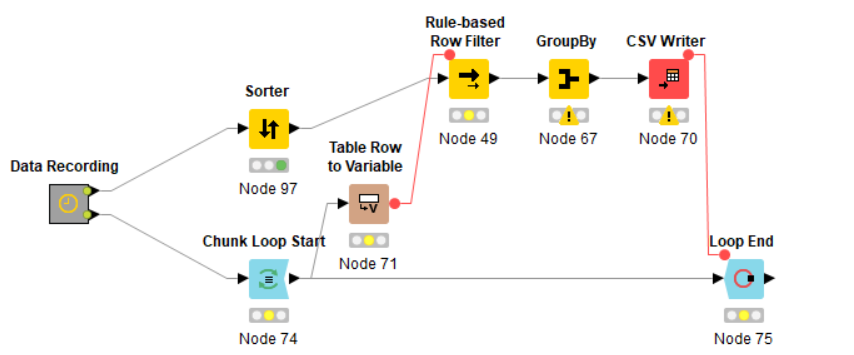
I use a rule-based line filter to filter specific data in a large file. I compare two values from different tables. If they matche, the filtered rows will be aggregated and written to a CSV file.
I repeat this several times within a loop.
However, the rule-based row filter is very slow. Is it possible to use a rule-based row spliter and use the second Output (false rows) as the new input for the rule-based row filter? This would reduce the amount of data after a loop-Iteration.
Date Recording is the date prepreperation of two files. File one (connected with the Sorter node) is having 7,9 mio rows, file two (connected with Chunk Loop Start) 1000 rows.
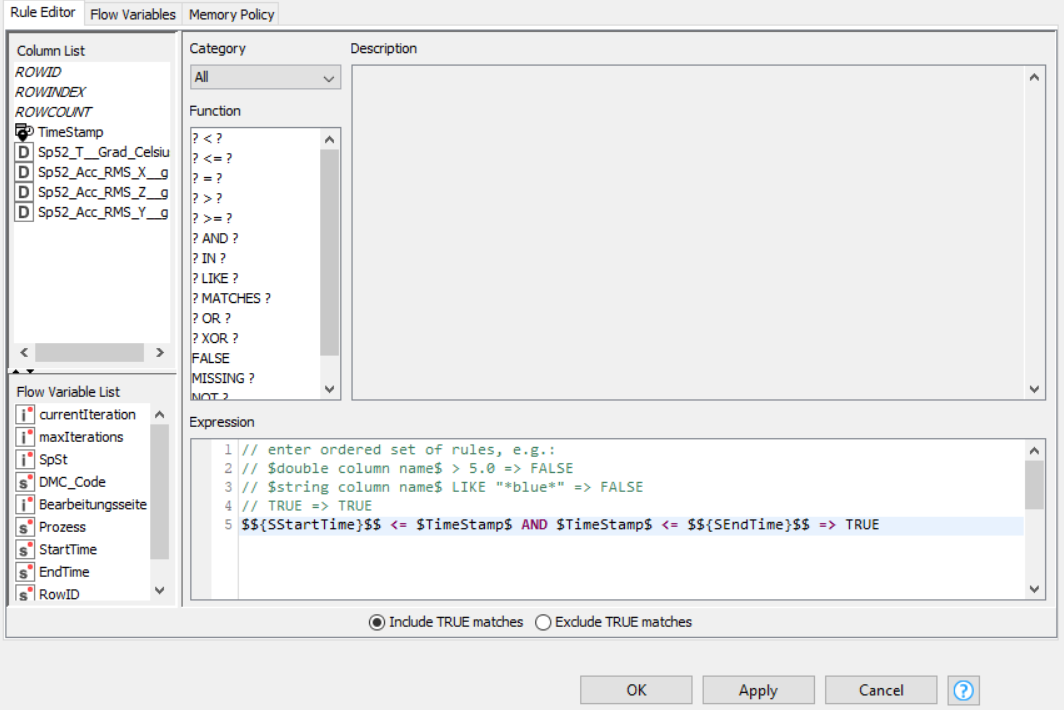
In configured the rule-based row filter as followed:
$${SStartTime}$$ <= $TimeStamp$ AND $TimeStamp$ <= $${SEndTime}$$ => TRUE
Afterwards I aggregate the colomns by the GroupBy node.
I want to speed up the process of filtering. Maybe I can delete all the rows I already aggregated and use the reduced file as a new input for the Rule-based Row Filter? Or do you have a better idea?
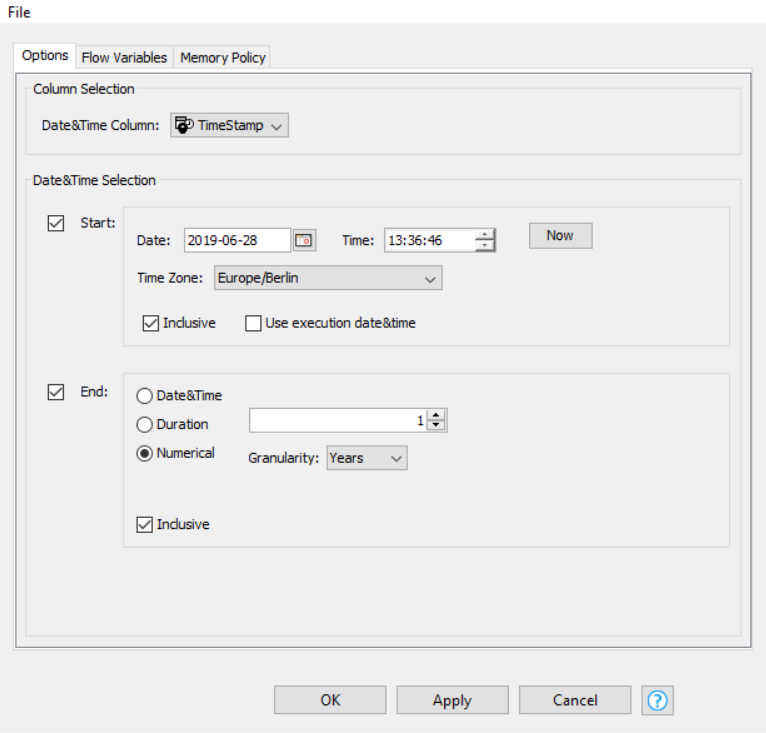
I still use a date and time based row filter to filter my data. I use this filter in a loop with a Table Row To Variable Loop Start, as you previously recommended.
However, the date and time based row filter takes a long time to filter a large amount of data. Once I filtered my data table, I wirte them into a csv file. Afterwords, I dont need the already filtered data anymore. To improve the running time, I like to reduce/update the data-table for the filtered data.
Don’t have to update the data-table in every Iteration, but at least every 50. Is there a way to do this or do you have another idea?
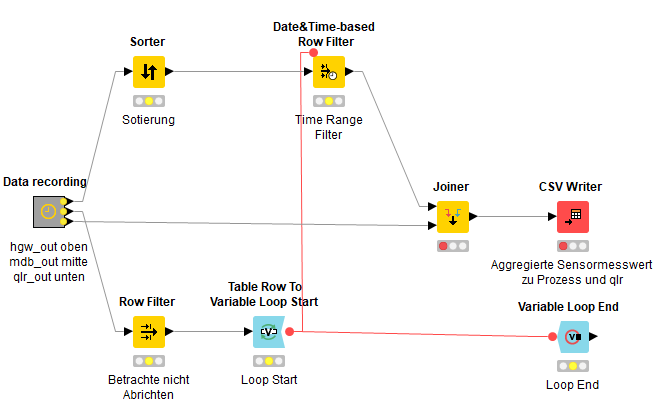
To have only the remaining rows in the next iterations, you can use Recursive Loop.
Use the Recursive Loop Start node after the Sorter node. Use the current iteration number to filter the output of the Row Filter node and convert the output to variable. Split the main table based on dates using Rule-based Row Splitter node. Use Variable to table row after the CSV Writer node and close the loop using the Recursive Loop End node. Pass the second port of the splitter to the second port of the Recursive Loop End node.
If you provide a sample dataset, I would build an example workflow for you.
that would be awesome! Here are the two (smaller) sample datasets.
I used data from the rows “Start and Endtime” to filter the rows in “Testsample 1”. (starttime < timestamp < endtime)
Instead of join the filtered rows with another docuement (as in the screenshot in the last post), you can also aggreagete the filtered values and write it into an csv.