Hi @JanDuo,
Thank you for your help.I would like to ask you if feature selection node and correlation node and filter work in the same way?They filter out the most correlated feature.
Thank you.
Hi @JanDuo,
Thank you for your help.I would like to ask you if feature selection node and correlation node and filter work in the same way?They filter out the most correlated feature.
Thank you.
Hi @Nandisha
Where did you get the idea that feature selection filters correlated features? Please read the description of the Feature Selection Loop Start (1:1) to see how it works.
Hi @JanDuo,
Thank you for your message.I would like to ask you if there is a simple example of the elbow method.
Thank you.
Hi @JanDuo,
Is it normal that the feature loop selection takes a very long time to be executed?Is there a way I can make it faster?
Thank you
Hi Nandisha
The more features you have the more combinations have to be explored to find the best one. This can take quite some time.
What this all means is you have to make your own decision what you want to achieve. Is getting the utmost out of a model important, it will mean you have to put a lot of resources into it, to find this model.
If your aim is a little bit less, you don’t have to do all these optimization steps and loops and find a model which performs well, maybe even good, much faster.
You can’t have both, or as the English would say: you can’t have your cake and eat it.
Standard forward/backward/stepwise feature selection methods are computationally expensive and therefore slow - it’s just the nature of the beast. There are simple things you can do ahead of that to hopefully reduce your feature space though - for example, filtering highly correlated variables first.
You might want to check out this blog post (and associated workflow) from earlier this year:
Hi ScottF,
Thank you for your suggestion.That was very helpful.
Regards,
Nandisha
I have one more question.Should I do parameter optimization first or feature selection?
Thank you.
Feature selection. Should reduce the duration
Thank you for your reply Daniel.What exactly do you mean it should reduce the duration?
If I choose any iteration and number of neurons values,the feature will be same ,right?
Hi,
I have a question concerning feature selection.When I am doing feature loop selection,it is selecting different features when I am changing the parameters.As you have suggested,I would do feature selection first and then parameter selection.Can you please suggest why it is changing for different parameters?How should I make it stable?
Thank you in advance.
Kind regards
If you start the parameter optimization after the feature selection it should not change. What I meant at the beginning is that when you reduce the amount of features first then the optimization might require less time
BR
Hi Daniel,
Thank you for your message.I will do it like this.I would also like to ask you how to find the value of K when doing clustering?Do you have a simple workflow for that?
Thank you in advance.
Kind regards,
Nandisha
Normally you could try different Ks then plot them and have a look at the “elbow”
BR
Ok Thank you.I will try it.
When I am using feature loop selection for ANN,I am having different features for different parameters.For example if I change the maximum number of iterations then the features are also different.I am getting different results.How should I proceed with this?I will do parameter optimization after that.
Kind regards
Kind regards
I’ve repeatedly written this in the past. The feature selection loops are a waste of time. Often they are not used correctly like random splits and no cross-validation (like in your screenshots) and the computational needs are prohibitive while the whole process is borderline p-hacking, eg. you are mindlessly checking gazillion combinations to see if one magically leads to a better model. Parameter optimization goes in the same direction.
The MLP learner also is pretty much pointless really. My suggestions is to eliminate correlated and low variance/constant features and use a tree-based algorithm like Random Forest or xgboost. Tree-bases algorithms can deal with useless features, they ignore them (correlated ones however are an issue and extensive usage of categorical data, eg. one-hot encodings).
Once you have the basics down, you can think about neural networks. But basic DNN (fully-connected layers) usually simply fare worse than tree based methods and in any case don’t even think about it if you don’t have a lot of data where a lot is at the very least several thousand data points.
Thank you for the information.How will I know which feature will best contribute for the prediction and how will I choose the parameters for ANN?You mean to say that the MLP learner is not accurate?
I want to make prediction and I have about 20 variables.What is the best means for me to do so?
KR
Why do you want to use ANN? See I think what is best for you would be to learn the basics. Why? Because if your main interested is variable importance, the way to go is linear/logistic regression and for sure not ANNs.
Thank you for your advice.I thought ANN might give better values but it is quite complicated as I have to choose the parameters correctly.
Also,I would like to ask you how can I find the K-means clustering and finding the optimal value of K workflow.I have different suggestion about using elbow method and Silhouette Coefficient.
Thank you in advance
Hello,
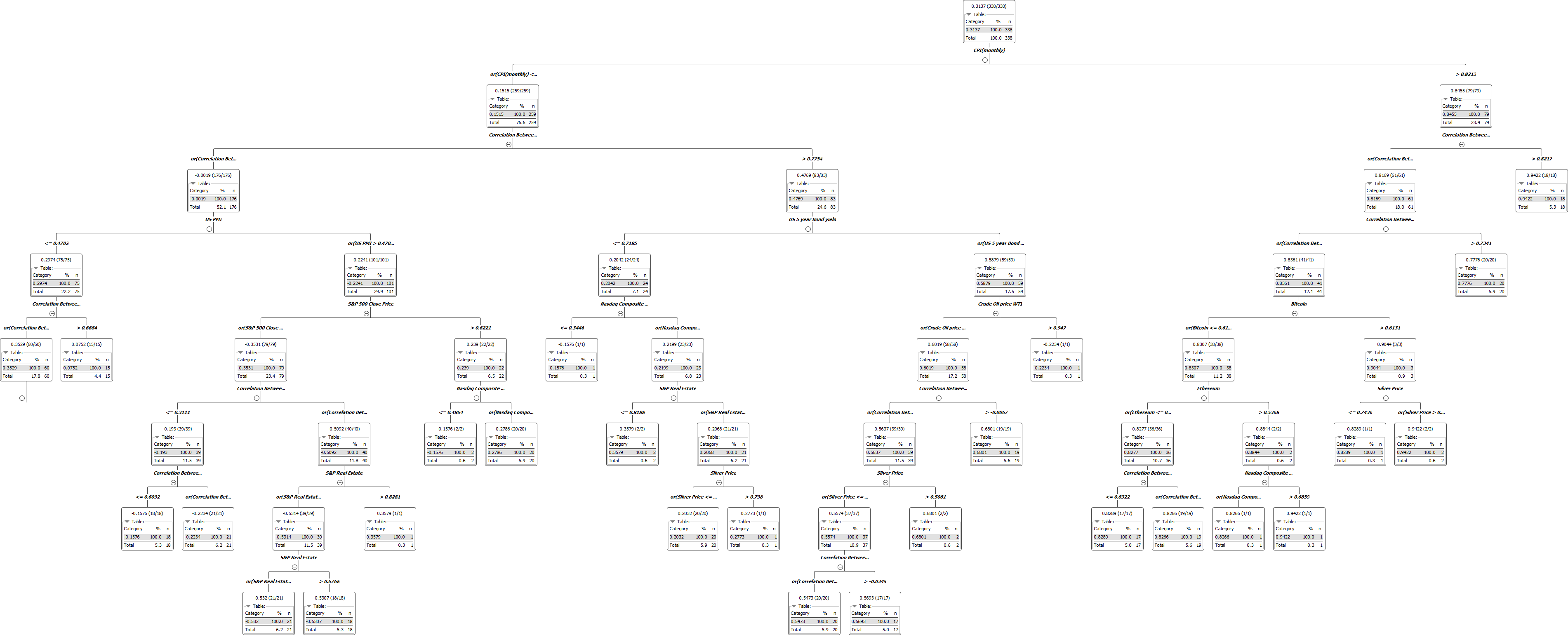
I have a question regarding decision tree.I want to predict the correlations between two asset classes given some variables.Do you think a decision tree is useful to do the prediction?I tried it but I do not know how to interpret the results exactly.I am attaching the results,please let me have an idea how it works.
Thank you & Kind regards