I got your workflow with data, thanks, and it works as intended. I’ve updated the workflow and reposted it with the original data/keywords on KNIME hub here. The changes made to the workflow are:
- Improvements in the pre-processing of the text documents and keywords. I’ve added filters for punctuation, short words and a few other elements that mess up matching. I’ve also added the Stanford Lemmetizer to both text and keywords which removes plurals (among a few other minor modifications to help matching). This improves the matching accuracy where keywords exist.
- I’ve also added a small routine to extract the documents where a keyword was not found and then list the extracted keyword ranked by the number of documents they appear in. This may help identify keywords that you could use to classify documents (though high frequency keywords are probably not useful for discriminating between documents).
- I’ve also added two components (it’s the same component internally) to analyse the contents of the documents and identify common themes using Latent Discriminant Analysis.
The reason you are getting blank codes for some of the matches is because the documents do not contain any keywords - you may get an improvement with the revised workflow, but it looks like 10-15% of documents cannot be matched. To try and get some insight into how the documents could be classified I split the documents into those which could be coded and those which could not.
I then extracted the words from the documents; calculated how many times those words appeared in documents; removed from the list words that only appeared once or twice; and then, for each document, filter-in the eight words that appeared least frequently across all the documents. I then used these eight words to create a summary document which I then performed topic analysis (latent discriminant analysis) to identify document themes and the most frequent keywords that characterised those themes. This I then plotted on a scatter plot to see if there was any information that could be gleaned which might provide insight into how you could code the uncoded documents.
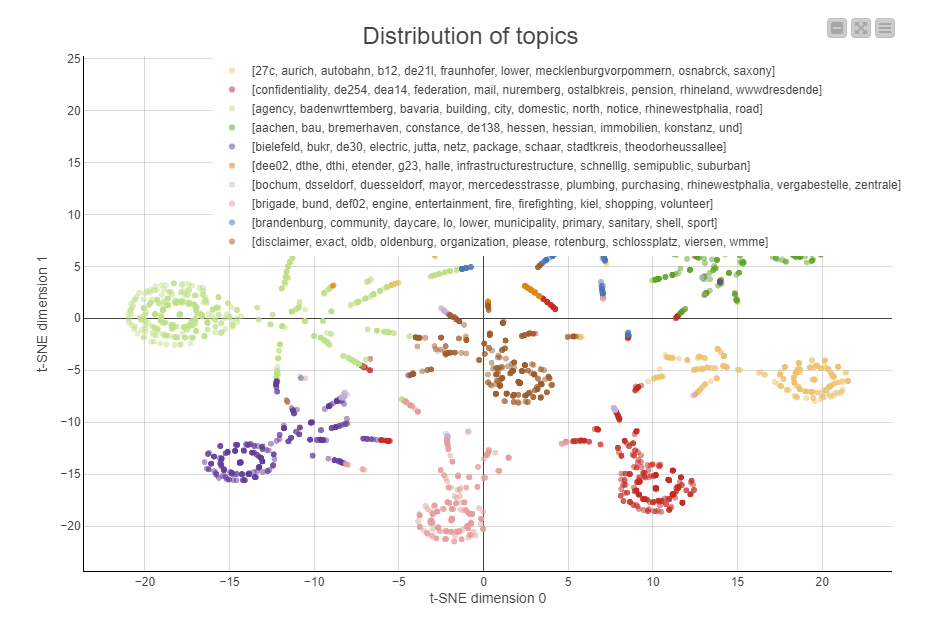
The output of the analysis is below (shared because others don’t have access to the data, but provides some insight into the results).
The analysis of documents that could be coded (apologies that the legend partially obscures the chart) shows the keywords that describe the theme. I don’t have much insight into the source of the data, but the topic analysis is mostly picking up locations and some keywords that don’t appear in the keyword dictionary. This would indicate that further analysis would need consider removing addresses/regions is appropriate. However, it may also be useful information if it relates to a particular supplier/customer and could be used to assign a code based upon non-keyword information. What is striking is that the data is well clustered indicating that the identified topics are doing a good job of discriminating the data.
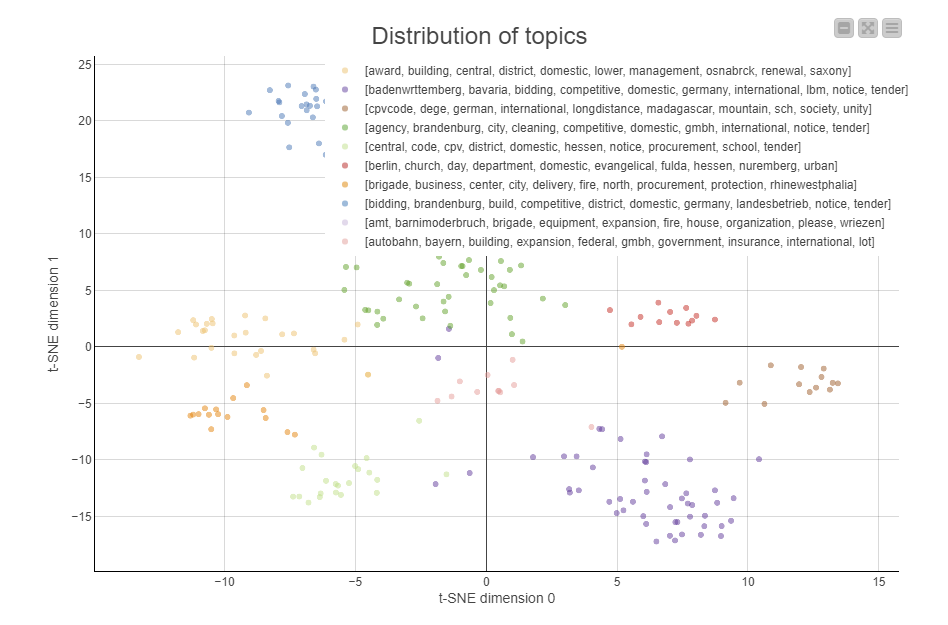
Now, for the documents that could not be clustered. This shows much less structure and the topics that make up the theme are different from the clustered data. A possible reason for the coded data forming tighter clusters is if the keywords that are coded also influence the tighter grouping (i.e. the same keywords from your list keep appearing in the coded documents); whereas, for uncoded data the pattern of keywords is not as strong.
At this point you have two potential choices:
- The manual approach is to identify additional keywords that can be coded and added to your list. This is a pragmatic, though tedious process and will only improve results if the keywords are consistently used by the originators of the documents.
- The second, indirect approach, is to consider the heuristics of the documents. In this case, rather than looking for specific keywords, consider additional information such as the addresses, telephone numbers, names, locations, trades described in the document and build a probabilistic classifier using machine learning/AI techniques. You could train this using your coded data to then classify the uncoded data - though in reality you would want a much larger data set to improve the quality of the classification.
Hope that helps (sorry it’s long winded, but there is so much that can be done arising from your initial question).