I´m new to KNIME and want to create the following workflow:
I get an Excel Input with 17 Columns and 70.000+ Rows. What I want to do is a cross search of every value in every cell. Therefore I created an extra Column combining all the 17 columns into 1. Now I can extract one value and look for it in the aggregated Column. If there’s a Match I’d like to note the ID of the Matching rows in a separate new Column.
In pseudo code it would look something like this:
for all columns (column y)
for all rows (row x)
Search for Value( row x and column y) in aggregated Column z
if match then Value (x, y) in new Column q
next row x
next column y
How do I create this workflow? Do I use loops? Which search function do I have to use? Please note that the values in the Excel are numbers and letters mixed and look like this: DMI60X2401224145HSKC32
Search every value in every cell? Where do values you are searching come from? From experience sharing some input data (dummy works just fine) and desired output with logic behind it explained (if not obvious) usually provides fast and solid ideas/suggestions/solutions
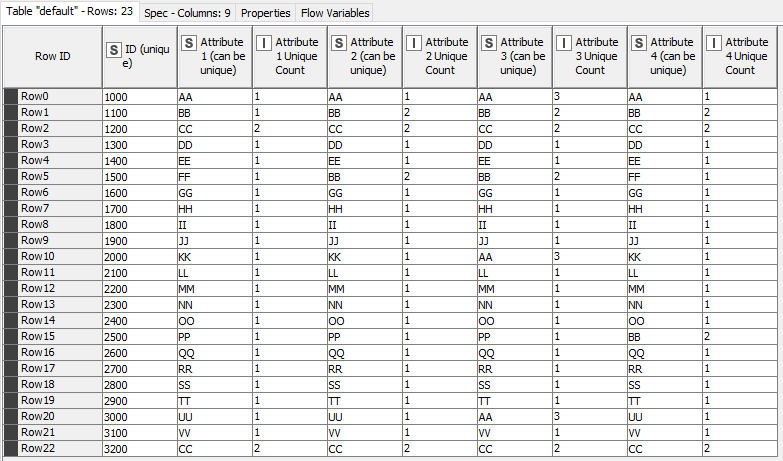
Hi, thanks for your help. I created an example input excel document and a description. Hope this helps and the pseudo code will make more sense. Cross Search Example.xlsx (15.2 KB)
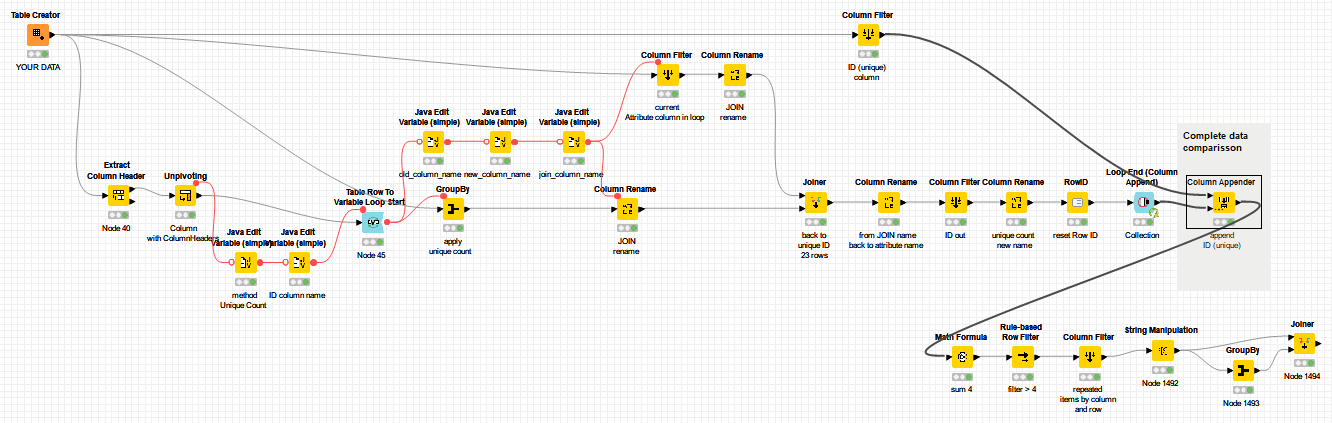
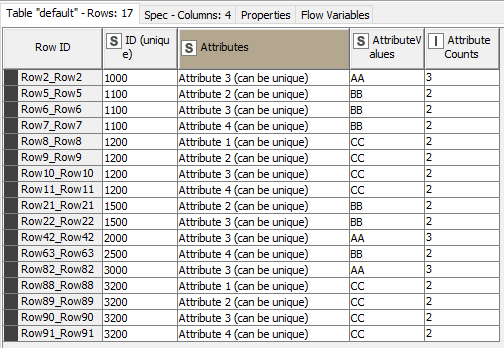
massive thanks for your solution. I integrated parts of it in my current workflow. One thing that was missing in your approach was to look for every value in every column. Therefore I created a workflow that stacks all the attributes below each other in only one column. With this one-column-approach, searching and duplicate filtering will be easier. With this solution I am almost happy. One thing I still need help with is the last part of data manipulation where I want to create a 2-column table looking like this:
Attribute | ID
AA | 1000
AA | 2000
AA | 3000
BB | 1100
BB | 1500
Somehow with the current setup I can’t keep up with the split value columns created (why are there so many?)
Would be awesome if you could take a look at the current setup and locate my mistake / give me some feedback.
@ValeW
I was in hurry the posting day, so i didn’t extend in the comments.
Just some highlights related to the workflow:
As you see, looping throughout the ‘Attribute columns’ adds scalability and efficiency instead of using multiple branches.
The core process is ‘GroupBy (UniqueCount)’ and ‘OuterJoiner’ in the loop. The most tricky part resides in configuring the variables. You still can use this core processing by branches approach.
Once you get the ‘Complete Data Comparison’, configures reporting ‘styles’ is quite straight forward.
Please find updated workflow with the un-pivoted format suggested.