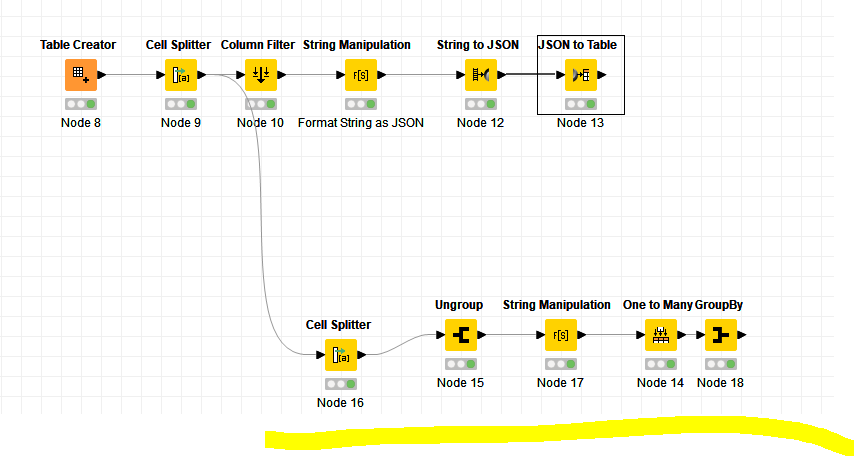
Thanks Bruno,
that sounds good, unfortunately, I don’t know the values before. Here is an actual example. There might be new values I don’t know before I see them. Its for an employee alerting system!
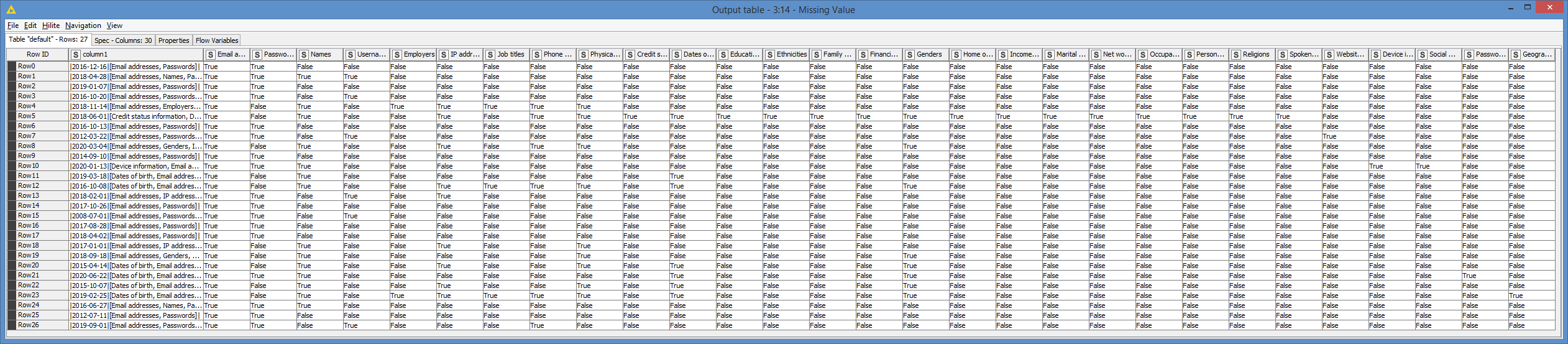
Below is example of actual data
|2016-12-16|[Email addresses, Passwords]|
|2018-04-28|[Email addresses, Names, Passwords, Usernames]|
|2019-01-07|[Email addresses, Passwords]|
|2016-10-20|[Email addresses, Passwords, Usernames]|
|2018-11-14|[Email addresses, Employers, IP addresses, Job titles, Names, Phone numbers, Physical addresses]|
|2018-06-01|[Credit status information, Dates of birth, Education levels, Email addresses, Ethnicities, Family structure, Financial investments, Genders, Home ownership statuses, Income levels, IP addresses, Marital statuses, Names, Net worths, Occupations, Personal interests, Phone numbers, Physical addresses, Religions, Spoken languages]|
|2016-10-13|[Email addresses, Passwords]|
|2012-03-22|[Email addresses, Passwords, Usernames, Website activity]|
|2020-03-04|[Email addresses, Genders, IP addresses, Names, Phone numbers, Physical addresses]|
|2014-09-10|[Email addresses, Passwords]|
|2020-01-13|[Device information, Email addresses, Names, Passwords, Social media profiles]|
|2019-03-18|[Dates of birth, Email addresses, Names]|
|2016-10-08|[Dates of birth, Email addresses, Genders, IP addresses, Job titles, Names, Phone numbers, Physical addresses]|
|2018-02-01|[Email addresses, IP addresses, Passwords, Usernames]|
|2017-10-26|[Email addresses, Passwords]|
|2008-07-01|[Email addresses, Passwords, Usernames]|
|2017-08-28|[Email addresses, Passwords]|
|2018-04-02|[Email addresses, Passwords]|
|2017-01-01|[Email addresses, IP addresses, Names, Physical addresses]|
|2018-09-18|[Email addresses, Genders, Names, Physical addresses]|
|2015-04-14|[Dates of birth, Email addresses, Genders, IP addresses, Names, Physical addresses]|
|2020-06-22|[Dates of birth, Email addresses, Genders, Names, Password strengths, Passwords]|
|2015-10-07|[Dates of birth, Email addresses, Genders, IP addresses, Names, Physical addresses]|
|2019-02-25|[Dates of birth, Email addresses, Employers, Genders, Geographic locations, IP addresses, Job titles, Names, Phone numbers, Physical addresses]|
|2016-06-27|[Email addresses, Names, Passwords]|
|2012-07-11|[Email addresses, Passwords]|
|2019-09-01|[Email addresses, Passwords, Phone numbers, Usernames]|
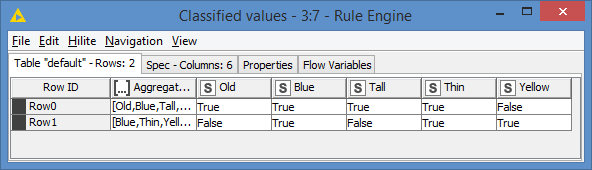



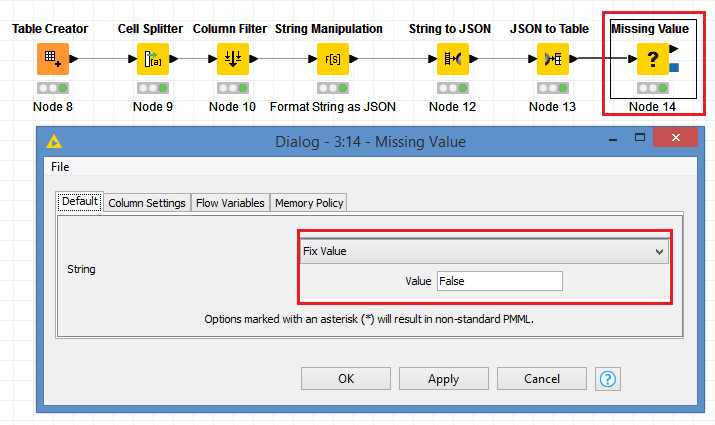

 To close the loop, yes there was no value just true or false.
To close the loop, yes there was no value just true or false.