Dear Community
I have two tables of an accounting system, the one subsystem table is “FI”, the other one is “CO”.
Both tables theoretically show the same information, but in practice there are differences in units and amounts respectively. So this workflow is for a reconciliation of the differences by material with regard to units and amounts.
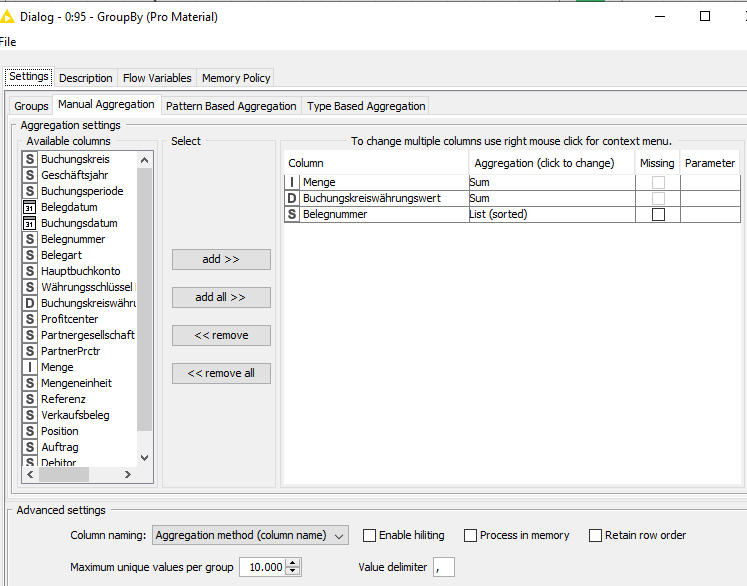
Both tables I have grouped by material and combined them with a full outer join (by material). In the group node I have calculated the sum of units by material, the sum of amounts by material and as additional useful information for the user of the workflow the (sorted) list of the accounting document numbers concerned (FI and CO have different logic of accounting document numbers). I.e. one of the group by node:
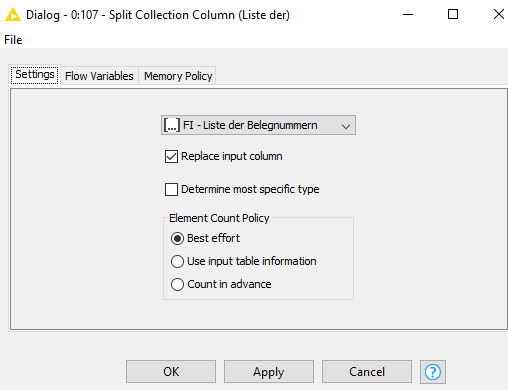
In order to be able to write the results in an excel I have to split the list of document numbers with split collection column and aggregate them by column aggregator
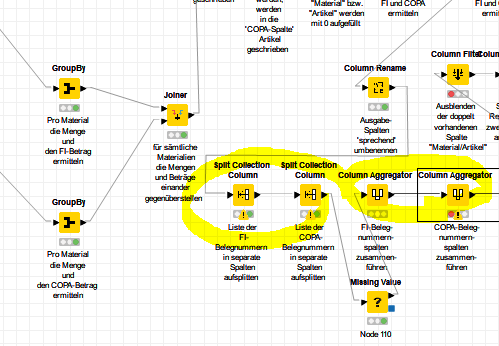
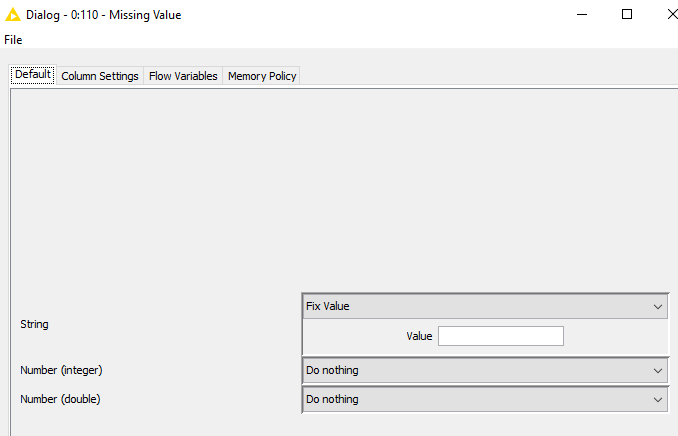
The issue is that the one material has one document number, another one has i.e. 7 oder 19 document numbers concerned. So I have filled the ‘?’ by ‘nothing’ with missing value,
but nevertheless I get lots of delimiters in the output excel file:
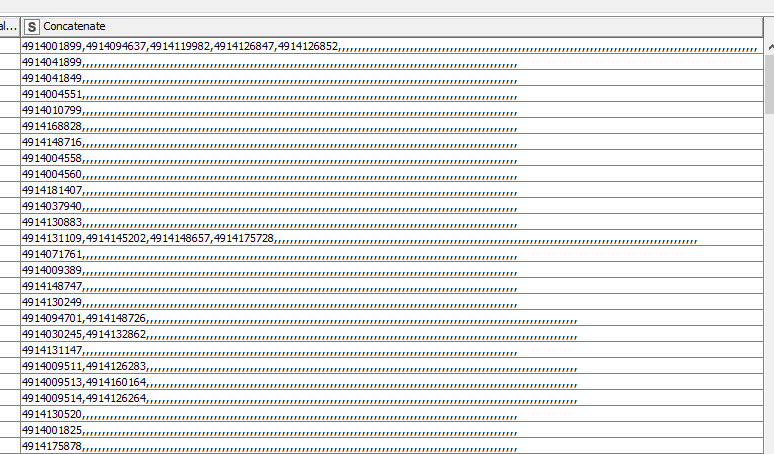
I am not able to ‘delete’ the ‘empty’ columns per row.
This does not look nice; I would like to have the list in the concatenate column with delimiter commas just between document numbers, but no delimiter after the last doc number per row.
Does anyone has a (‘dynamic’ per row) solution for me?
Thanks a lot and best regards

 !
!