Hi Knime experts,
I am new to knime. Kindly show me the correct path to achieve below -
C1 C2 C3 C4 C5 sys1_amt sys2_amt amt_diff
R1 a b c d e 0 100 100
R2 w x y z v 120 120 0
R3 a f c d e 100 0 -100
R4 j k l m n 400 400 0
There is an attribute swing in rows R1 and R3. I want to generate an automated comment saying - “Swing” in row 1 and 3
I used the below nodes combination -
Dataset → Table Row To Variable Loop start–> column Expression → Loop End
Hi @shubh , I’m not quite sure I understand your requirement. When you say there is a swing in row1 and row3, do you mean the sys1_amt and sys2_amt change?
You also want it to say “Swing” if column_val == var_val, but from what I see in your earlier logic, column_val will always be the same as (var_val * -1). Can you please explain for me, as I must be misunderstanding.
Can you show what you expect the output to be for your table (maybe upload your original table, and expected output as a spreadsheet, or possibly the workflow you have so far, to make it easier for people to assist). thanks
In rows 1 and 3, one column value is different i.e b vs f (Column 2). So, if we replace b with f or vice versa. In both systems, the amount will be equal against the same group of values. I want to identify such rows and put a comment - “swing”. But in my current test workflow, it is getting overwritten by the next iteration.
Ok, so what are your rules in terms of comparing rows? Are you comparing every row with every subsequent row, and do you only note “swing” when it is a single attribute change, or can there be more than one attribute change (and how many differences are permissible before it is considered to be a completely different row?)
Find another row if amount difference is equal and opposite ( x and -x)
for the identified pair of rows, compare each column value between each other. there can be all key swing i.e every column value can be different
I tried using Table data to Variable node but it will only compare first row with all rows in table (atleast it is what I saw ). If I can somehow increment the variable to next row, I can use that also.
Ok, I’ll need to think about how best to achieve your requirement, but if it does turn out that looping is the way, then in general variables are reset on each iteration of the loop (as you have found). 2 port recursive loops are (I think!) an exception to this, but I would suggest using iteration only if it turns out to be necessary. Where possible I try to do things in Knime in terms of “sets” of data rather than in terms of iterating through individual rows. Although sometimes there is no choice but to iterate.
There are often many ways to achieve most things in Knime, and sometimes it’s personal preference, but it really depends on exactly what is required, so I need to completely understand and my apologies, but I’ve still not got this clear.
So may I reword this to checking if my understanding of this is correct:
For any given row where the amt_diff is not zero, find all other rows that have the same (but opposite i.e. + vs - ) value.
For all such rows found, write a column called “observation” with the word “Swing” in it
Should the word “Swing” also be written on the row that we are using as the comparison?
For the example input table that you’ve indicated:
I’ve still not grasped the full significance of columns c1… c5. I understand they may change between rows but what difference does that make to your required output? Are you saying that if there are 3 differences between the rows between c1 and c5, than the observation would say “swing swing swing”?
What happens if there are two rows with 100 and two rows with -100? If any or all attributes in c1…c5 can change, then which rows would get compared, and how do you then decide what observations to write?
That is the exact output, I am trying to achieve. Observation column will have a single “Swing” even when we have all column value swing. If I can get “Swing” logic, I can replicate the logic to find difference at column level -
For the records having same amount difference( 100 and 100). I can create one column abs(amt_diff) and then sort descending, so that, I’ll have those values one after another. And then I can attend these records manually. Right now, I do not have any theoretic logic for this.
Not sure if I can achieve the output using lag node after sorting.
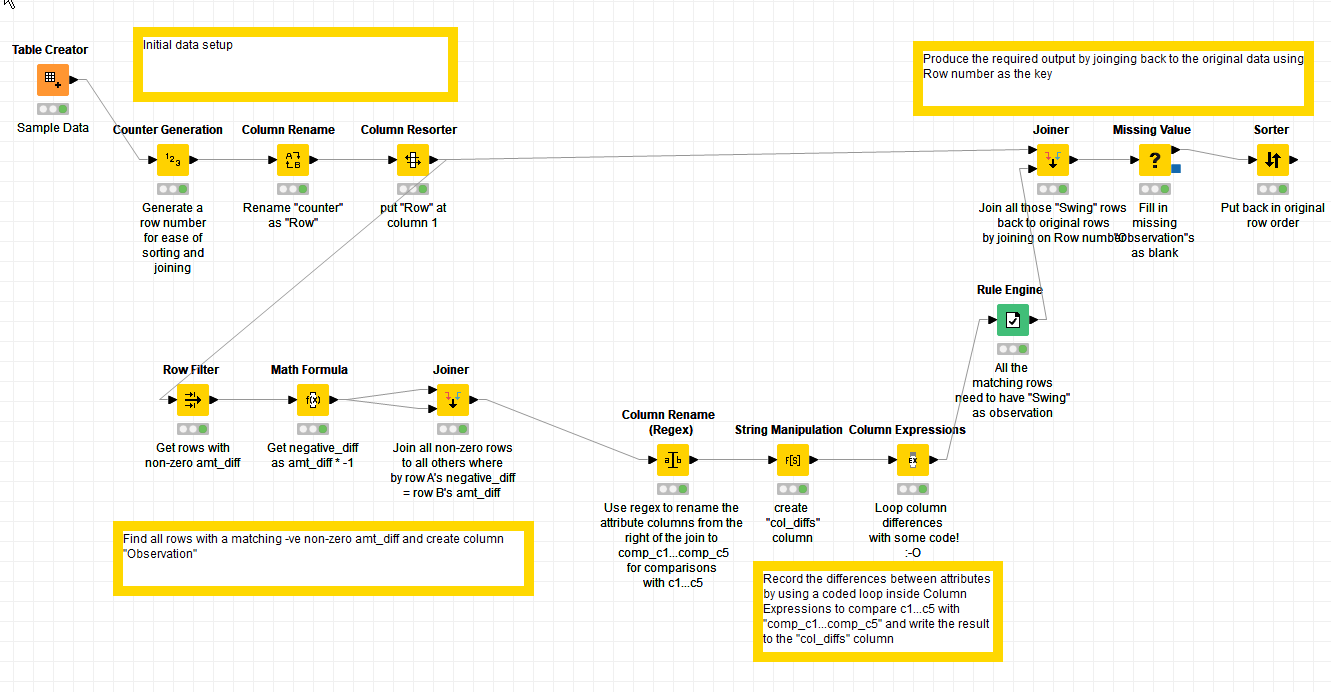
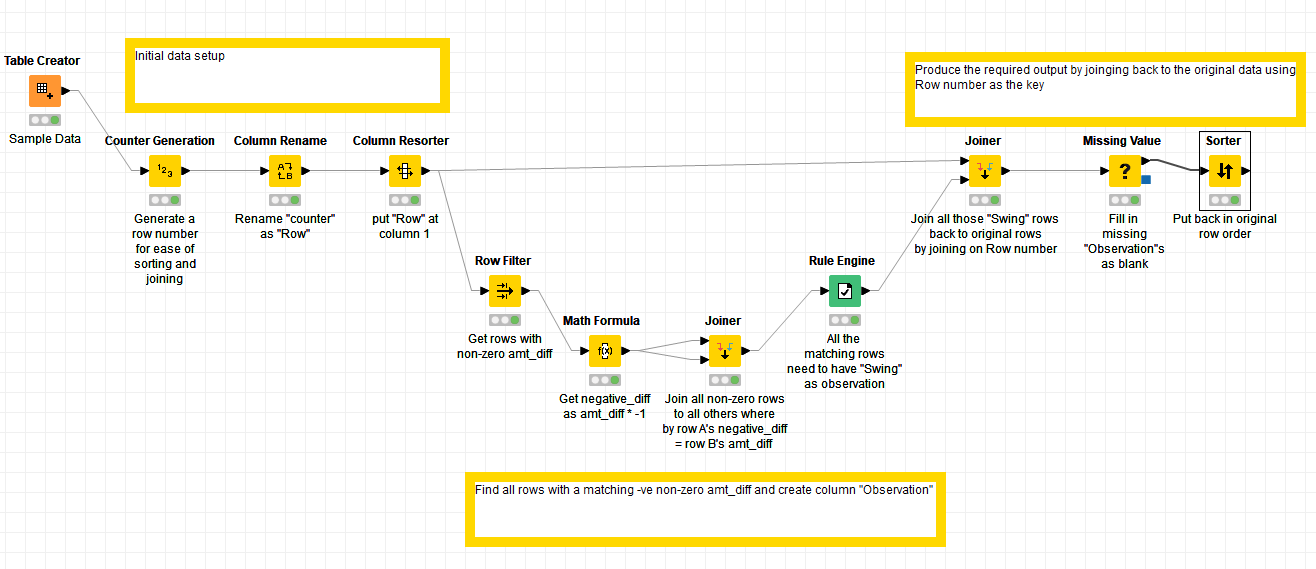
From what I now understand, you can do what you require without iteration. The trick is to find all the rows with a non-zero amt_diff, and create a “temporary” column which is the amt_diff * -1. Call this negative_diff.
Then, you can split your data into two exact copies, and join them together to find all rows where amt_diff on one copy is the negative_diff on the other.
For the rows that match in that join, you mark them with the observation “Swing”. You then join those observations back to your original data set by row number and all those rows where there is a swing will be so marked.
I have attached a workflow as an example.
Others may have suggestions for doing this with iteration, but I don’t think you need to do it in this case.
I hope that helps. It will help you if you look at the individual outputs from each node to see what it is doing and hopefully with the comments I’ve included on the nodes it will make sense.
In anticipation of the follow-up question (i.e. but how can I then determine the differences between the columns), here is one such solution which “cheats” a little in that I’ve written some code inside a “Column Expressions” node.
Prior to this node, the “Joiner” has now returned cols c1…c5 from both rows where there is a “Swing”. So one set of these columns is renamed to comp_c1… comp_c5. A new column called “col_diffs” is created into which the differences will be written, and then the Column Expressions node writes the differences it finds, using a loop (yes I know that’s an iteration of sorts too! ) …


 ) …
) …