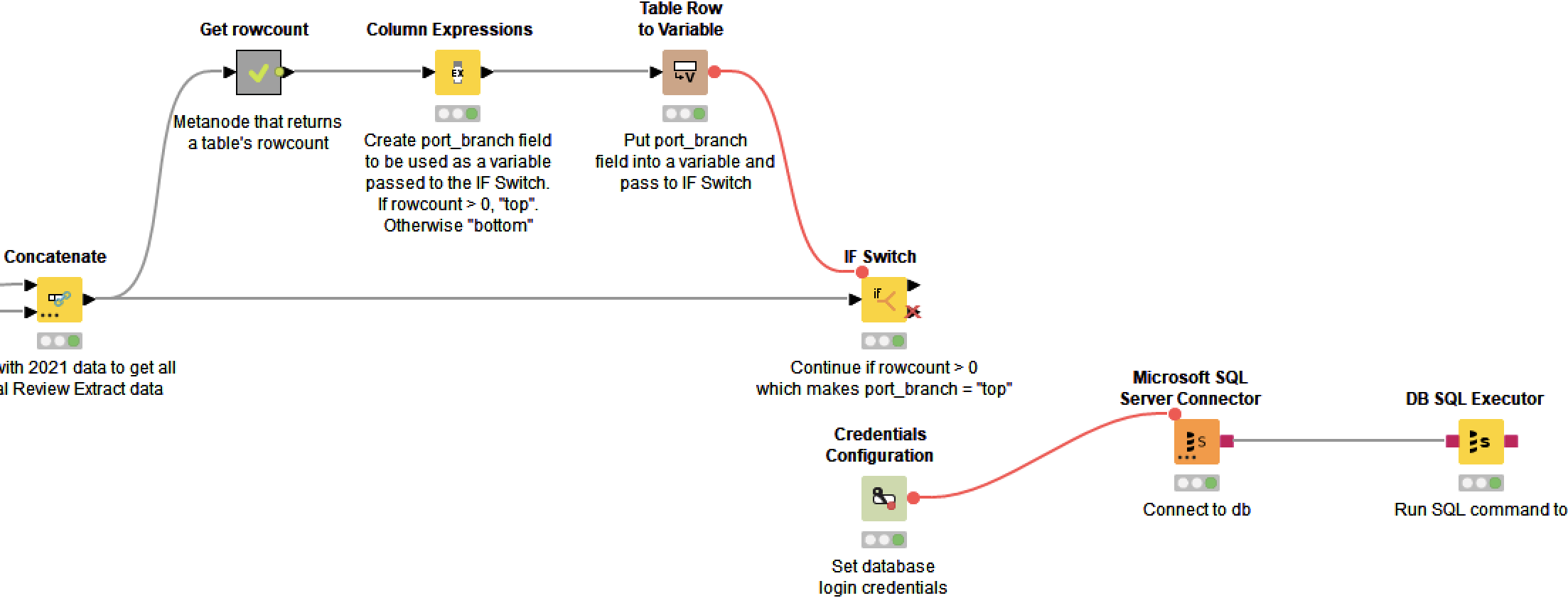
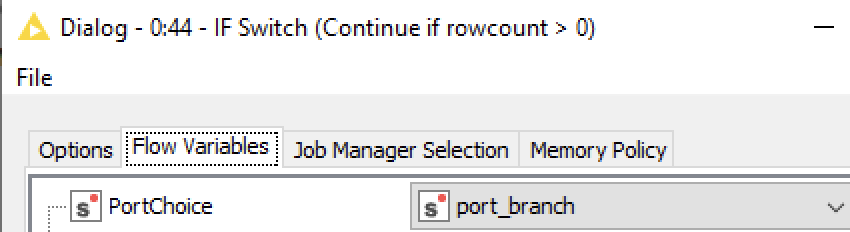
Hello, new to Knime here. I’m successfully bringing in data from a source. I’d now like to conditionally do something with the data in our SQL db only if the data’s rowcount is greater than zero. Here you can see where I’m successfully determining rowcount and passing a “top” or “bottom” variable into the IF Switch.
When the rowcount’s > 0 and the variable sent to the IF Switch is “top”, I’d then like perform db-related operations from there. But I can’t connect from the IF Switch to the db nodes. Is there a way I haven’t discovered yet where one can conditionally do db-related things based on a scenario like this?
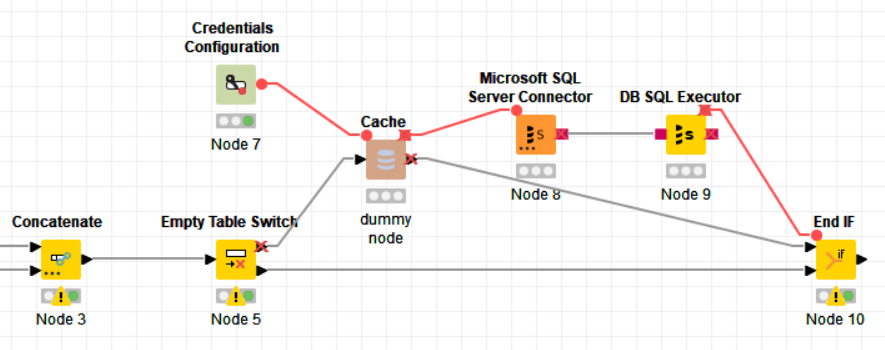
This requires a bit of trickery to get done. First we can use the Empty Table Switch for that. Non-empty tables go through the top output, empty tables through the bottom output.
We can’t connect the SQL Connector to the Switch, and a direct Flow Variable connection would not deactivate the SQL Connector, so we use a dummy node inbetween. This can be any node, I like to use the Cache node for that (it doesn’t do any data manipulations).
The dummy node gets deactivated, and so do any Flow Variable connections that come from it.
All branches have to go through the End IF node, so we connect the SQL Executor with a Flow Variable connection to the End IF, but that’ll probably look different for you.
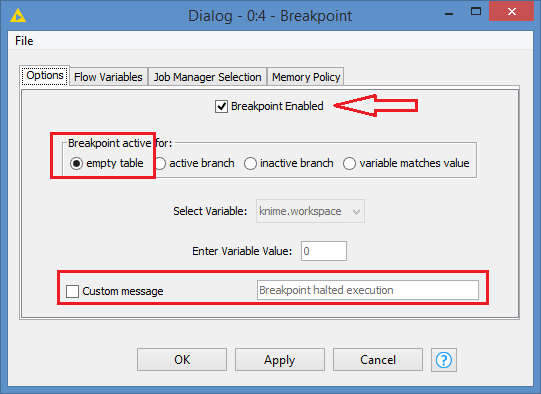
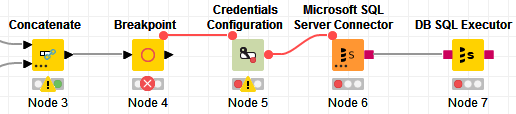
Hi @austinrecords , a simple way to implement this is using the Breakpoint node.
Simply configure it to break if the previous table is empty:
You can even add a Custom message.
You can use it as simple as this:
No need for IF … End IF or dummy nodes.
If the table is empty, the workflow stops execution at the Breakpoint, and nothing else after that gets executed. If the table is not empty, workflow does not stop at Breakpoint, and the DB Connection and SQL Executor execute.
@bruno29a Thanks for bringing this up. I actually knew that already, but whenever I used the Cache node so far it’s never been with big tables, so I kind of forgot about the IO part.
@austinrecords If there’re nodes downstream of the DB SQL Executor that need to be executed in all cases, Brunos solution would have to be wrapped in a Try-Catch block.