I was wondering if it is possible to use the Excel Sheet Appender and skip if a sheet already exists, not abort the entire workflow. I’m iterating through a number of files and would like to keep up performance so only the new files are added as a new sheet to m output file.
Use the list sheet names node at start of each loop iteration, followed by a row filter to only keep the sheet name you want to test for, and then use an empty table switch / End if combination to process the file of the sheet name did not exist.
Hi Steve,
thanks for your response. I can follow your train of thought until the empty table switch and don’t fully understand how to implement this into my existing workflow.
Connect the output of your loop start node to the input of the Read Excel Sheet Names (Node 49 in your picture)
This is where it gets a bit tricky… because you have your three Excel Reader nodes you need do activate/deactivate the flow variable input to those, which you cant do directly from the Empty table switch - you have two choices…
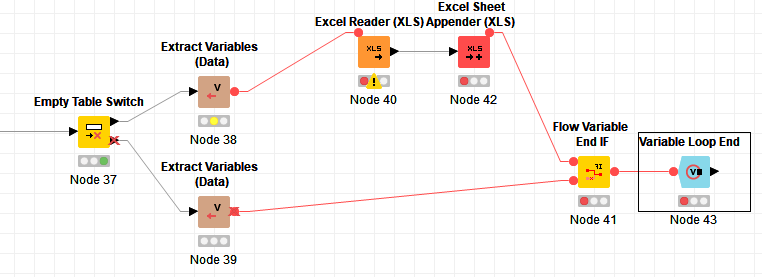
a. Follow them empty table switch with an ‘Extract Variables (Data)’ node on each output, and then take the top output as the input to all your Excel Reader nodes. Collect up the active branches with a Flow Variable End If node (from the Vernalis Community Contribution). I’ve shown a simplified form here - substitute your three Excel Readers and the rest of the loop body for my Excel Reader/Excel Sheet Appender combo:
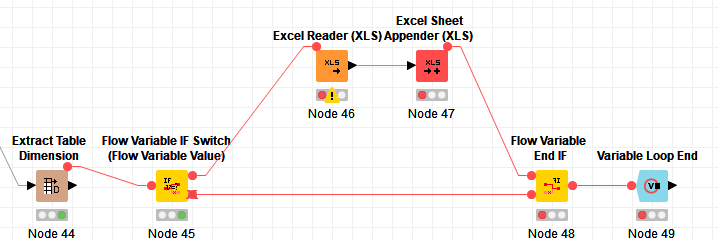
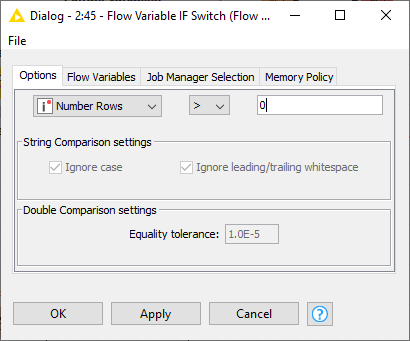
b. Alternatively, replace the empty table switch with an Extract Table Dimensions/Flow Variable If Switch (Flow Variable Value) pair (the latter is again from the Vernalis community contribution):
and configure the if switch to switch based on the number of rows:
Finally, in both cases, I have replaced your Loop End node with a Variable Loop End - the reason for this is that as far as I can see, you dont need the output from the loop end, and also you need to connect the hidden output flow variable port from the excel sheet appender to a node in the loop body (or to the loop end) to ensure it runs in each loop iteration - using the variable loop end does both.
thanks again for your detailed instructions. I built the workflow a) above and while it does not return any errors, I feel like it appends whether it exists or not. Maybe that is due to a fact that I had not mentioned yet.
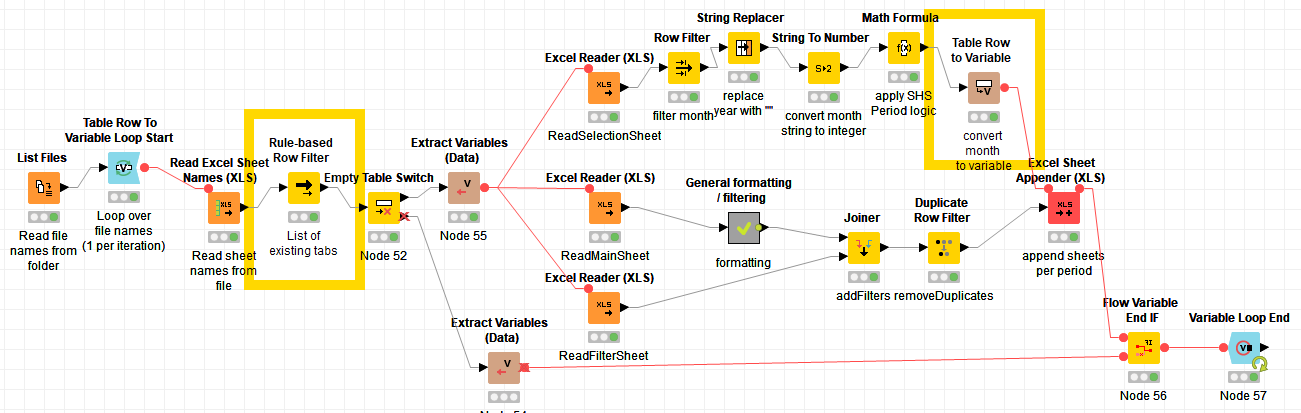
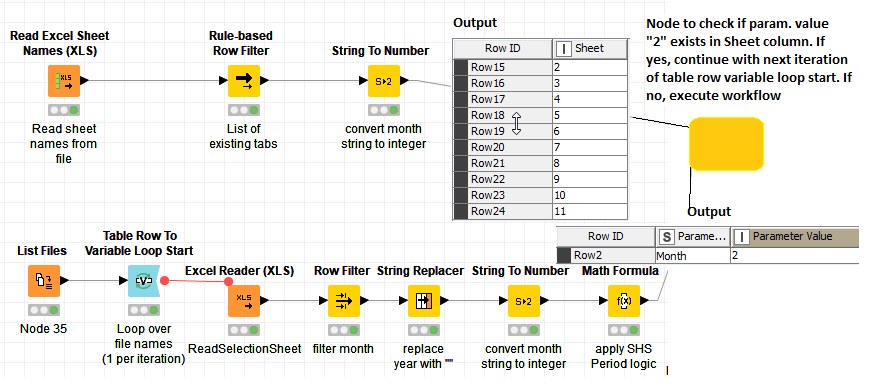
In a Table Row to Variable note (highlighted below) I set the tab name based on a variable from the input file. This tab name should be matched to the Rule-based Row Filter (highlighted below) which returns a list of the already existing tabs that should not be executed. This match is still missing in my opinion. Is there a note that can compare a list with a variable value?
Edit: And then another node would have to tell my table readers to execute only this file. It seems like this is getting quite complex. Unfortunately, I cannot justify the wait time of my current process. It just takes way to long to append all tables with every execution…
Sorry, without looking at your data I really cant think how to solve the rest of the problem - maybe someone else on the forum can supply the missing final piece.
You mention the time it takes to append the tables, but how does this compare with what you have in place at the moment?
I totally understand. I’ve tried to reoganize my project to and made the question more precise. Maybe this could help with the understanding of the issue?
I’m looking for a node switch to check if “2” exists in the top output table. If yes, trigger next iteration. If no, continue with workflow and pass variable from “Table Row to Variable Loop Start” on to the next step.
Hi @Krau5i and welcome to the KNIME community forum,
If I have understand your issue correctly, you have a list of sheets to add and a list of sheets which are already added. Now you want to add the sheets which are not already added. Right?
Why don’t you use Reference Row Filter to exclude the existing sheets from the list?
Thank you for your response. I think the Reference Row Filter helps! I’m missing however the next piece in the puzzle, meaning a node following the reference row filter that checks a condition:
if table is empty, pass previously created variables on to excel reader
if table is not empty, loop through next iteration
Any ideas how to bring these variables back into this flow and where do I need to end the variable loop?
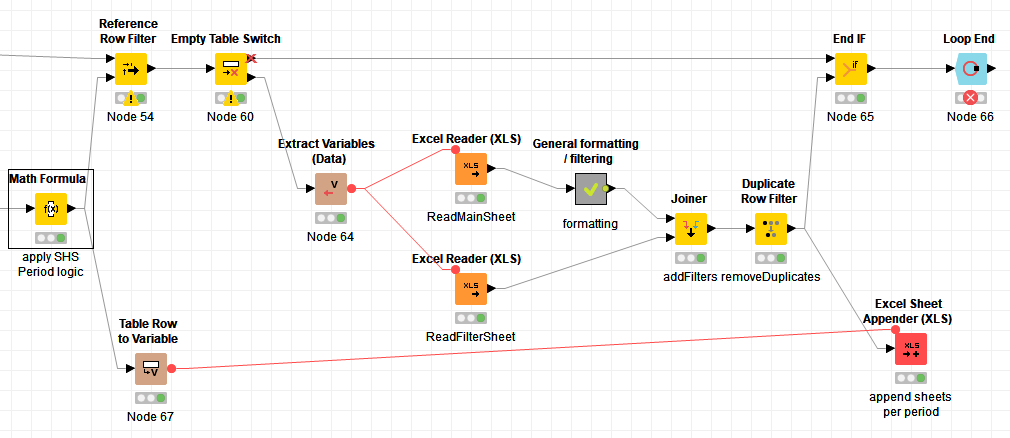
Thank you! I think you guys got me really close to a solution of my workflow. One final issue that remains is a Loop End node error (Node 66):
ERROR Loop End 2:66 Execute failed: Input table’s structure differs from reference (first iteration) table: different column counts 29 vs. 2
The Empty Table Switch (Node 60) if not empty returns 2 columns from Node 54, but if empty runs a whole workflow that creates a table with 29 columns. Is there a neat KNIME solution to this?
I think we all gave you hints rather than a full answer - from which you probably learnt more. All of us on here have been in the same place when we started out with KNIME - it gets easier as you figure ways to do things. (Actually, you will probably realise that different people will give you different answers sometimes to achieve the same thing!) And for me at least, one of the great things about KNIME is that you can ‘just fiddle’ about with your data until you get it how you want it.