Hello,
I have this web page: https://iri.jrc.ec.europa.eu/scoreboard18.html
On this page, there are 2 xlsx files, which I want KNIME to be able to detect, so that I can use the relevant reader node to download the data.
Thanks,
Kind regards,
Yush
Hello,
I have this web page: https://iri.jrc.ec.europa.eu/scoreboard18.html
On this page, there are 2 xlsx files, which I want KNIME to be able to detect, so that I can use the relevant reader node to download the data.
Thanks,
Kind regards,
Yush
Although I don’t understand exactly what you want; I still wanted to give an idea by guessing. There are many ways. I think the following will give you an idea of what I share.
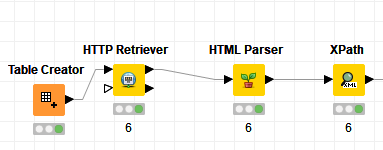
Thanks for your quick response umutcankurt,
Apologies, I should be been more clear. I was looking for something like
input:
https://iri.jrc.ec.europa.eu/scoreboard18.html
I tried to replicate what you suggested, but my href column comes out blank.
Scanning web page for URLs.knwf (13.4 KB)
Hi Yush,
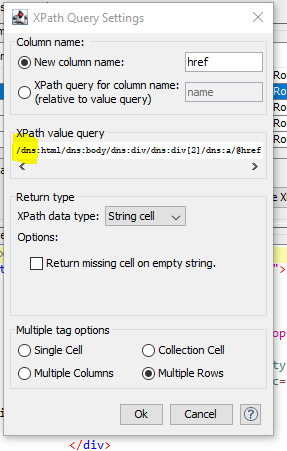
the trick is to get the XPath expression right (this can be a bit fiddly with the XPath node, as it involves some trial-and-error). Anyways, here’s one possible solution:
I’m using the following XPath expression to grab the links to MS Excel files:
//dns:a[dns:img[contains(@class,"xls_icon_mini")]]/@href
Explanation in prose:
Get the href attribute of all <a> tags which contain an <img> tag which has a class attribute which contains xls_icon_mini:
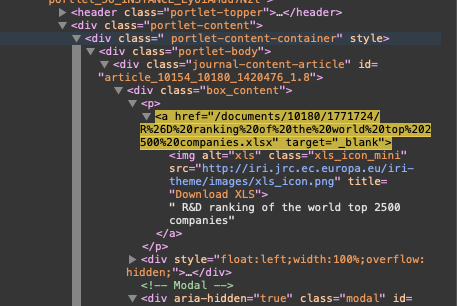
(the dns: prefixes are necessary because XPath is very strict in regards to name spaces and dns: represents the http://www.w3.org/1999/xhtml namespace; see tab “Namespace” in the XPath dialog)
Does this help?
– Philipp
Thanks qqilihq,
This is perfect, I can now loop through multiple pages, and extract all the Excel files from them.
Thanks to umutcankurt also.
Kind regards,
Yush
Sorry to essentially re-open this, but it seems not to work with the 2015 version of this page. Please see workflow.
Scanning web page for URLs.knwf (13.5 KB)
On this page, the structure is slightly different (someone should tell those IRI guys to get a proper CMS). The <img> tag is not within the <a>, so you’ll need to modify your XPath.
For the second case, the XPath would look as follows:
//*[dns:img[contains(@class,"xls_icon_mini")]]/dns:a/@href
In case you want to combine both queries to make them more generic (so that they work on both pages), you should be able to simply combine them with a |:
//dns:a[dns:img[contains(@class,"xls_icon_mini")]]/@href | //*[dns:img[contains(@class,"xls_icon_mini")]]/dns:a/@href
– Philipp
Amazing! Thank you again.
Kind regards,
Yush
Hi @Yush,
Following the great solutions by @umutcankurt and @qqilihq and since @qqilihq has mentioned:
Here I’d like to share this blog post in which it is explained how to easily find the XPath for an item in a webpage:
https://blog.statinfer.com/how-to-get-the-content-of-a-web-page-in-knime/
![]()
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.
