Hi everyone,
I have two table like this in my database.
Table 1:
ID
NAME
AGE
1
A
22
2
B
23
3
C
12
4
D
12
Table 2:
ID
NAME
AGE
1
A
22
2
B
23
And I want to filter the table 1 so that only rows, which have “ID” NOT in “ID” of table 2, is remained.
So the table 1 after filtering will be:
ID
NAME
AGE
3
C
12
4
D
12
I can see we have option Reference Row filter, however, before it can be used, I need to use DB reader node first.
Is there any way I can querry directly on database, i.e. not use DB reader but a DB node instead? since my table has 2 mil rows, using DB reader would take ages
I got the idea of using DB querry, but not sure how I can filter using reference table with this node
A good answer from @izaychik63 but just to follow up on how you could use DB Query, as you never know when you might need to resort to SQL for that really complicated query that you already have lying around…
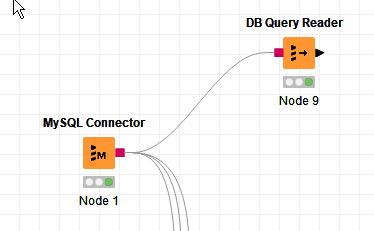
You could use DB Query Reader attached directly to a database connector:
and then in the DB Query Reader (if you did not need to do any further in-database work, you would put a statement such as this:
select * from gnl.table1 a
where a.id not in (select b.id from gnl.table2 b where b.id is not null)
(gnl just being my general purpose schema on my test mysql database)
In your case I guess b.id would never be null, but I include that to be on the safe side since the clause would find matches if it did return nulls!
or an alternative query could be:
select * from gnl.table1 a where
not exists(select 1 from gnl.table2 b where b.id=a.id)
To use a DB Query, if you needed to do further joins within the database, you can first use a DB Table Selector to reference Table1 and then attach DB Query which additionally references Table2
Here the SQL Statement in the DB Query would be an amended variant of one of the queries above:
SELECT * FROM #table# AS `table`
where id not in (select b.id from gnl.table2 b where b.id is not null)
or
SELECT * FROM #table# AS `table`
where not exists(select 1 from gnl.table2 b where b.id=`table`.id)
In both cases the initial
SELECT * FROM #table# AS `table`
line is pre-filled by Knime and provides the reference to the table in the DB Table Selector.
So this isn’t quite “as Knime” (non-SQL) as the good solution that has already been offered but hopefully may be of use if ever need to use the alternative.
btw, I have an off topic question regarding rename column with DB querry.
I would like to convert datatype of column “AGE” from Double to INT.
I used CAST function, i.e. CAST (“AGE” AS INT) AS “AGE_2”
I wonder if is there any way I can overwrite the old column “AGE” without creating an additional column (AGE_2)? Because, then I have to drop column “AGE” and rename “AGE_2” to “AGE” if I want to keep the orginal name.
Are you just meaning the column name used within the DB Query? Usually in sql there is nothing to stop you naming the evaluated column in the SELECT clause the same as an existing column from one of the tables within the query, so if you are just talking about renaming it within the query, I would think you could just write it as:
CAST (“AGE” AS INT) AS “AGE”
(The column names returned by a query have no effect on the underlying tables, or the column names used elsewhere in the query)
Oh that’s annoying! Which db are you using, and are you able to post the query and maybe a screenshot of the workflow (or part of it) to get some context that might help with alternative suggestions.
hi @takbb
I am not sure actually, but I am using a connector to Snowflake server (which has an DB SQL connector, DB dialect SQL-92) and then DB Table Selector and DB querry
SELECT
CAST(“AGE” AS INT) AS “AGE”,
*
FROM #table# AS “table”
yeah, now I get the issue is probably as you said, but then I have to put all other columns to SELECT statement as well? Could u please suggest a shorter way to implement this?
Ah ok, it’s the * that’s doing it. That will return all the original columns too (including AGE), so you will need to replace the * with the individual remaining column names (i.e. without AGE).
(I don’t think there is a shorter way within SQL unfortunately. )
The only thing is, what are you doing with it after you get the results back? If you are returning the details to Knime for processing, then can you leave it as AGE2 in this query, and then get knime to remove the AGE column and rename AGE2?
Also, by way of good practice, it isn’t really great to use * in a production sql query, as it might break if anybody ever adds a new column to the table(s), or the order of the columns change, if downstream something expects columns in a particular order or position. It is a pain writing all the column names in full, (I’ve been there many times!) but it is best practice.
As a shortcut, what you can do is run the query in your dev environment, pick up all the returned column names, paste them in an editor an replace space or tab or whatever on the heading line with commas, then paste the result back in your query. It can save some effort!