Hi @Daniel_Weikert , is that using the Palladian Regex Extractor?
OK, yes. Nice regex and great idea. Building on that… what if we find a way to capitalize the “words” prior to the regex? I just discovered that String Manipulation’s capitalize function allows specification of a delimiter:
capitalize($$CURRENTCOLUMN$$,"-")
Then we apply your Regex, but modified slightly so we also take the leading hyphen along for the ride too.
^\w{2}|-\w{2}
(I got a bit lost using the extractor to split to rows, when I had more than one row as input data, as I then had a group of rows with no obvious (to me) way of assembling them back into their original row-groups. So I tried splitting to columns instead.
If we tell it to split to columns we get this:
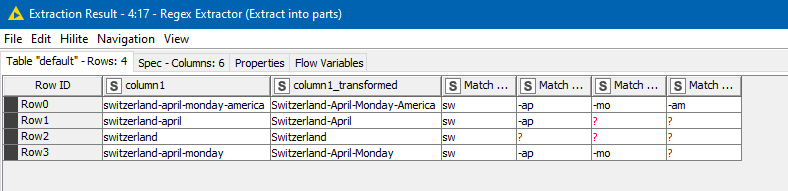
Replacing missing values with zero-length (empty) strings, we can then combine them back with the Column Combiner. So that gets it down to 4 nodes from 5, without writing the logic “in code” (as I did in the three-node option2)
Thought it would be nice though to find away of avoiding having to deal with those annoying “missing values”. Doing the Regex extraction to a list (instead of to columns) looked promising because it automatically skipped missing values from the lists it generated
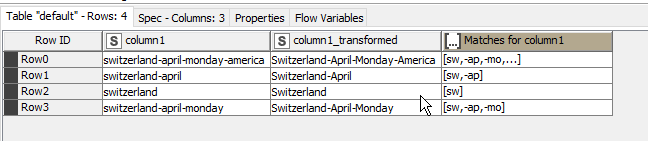
Only trouble was… finding a way to convert the collection back into a string! I thought that ought to be straightforward. Then I discovered what others had discovered before me… and it seemed to cause more trouble than I was trying to avoid!
My search led me here:
Which then led me here, with a node by Vernalis:
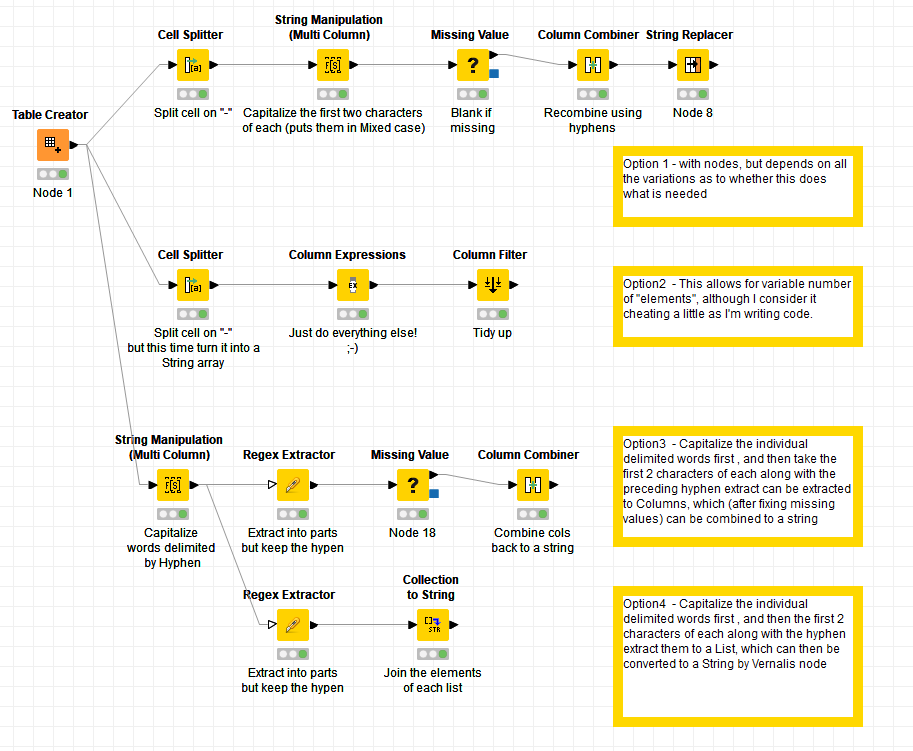
and that got it down to three nodes with no coded logic (albeit needing to use what appears to be a useful community node). Any other takers?
Yes I agree, a fun challenge! ![]()
KNIME_abbreviate 3.knwf (35.3 KB)