Dear Knimers,
Suppose I have a table with 10 million rows of “XY - data”:
…and let’s say I want to remove the edges, rows x<100.0 and X > 999900.0. I could use a row filter:
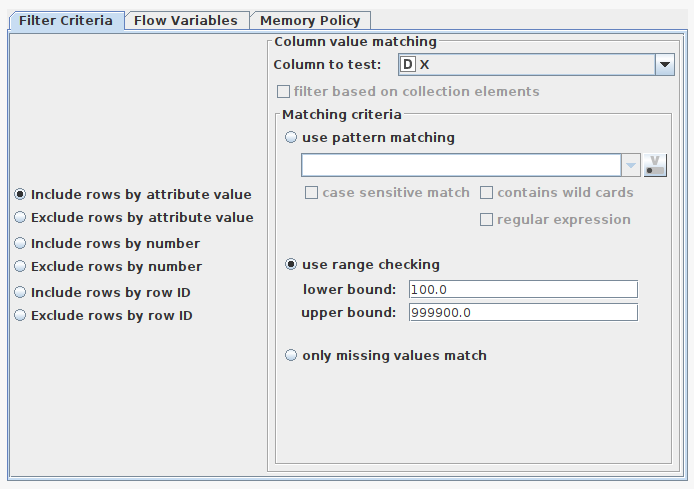
This takes 16.1 seconds on my computer.
I can do the same thing using a Rule-based Row Filter (19.2 seconds) and a Java Snippet Row Filter (27.8 seconds).
I could also combine all the rows into a pair of lists:

In that case I could slice the data using a Java Snippet:
int l = c_X.length;
int num = 0;
for(int t=0; t<l; t++) {
num += ((c_X[t] >= 100.0) && (c_X[t] <= 999900.0)) ? 1 : 0;
}
Double[] Xresult = new Double[num];
Double[] Yresult = new Double[num];
int u = 0;
for(int t=0; t<l; t++) {
if ((c_X[t] >= 100.0) && (c_X[t] <= 999900.0)) {
Xresult[u] = c_X[t];
Yresult[u] = c_Y[t];
u++;
}
}
out_X = Xresult;
out_Y = Yresult;
Significantly faster: 5.7 seconds. The risk with this method is that it is very easy to slice the two lists differently by mistake, so that the user ends up with two inconsistent lists without noticing. I tried to avoid that by making a list of XY pairs, but I did not succeed into using such a list in a Java snippet (unsupported column type).
Now, let’s try the same slice within pure Python with a Pandas dataframe. This only takes 0.5 seconds:
tm1 = time.time()
df = df[(df['X']>=100.0) & (df['X']<=999900.0)]
tm2 = time.time()
print(tm2-tm1)
Using the exact same Python code in a Python Script node in Knime takes 152 seconds.
Changing to the new columnar table backend changes the execution times a bit, but not spectacularly:
Row filter: 13.5 s
Rule-based row filter: 12.5 s
Java snippet Row Filter: 22.0 s
Using a pair of lists and a Java Snippet: 9.8 s
Using a Python Script node: 156 s
Interestingly, using a pair of Lists has become significantly worse.
Knime 4.3.3 on Ubuntu 20.04, Intel i7-10710U (12) @ 2.000GHz, 64 GB RAM, -Xmx24576m, -Dorg.knime.container.cellsinmemory=25000000
Cheers
Aswin
