I want to use the “GROUP BY”, but the column names to be used for grouping need to come from an external source, in this case from an XML file on which I do an XPath expression. The latter works well, but how do I pass these names to the “GROUP BY”?
Many thanks in advance!
Hi there.
Maybe more vivid example will help to understand better, what do you actually need.
BR,
Alex.
The columns to be used for grouping can vary, therefore they are described in an external XML file (CDISC define.xml). This XML file is read and parsed, and the output is a table with the column names to be used for grouping in the other table which come from a SAS-XPT file. I attach a snapshot of what I got so far.
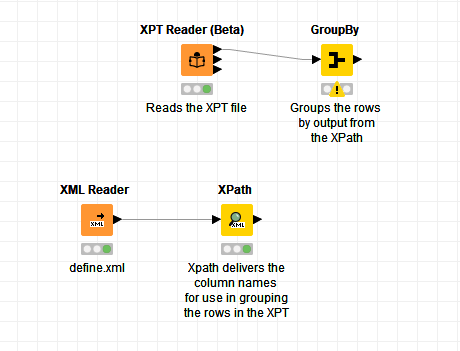
I think I saw something similar before on the forum.
Please, take a look:
I hope that help you.
BR,
Alex
2 Likes
Hi,
If the number of grouping columns is always the same, then everything is straightforward and you can follow the links provided by @alex_never to find out how to set grouping columns in GroupBy node.
Just as a quick hint here: you need to convert the names of the grouping columns from the XPath node to variable by using whether “Table Column to Variable” or “Table Row to Variable” nodes regarding the option you have selected in “Multiple tag options” section of the configurations in XPath node. The variable port then must feed the GroupBy node. Now in the configuration window of the GroupBy node, first select the grouping columns (names do not matter just the number of selected columns matter and these selected columns can not be used as aggregation columns), then in the Flow Variable tab of the configuration window, under “groupByColumns” -> “IncList” you will see numbered options, there you can assign the variables (the names of the grouping columns) to the options. And that’s it.
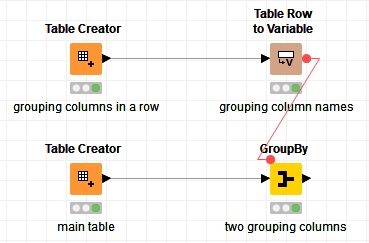
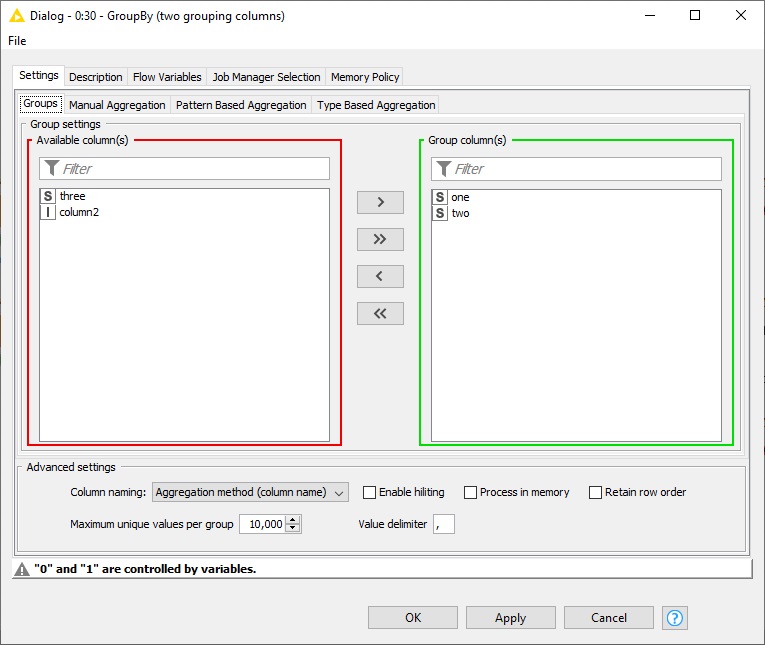
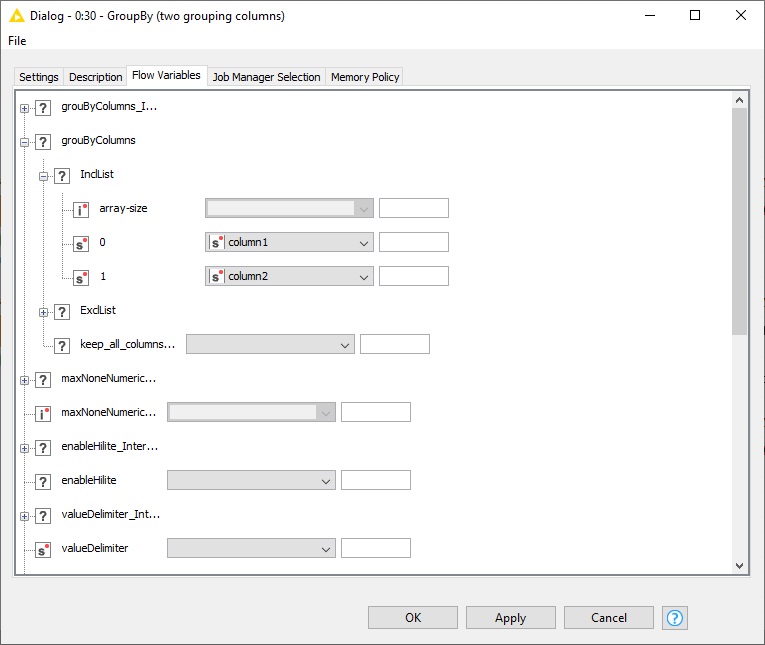
But if the number of columns is changing then it would be a bit tricky to handle it. Below I have explained a method to handle three cases, which means the number of the grouping columns can vary but works only for three different cases. (The number of cases can be increased with nested switches)
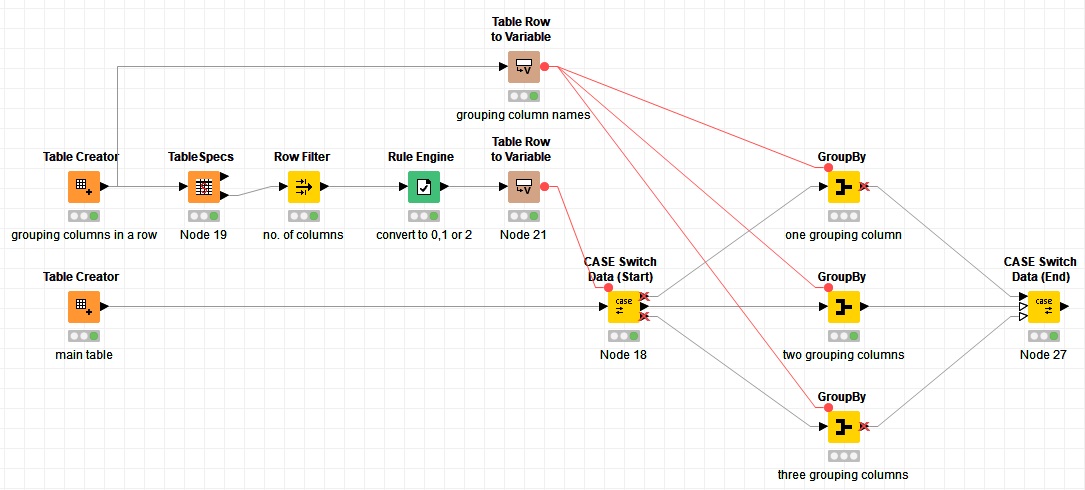
Here I have added a new flow after the table which contains the names of the grouping columns. A TableSpecs to read the number of columns and a Rule Engine node to convert this number to 0, 1 or 2 to feed the Case Switch Data (Start) node and determine the output port. Then three GroupBy nodes in which I have selected 1, 2 or 3 (That’s an example, it could be e.g. 5, 7, or 10) columns like we discussed before and assigned the column names (the variables) in the Flow Variables tab.
Here is the workflow so you can check it by yourself and don’t hesitate to ask your questions:
groupBy-changing columns.knwf (48.5 KB)
Best,
Armin
4 Likes
Thanks to you all, I got it up and running!
Needed to do some string manipulation in between, but that was no problem.
A picture is below.
I need to do some additional testing in the next days. The goal of all this is to execute the rule on the XPT tables that rows need to be unique based on the information from the define.xml. So also using some files where the rule is violated.
I also need to find some way to export this all as pure text (“script”). Probably easy, but these are my first few hours with KNIME …
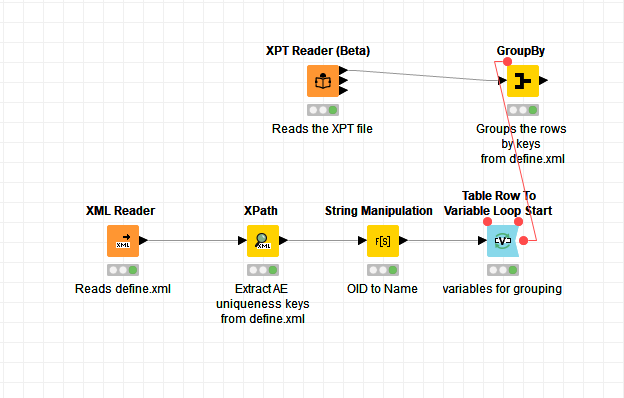
2 Likes
This topic was automatically closed 182 days after the last reply. New replies are no longer allowed.