I attached a workflow that does what you want. Please do not blame overworked nurses, appreciate their work, hire more of them and give them a raise!
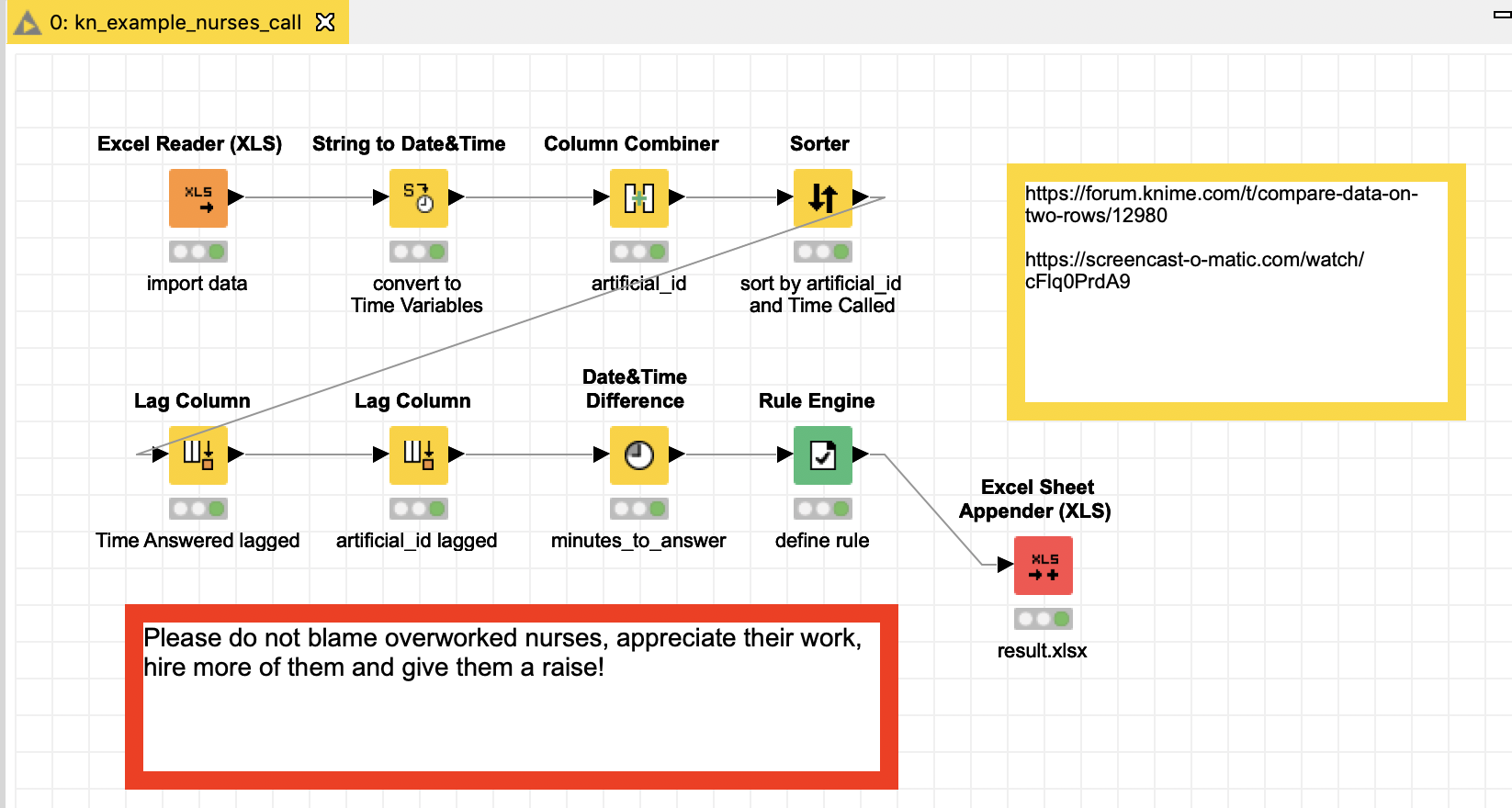
I use the three columns that should match to create an artificial ID, I sort by that id and the Time Called and then use a rule to define what is a match
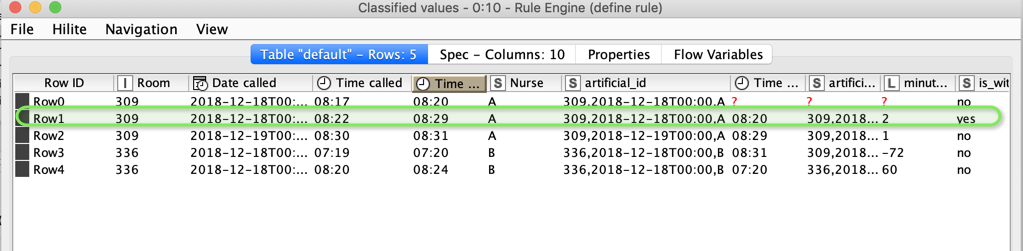
kn_example_nurses_call.knwf (60.0 KB)