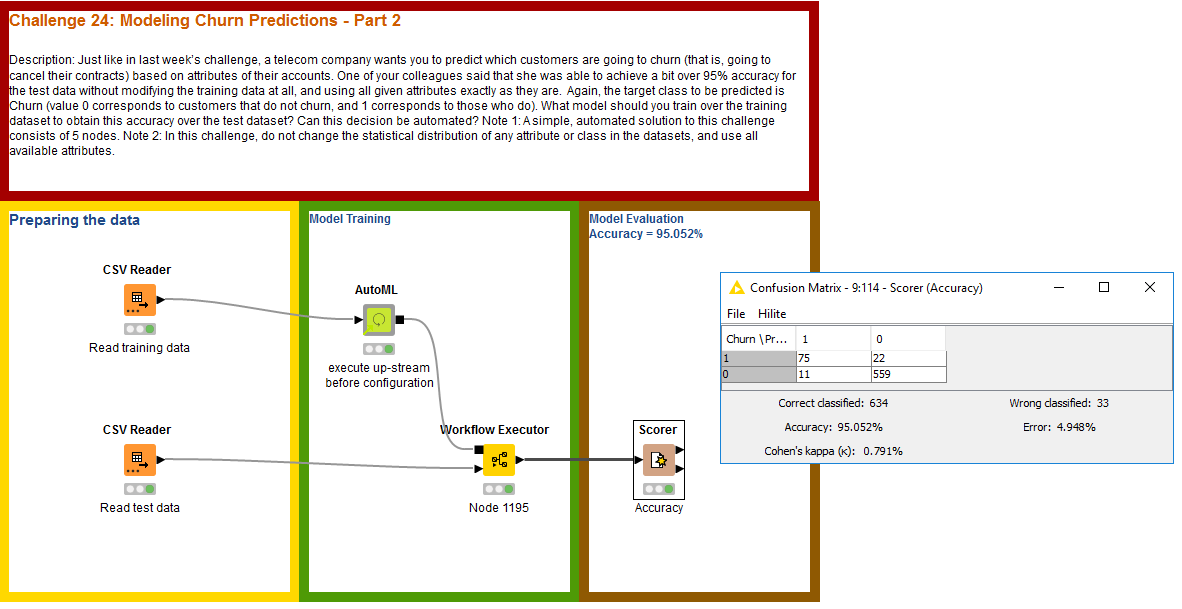
For now, here’s our solution for last week’s challenge. We used our AutoML verified component and the chosen model was Gradient Boosted Trees, in a technical tie with XGBoost Trees and H2O’s GBM. Note that it’s not possible to simply state that Gradient Boosted Trees generalizes as the best model for this problem: we’d need more data to draw a proper statistical analysis here, comparing overlaps across confidence intervals for different solutions, for example.
![]() See you tomorrow for a new challenge!
See you tomorrow for a new challenge! ![]()
Hi @alinebessa,
I think for some of us, the choice of a specific model was guided by EDA (done here or on the previous part of the classification challenge), experience/knowledge about algorithms, and more important the “note 1” requirement to only do a workflow with 5 nodes.
Technically speaking, using the AutoML component make the number of nodes rising (much more than 5 ![]() ), even if only 5 are present on the main screen.
), even if only 5 are present on the main screen.
That may explain why some of us have chosen a specific model, and not the AutoML proposed component.
Looking forward to the next challenges !
You’re right! Note 1 in the challenge should be rephrased to “A simple, automated solution to this challenge consists of a mix of 1 component and 4 nodes” or something like that. Good catch!
And yes, there are definitely other ways of choosing a model for this, even if they’re not as “automated” as using an AutoML component is.
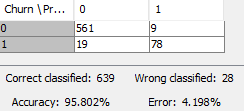
Quite challenging! Here are my results:
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.