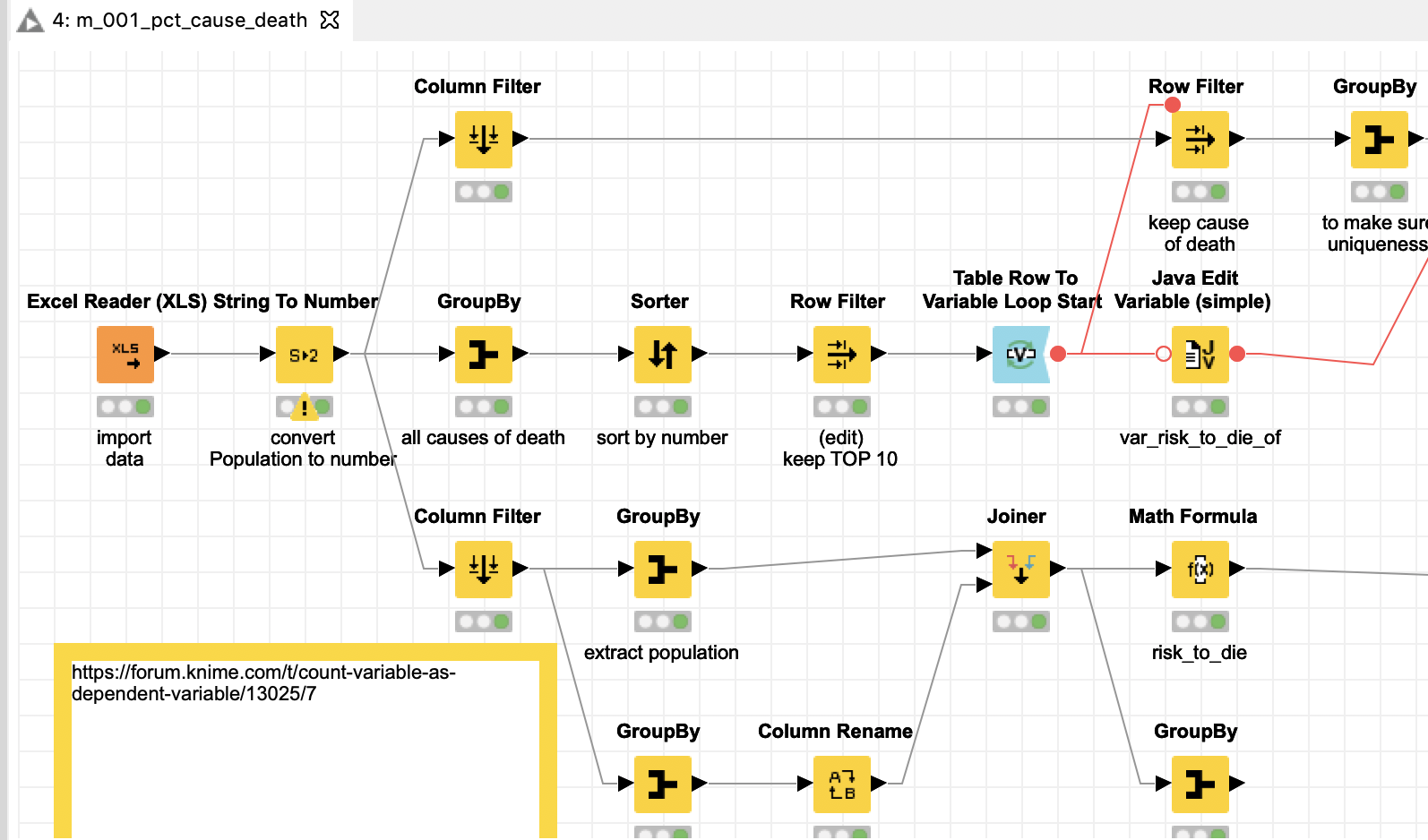
I attached a workflow where I tried to extract and bring together some information and show my line of thinking. You can determine the structure of the 270 Mio. people in the US in 2005 from the data. You could then calculate a mean risk of death for every demographic group. Then I take the 10 largest reasons of death and compare them to the average of every group and across all groups. I use an index where 100 marks the highest risk of death overall, which is white males over 85 in rural areas (that does not mean all of them will die instantly, but they equal the 100 in the index).
You might then compare the other demographics relative to that and try to interpret structures. And also you might have to check you data, since it might be that American Indians and Alaska natives are that much healthier then other people or the data might have a problem.
Depending on your task you might use the % risk of death without the index and try to interpret that. One problem is that the numbers for the following diseases are quite low so some numbers might become very small.
The example uses the TOP 10 diseases. You might use more and then calculate a relative risk of dying from some diseases over a row.