Hello community,
Iam new to Knime and to data mining and I am currently stuck on some data and I dont know how to continue. Here is my problem:
I have a dataset of upcoming machine events which are stored into an excel file. Every time an event happens the event will be stored into the file with an “event name” and “timestamp”. Sometimes an critical error occured and my problem now is that I want to analyse the last events happened before the critical error came.
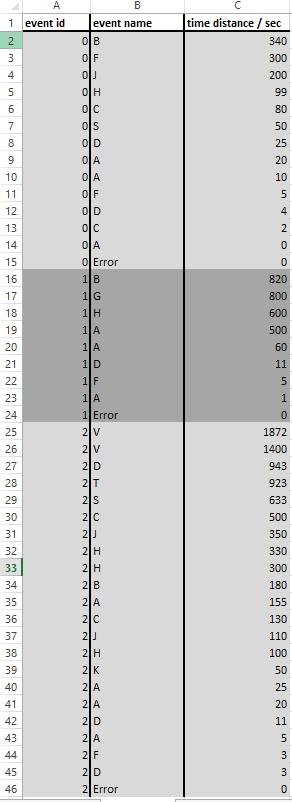
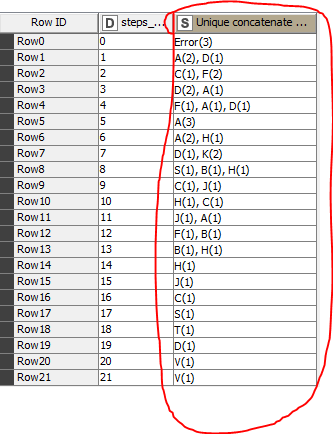
I already built a preparation workflow for my input so my data will be filtered down to 3 columns of “event id”, “event name” and “time distance / sec”, where “event id” is the ID of the corresponding event of the error, “event name” is the name of the event like in the input file and “time distance / sec” is the calculated difference of the timestamps from “error” to every other event happened before. Attached you will find a sample table of the filtered data with the 3 columns.
My idea now is to maybe do a hierarchical clustering so I can see which group/series of events happened every time right before an critical error occurred and therefore which events might be more important to look into and which not.
I hope you guys have an idea of my problem and you might give me a hint how to continue with this. If you have any question for understanding my problem please let me know.
Have a nice day!
Greets,
Tim


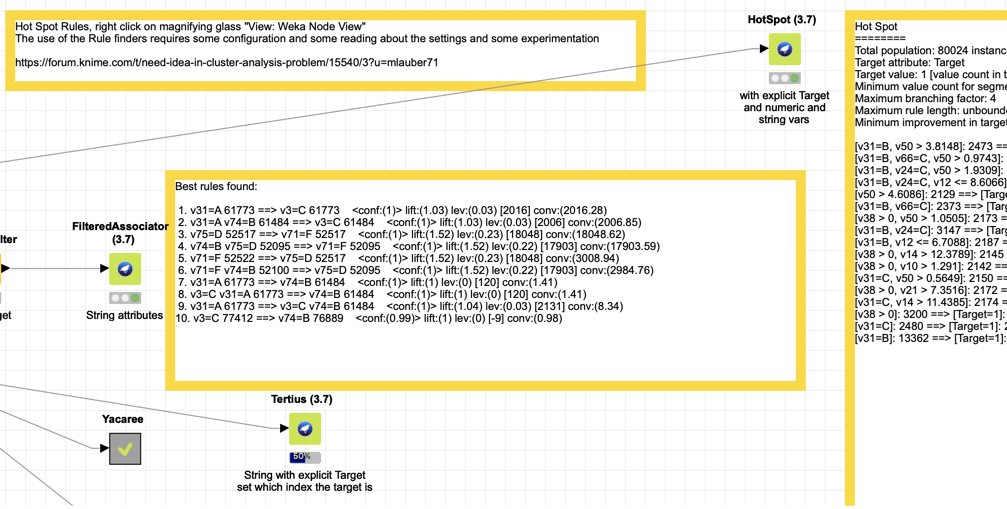
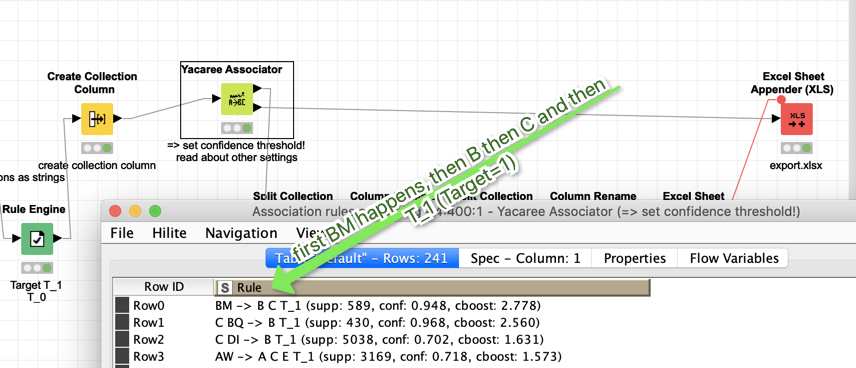
 ) . You have a sample file with multiple (5) events. All events are ending in an error. Every event consists of a sequence of errors (event name) and the time before the “critical” error occurred. Now you want to know which event name(s) is/are responsible for the critical error.
) . You have a sample file with multiple (5) events. All events are ending in an error. Every event consists of a sequence of errors (event name) and the time before the “critical” error occurred. Now you want to know which event name(s) is/are responsible for the critical error. 
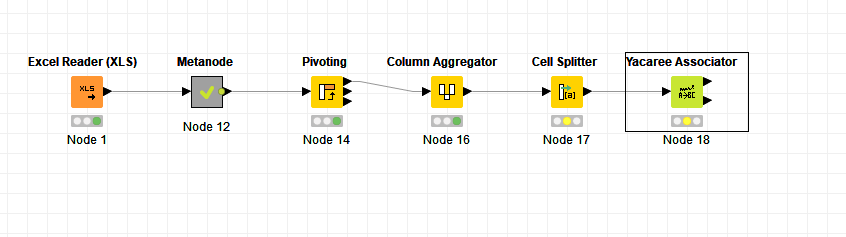
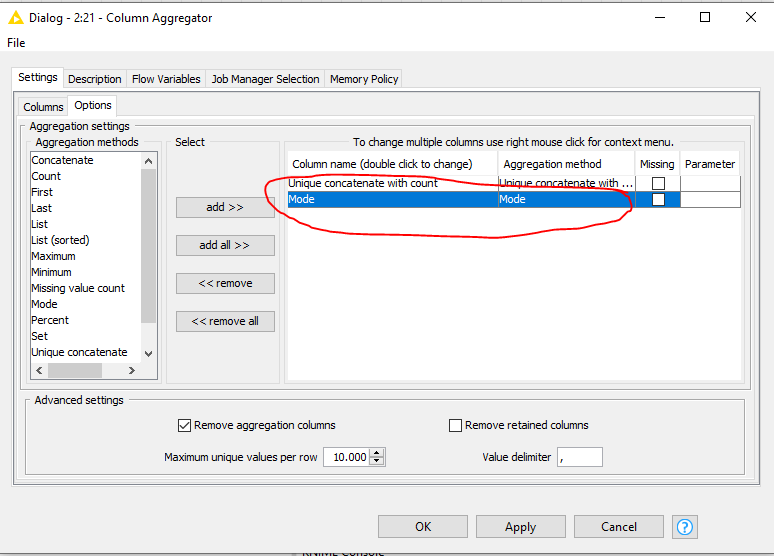
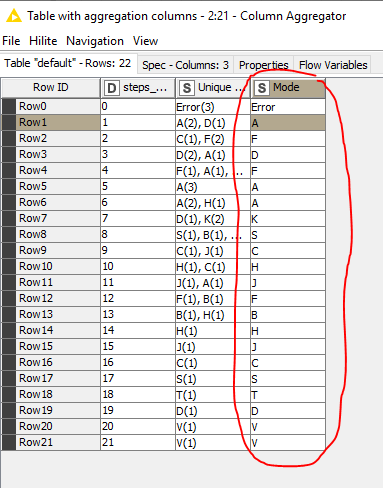
 but more a starting point.
but more a starting point.