Hello all,
I am quite new to Knime (1 week) and have a few questions.
I am trying to set up a workflow for checking multiple columns with multiple criterias, but I don’t know which nodes I should use for. The Task is the followng:
I have a table with 49 columns and ~500k rows. Based on the values of two of these columns, I Cluster the rows into Groups. According to these Groups, the values in the remaining columns need to have certain, predefined values.
So the logic must be:
If Column A has Value X and Column B has Value Y, then Columns C-XXX need to have predefined values.
Currently I tried to set up different row filters for the values to just Display the Errors, where the values do not fit, and afterwards combine everything in one Output file again. But this would mean, that I need 40+ nodes (row filters) to check every value. Also tried it with JAVA Snippet and IF-Then Statements, but this would also led to a lot of individual nodes.
Now the question: Is there a better Approach to my Problem?
Thanks in advance and I hope that my issue is understandable 
Best,
Dennis6713
€: Example from post below:
| C1 | C2 | C3 | C4 | … | Cn | |
|---|---|---|---|---|---|---|
| 1 | V1 | X1 | A1 | … | … | … |
| 2 | V1 | X2 | A2 | … | … | … |
| 3 | V2 | X3 | A3 | … | … | … |
| 4 | V3 | X4 | A2 | … | … | … |
| 5 | V4 | X5 | A1 | … | … | … |
| 6 | V4 | X5 | A2 | … | … | … |
| 7 | V4 | X6 | A3 | … | … | … |
| 8 | V4 | X7 | A4 | … | … | … |
| 9 | V5 | X8 | A1 | … | … | … |
| … | … | … | … | … | … | … |
| n | Vn | Xn | An | … | … | … |
What I want to do now is the following:
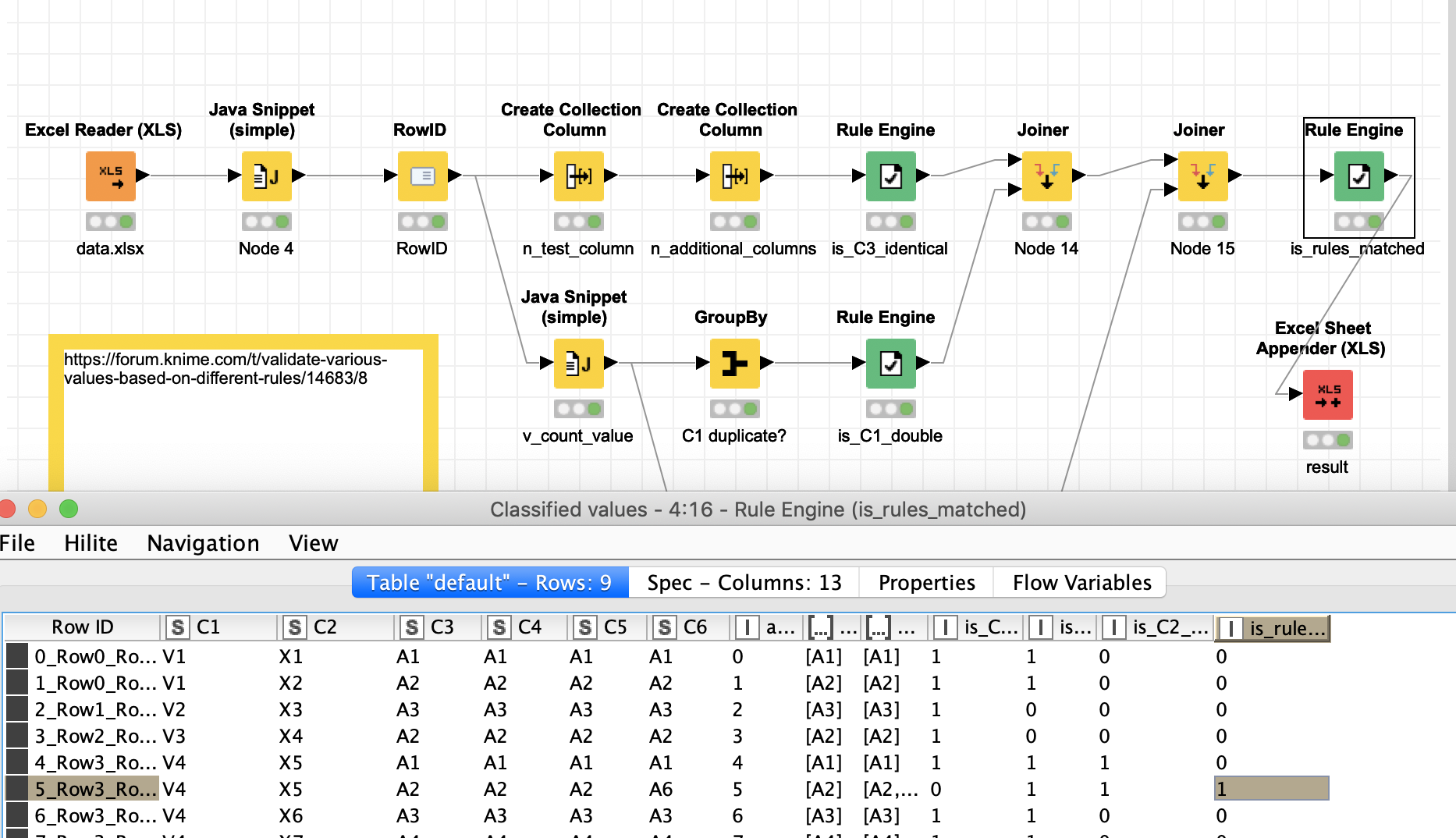
Check if there are duplicates in C1 (e.g. Row 1 and Row 2, Row 5 - Row 8)
–> If yes, then check if the values in C2 are also the same. (e.g. Row 5 and Row 6)
–> Then check the value in C3. All of the Columns C4…Cn in row 5 and row 6 need to match predefined values, based on the value in C3.
–> If the values in C2 are not the same, check C3 and all of the Columns C4…Cn in this row need to match predefined values, based on the value in C3.
The output should be an excel file where the Cells (Column C4…Cn) are highlighted, in which the values do not match the predefined values.