I got some 400 input data from a tennis court’s booking system. I have a hypothesis that the closer to the booking time they reserve/book the court, the more likely they are to cancel the booking.
I have 4 variables:
1 “the time&date the booking was made”,
2 “the time&date the booking was made for”
3 “the time&date the cancellation was made/logged”
4 “the reason for the cancelation”
I started out calculating time between the reservation date&time and the cancel date&time
But i am stuck on how to approach this hypothesis, I was thinking about using linear regression, but is this even the best way to approach this?
I hope some of you can give me some guidance on how to confirm or invalidate the hypothesis.
Thank you in advance. Have a great day!
BONUS QUESTION: Can i look at the reason for the cancellation in correlation to the other information i got?
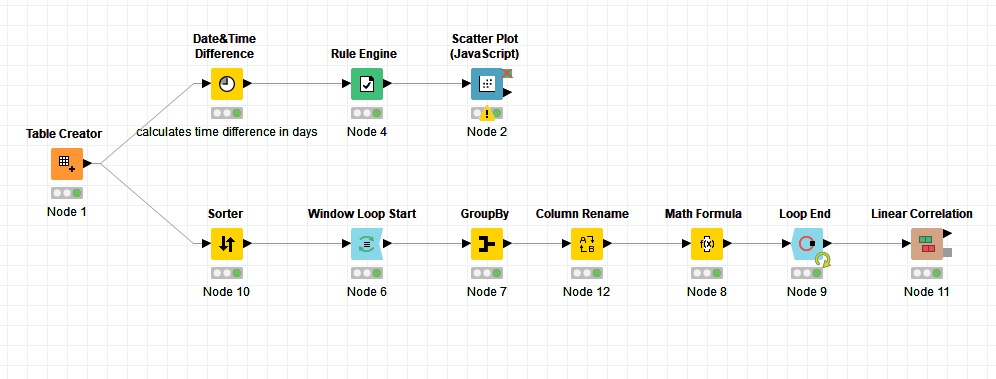
First of all, do you have both cases where a booking is canceled and not canceled? Because I think that’s necessary to prove your hypothesis. If yes, then you have missing values in your column related to the cancelation time(3). By using a Rule Engine node, you can create a new column which has 2 values (yes or no for example) based on this date&time column. “yes” means the booking was canceled, “no” means it wasn’t canceled. Then you have to calculate the difference between the booking time and the event time (1 and 2) by using a Date&Time Difference node and let the output format be in days or hours for example.
Now to show density of cancelation incidents in a timeline, you can use Scatter Plot (JavaScript). Assign the time difference column to the x axis and the cancelation incidents to the y axis. Now you can see if the number of cancelation incidents is increasing or not when the time difference gets closer to zero.
But there is a critical issue here. If the number of booking incidents is increasing in general by getting closer to the event then maybe both “yes” and “no” incidents are increasing together and it’s hard to say if one of them is increasing faster than the other one by just looking at the plot. So, I suggest that you aggregate the incidents in time periods (days or weeks or months for example) and count both cases where a reservation was canceled or wasn’t. Then calculate the correlation between each of them and the time. Now by comparing these values, you can say if the number of cancelation incidents is increasing faster or not. For example, if the correlation between the canceled instances and the time is 0.33 and the correlation between not canceled instances and the time is -0.03 then your hypothesis is confirmed.
To do this you can use a GroupBy node after a Window Loop Start node and after finishing the loop use a Linear Correlation node.
Here is an example workflow for you:
I can see that I get a result close to -1 in the cancelled instances, I would say that this means a good correlation, but according to your results, should I take this as a bad correlation? Would you say that this confirms og rejects our hypothesis?
If you are using the same workflow I have uploaded then yes, it means by getting closer to the event time, the canceled instances are decreasing.
Having this negative correlation, it should be easy to observe the same thing in a scatter plot.
I just updated workflow so now we have all the instances as well in correlation matrix.
Thanks again! We are, however, still confused about the results… Our hypothesis is that the closer to the booking time they reserve/book the court, the more likely they are to cancel the booking.
In order to confirm that shouldn’t the number of cancelation incidents be increasing when the time difference gets closer to zero?
In our case, as you also write: when getting closer to the event time, the canceled instances are decreasing. - doesn’t that mean that our hypothesis is not confirmed since there are less instances the closer vi get to the event time?
Having canceled instances decreased does not necessarily mean that your hypothesis is rejected since maybe the number of booking instances is decreasing as well. So you have to compare the correlation of both canceled instances and not canceled instances with time.
The correlation matrix that you have provided means when time passes (get closer to the event), the canceled instances decrease.
Exactly! In the workflow I provided, each iteration is one month long and the first iteration has the most time difference while the last iteration has the least time difference. So from the first iteration to the last iteration the time difference is decreasing. Now as you have negative correlation between canceled instances and the iteration number and positive correlation between iteration and the not canceled ones, it means the canceled instances are decreasing with time while not canceled ones are increasing.
However this was the first idea which came to my mind. There has to be a better method to measure the correlation precisely. Is it possible for you to provide your dataset or a sample here?
we can’t provide the whole set here but here is a 10% sample.
PS: we found an error in our own flow because we forget to remove walks-in from the dataset - meaning that our first correlation results where not true since a walk-in cannot cancel a reservation. but after we fixed this our results still looked strange to us?, with canceled-iteration = -0.95 and not canceled-iteration = -0.803.
In my workflow, I input the same event date and time for all instances. As I see you have different events in different dates.
Let me work on it and I will get back to you soon.
I calculated the time difference and then divided the rows into 10 bins with equal frequency. Also I took the midpoints as the label for each bin. then based on bins, I counted the number of canceled and not canceled instances. Finally the correlation matrix shows positive correlation between time difference and canceled instances and negative correlation between time difference and not canceled instances which means your hypothesis is rejected.
When time difference lowers (get close to zero) the canceled instances decrease as well.
Thank you so much for all your help and guidance. It is much appreciated and we learned a lot. Besides making use of your method we also made a chi^2 test that we think can support the same conclusion, depended on how we define the following: here we dicided to divide all the bookings into what we decide as “long before the visit day” and close to the visit day" and then cross it with canceled yes/no.
Long: 52% not canceled 3.7 % canceled
Short 36% not canceled 7.6 % canceled
probability: 3.48E-26
Hi @armingrudd
I have one, hopefully final question to your method.
you are binning the 500 rows into 10 bins and as you mentions gets a strong negativ and positive correlation.
in our full set we have around 3500 rows and when binning these into bins we tried several different number of bins and our results are very different. When trying different binning the results where as following:
Different number of bins obviously affect the outcome. and my question to you is: how do you/we justify the number of chosen bins? there seems to be many different rule-systems for choosing. What would be the sensible answer when asked why we choose the number of bins that showed the best correlation or vise versa. if we view this critically…
If this type of question is not up you alley I fully understand, just wanted to try
PS. just to be totally clear
a Positive correlation between Time difference and Cancelled bookings shows that when times closes in to zero the cancelations decreases? (since the positive correlation show that time and number of cancellation follows one another)
A negative correlation between Time difference and not Cancelled shows us that there are more bookings as we get closer to 0 and less as times goes on? (since the negative correlation show that time and not cancelled, increases while the other decreases and vice versa)
Yes, since the number of instances and the midpoints are changing.
A balance between number of instances in each bin and the time. However any number you take, the results will show the same notion. As you see, in all examples of yours the canceled-time diff correlation is positive and not canceled-time diff correlation is negative.
Right.
Wrong if “bookings” = canceled bookings + not canceled bookings. Right if you meant “not canceled” bookings. The number of Bookings is the sum of canceled and not canceled instances. With the configurations set in the workflow, there are the same number of instances in each bin. So it’s not the number of bookings, it’s the number of not canceled instances. The negative correlation here means when the time difference decreases, the number of not canceled instances increases.
 Have a great day!
Have a great day!