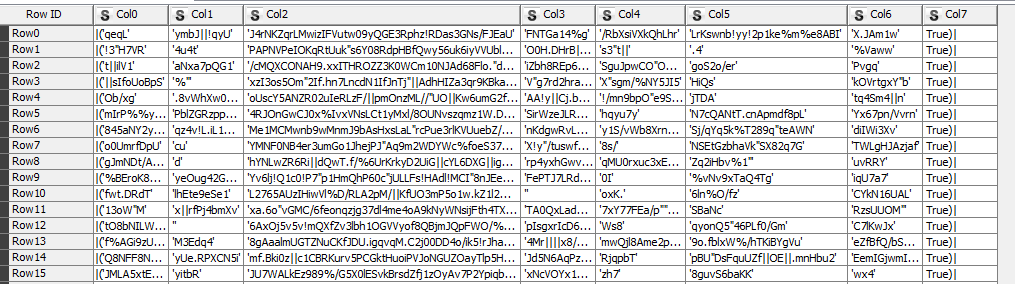
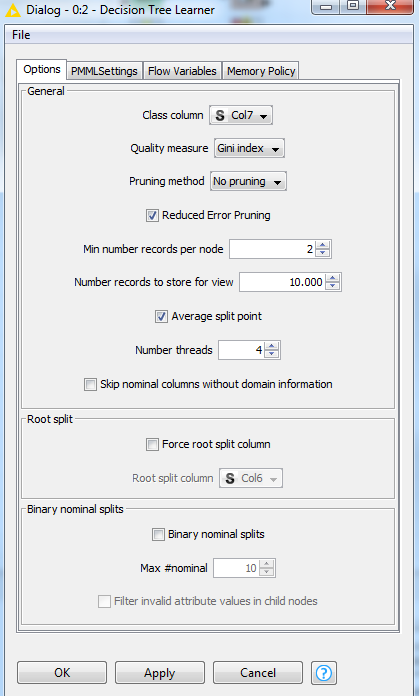
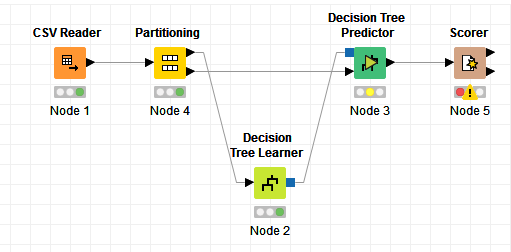
I’m totally new here and a hardcore newbe with Knime. I have a .csv with 8 collumns, 7 with a lot of strings and 1 with true/false. I want to built a decisiontree for this table to get some rules to classify a row, wheter it’s true or false.
Now here is my problem, every time I start the algorithm, i run out of Heapspace although I gave Knime 12 Gigabyte of RAM. I can add another 16 GB, but I think 12 should be more then enought. Where is my Mistake? Please help me! :D.
Let’s look at Col0. If you have n rows and n distinct string values for Col0, it makes no sense to use this column as a Feature for any learner. The same holds for any other column.
the rule behinde this is, if a string in the col 0-7 contains one of the follwing chars: " %!|’/". " col 8 is true, otherwise its false.
In this case, I know the chars, but it’s only testdata, so in another case I would like to get this information from the algorithm.
Is there any way to define an algorithm to check the chars in the strings instead of the strings?
if a string in the col 0-7 contains one of the follwing chars: " %!|’/". " col 8 is true, otherwise its false.
In this case, I know the chars, but it’s only testdata, so in another case I would like to get this information from the algorithm.
Then you could build a workflow which maps those strings to their “bag of chars”, have a 1/0-encoding for each char per sample (where 1 means: “any of the strings contains the character X at least once”) and train the classifier. With such preprocessed data, DTs (and other classifiers as well) will work fine.
Simplest way to do the encoding would probably be to apply one of the several scripting nodes (Java, Python, …)
i tried for some days to fix my problme in the way you told me in the first solution, but im curious about solution 2. Where can i find this Classifier?
The TextClassifierLearner node, which I think is what qqilihq is referring to, is available in the Palladian for KNIME extensions. You can install these by going to File --> Install KNIME Extensions… and searching for Palladian.
(@qqilihq, please correct me if I’m suggesting the wrong node!)
An accuracy of 92% might be very good or not – make sure to check against the baseline of your data. What would the accuracy be when predicting everything with the majority class? This is your baseline.
In case you haven’t done so yet, have a look at the ROC curves as an evaluation measure. They give a better impressions how good your model performs over all.
The TextClassifierPredictor node allows to specify different scoring algorithms. You can try whether different scorers give better results.
Hi guys. I tried several settings but could not improve my score.
@qqilihq you mentioned the “bag of words” method. I guess it goes in the way of a one-hot-encoding. I would like to try this. First i tried it with the one-to-many Node but it will only accept nominal values. Is there an example you can give me for this kind of method with a scripting node?
I also dont know how to create new columns by the scripting node
As you’re trying to classify based on the characters in your strings, you’d need the mentioned “bag of characters” vector. You can build that e.g. with a Java Snippet node using the following code (this just covers lowercase a-z for sample reasons, but you can adapt it to your needs easily)
Create an output cell which creates a Boolean array and use the following code:
This node will then produce a 26 element boolean array which denotes whether a given character occurs. To feed it to e.g. a DT learner, you’ll most likely need to split the collection column into individual columns. You can achieve this using a Split Collection Column node.
HTH,
Philipp
PS: This also has room for improvement – instead of a pure binary vector you could also create count vectors