strip(regexReplace($Text$,”(.)\n(.)“,”" ))
Hi @rvissers,
sorry I´m late to the thread but I´m currently working with PDF´s as well and what I found that extracting tables with knime from a PDF works sometimes, when all PDF´s are the same structure. What I`m facing is around 9000 PDF´s with the same information on them, but in a lot of different formats.
I got quite good results with aws textract. I´m calling it within KNIME in a python note and prase the answer with GitHub - aws-samples/amazon-textract-response-parser: Parse JSON response of Amazon Textract
You also can use the api for queries to ask questions like “What is the signing date?” in natural language and get an answer.
I`m not an aws fanboy but I think it is quite a cool service and if you are not completely bond to use exclusively KNIME a easy way to achieve your task.
If your are interested I could share a workflow.
Kind regards,
Paul
1 Like
@goodvirus , the aws textract will probably upload the pdf to the cloud or at least the content?
@rvissers: Yes, you can upload the file or just the bytes, but it will end up in the cloud.
would be interested in shared flow.
br
Hi @Daniel_Weikert,
here is my workflow.
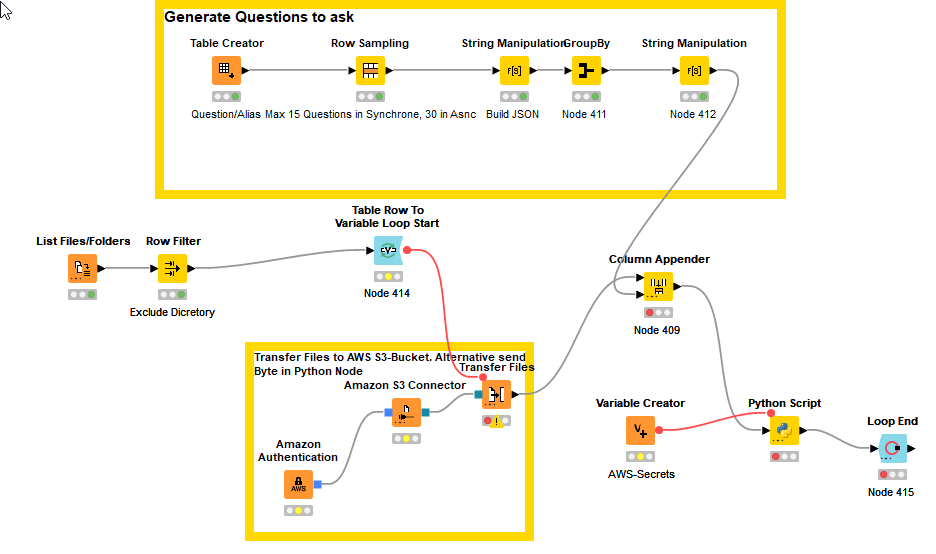
AWS_Textract_Synchrone_Call.knwf (923.9 KB)
Currently it works with asking questions from the pdf (and only if is one page), but can easily be modified to work on multiple pages and to just to extract tables and forms.
There is also an asynchrone option to double the queries and improve the overall performance.
If you have any questions…
Kind regards,
Paul
2 Likes
Thanks for sharing. What’s the performance?
Have you tried free alternatives as well?
br and enjoy your weekend
I have tried the free alternatives before, but the performance in key-values pairs and table extraction was not satisfactory.
For my use case I have single page pdf data with forms and tables, which are filled out by hand. The forms differ because every vendor has a different one, but the information stay´s the same.
We did a test for 200 documents and the accuracy was around 91% (extraction of the relevant information). We compared this to manuell extraction by a non expert and got around 94% accuracy. After this we looked into the process and modified the workflow to include an human interaction loop when the confidence score was under 85%. Then we redid the test and went up to 93 % accuracy.
This was good enough for our use case. One problem with textract is, that you can’t learn certain forms or tables, because textract lags this function.
can you separate the tables (pdfs) to then send those you know textract misses to another ocr tool?
you probably cannot provide an anonomous sample right?
br
Hi @Daniel_Weikert,
I could, but the accuracy is good enough for our use case ![]()
I can’t upload PDF´s here, so here is a bad “pdf”:
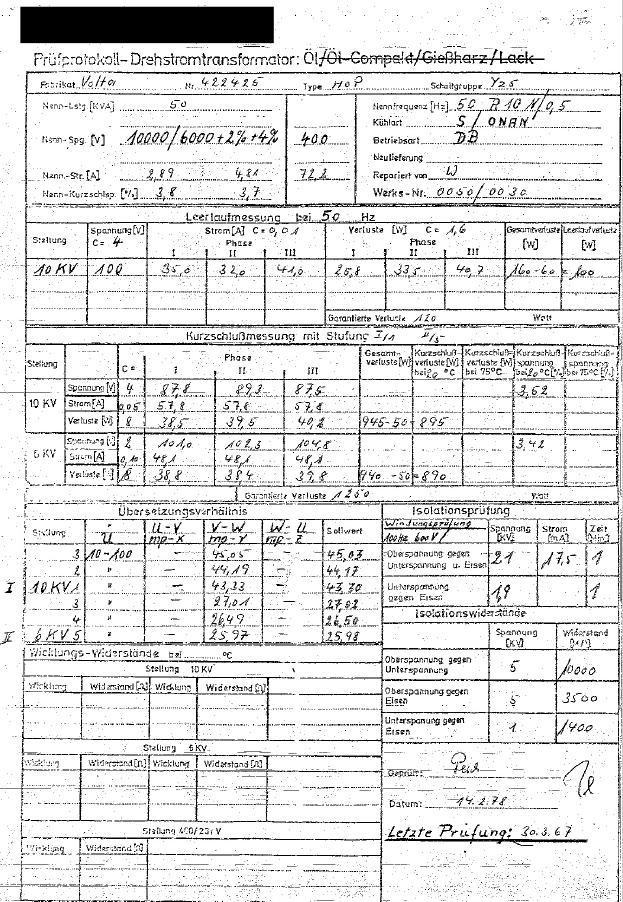
The problem here is in the table “Übersetzungsverhältnis” there a some misinterpretations.
Here is a good one, that works just fine:
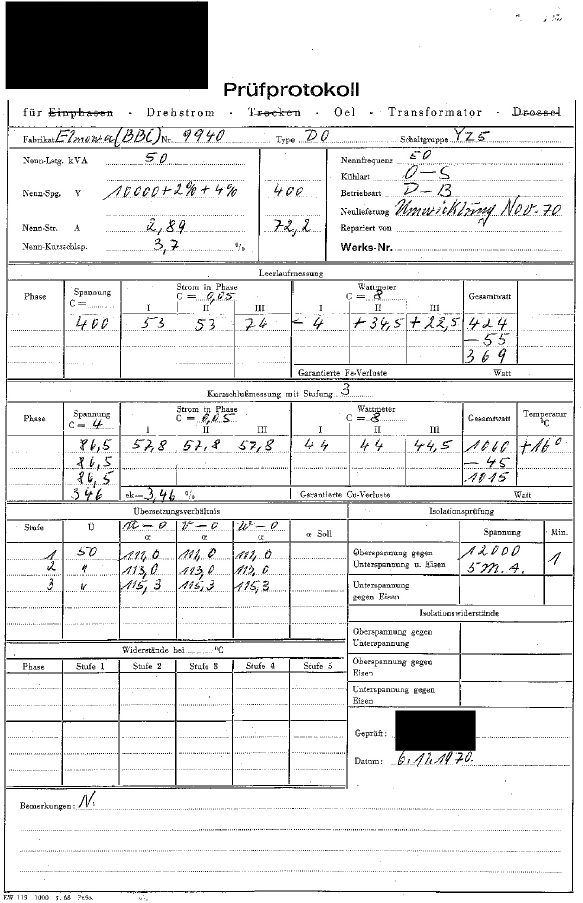
I can just say, that for a non custom trained solution it works quite good with hand written text and tables.
Kind regards,
Paul
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.