Dear Fellow KNIME Community Members,
Thanks for generating my interest in such a wonderful tool I am searching since last 2 hours to see if there is a solution of my problem went through many posts in order to see if the solution I require exists or not. My case is somewhat different, below is an explanation of my case and the required output.
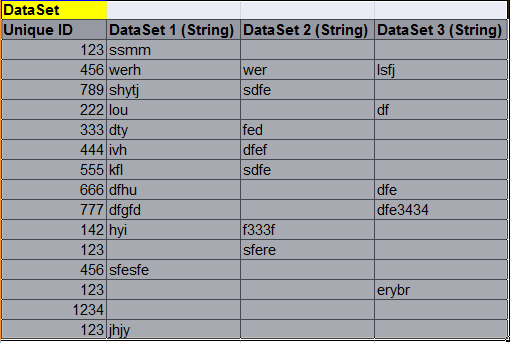
I am working with 10 to 12 different data files somewhat the data look like in the example below;
|Unique ID|DataSet 1 (String)|DataSet 2 (String)|DataSet 3 (String)|
|Unique ID |DataSet 1 (String) |DataSet 2 (String) |DataSet 3 (String)|
|123 |ssmm | | |
|456 |werh |wer |lsfj |
|789 |shytj |sdfe | |
|222 |lou | |df |
|333 |dty |fed | |
|444 |ivh |dfef | |
|555 |kfl |sdfe | |
|666 |dfhu | |dfe |
|777 |dfgfd | |dfe3434 |
|142 |hyi |f333f | |
|123 | |sfere | |
|456 |sfesfe | | |
|123 | | |erybr |
|1234 | | | |
There are four columns above I am removing duplicates by the unique ID as my primary key its not an issue but these Ids are repeating, I can remove the Ids which has no data by Missing Values in all the 3 columns.
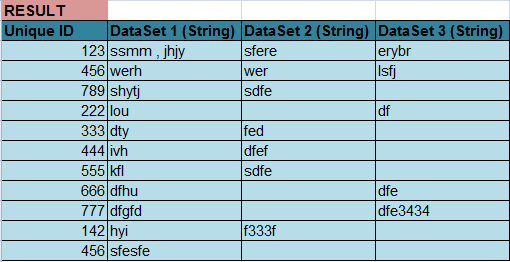
Scenario 1: What if I have String Data in 1 columns and remaining two are BLANK as I have mentioned above in my dataset. I want the result like this ;
|Unique ID |DataSet 1 (String) |DataSet 2 (String) |DataSet 3 (String)|
|123 |ssmm | | | (Same Result)
Scenario 2: Is there an operator where we can define a RULE to check the Specified columns for the data and if there is that It should consider the WHOLE ROW in the OUTPUT with Blank columns remaining blank and data in the column as it is.
So can I achieve it by using any RULE where it should say if the row has all 3 columns blank remove that whole row and if it has value in one row keep it and same and concatenate if the same id is repeated with the unique text. Minimalistic solution will be highly appreciated.
Your help in this regard will be highly appreciated.
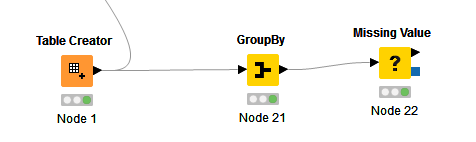
Please find the example in the excel sheet to better understand it as well. Excel SHeet Attached
example data set and output.xlsx (9.8 KB)
Kind Regards
Bilal