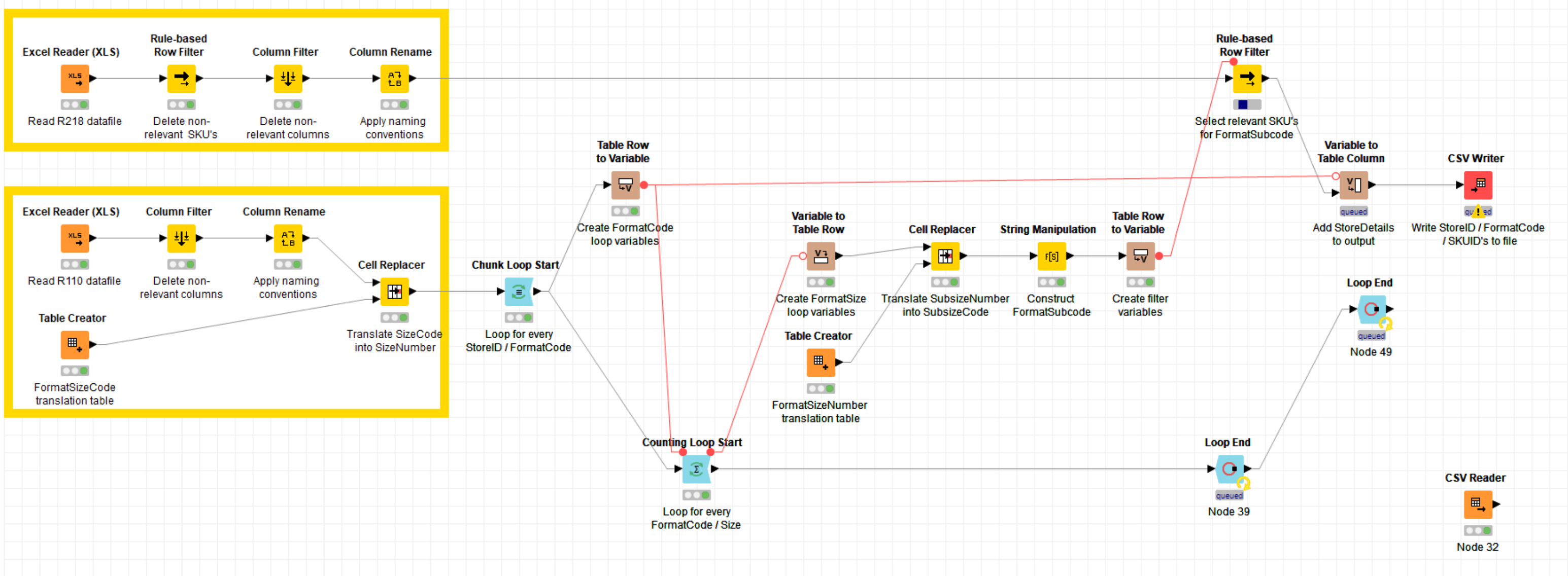
Hi guys,
Have been using KNIME for some months now and helped me out big time. My skills are limited to basic data manipulation and loops, but eager to expand on that every day! Came across a use case today that exceeds my current capabilities and need a push in the right direction. Much appriciated!
Data structure #1 - products in catalog
| CatalogID | ProductID | ProductName |
|---|---|---|
| XBA01A | 1 | ANDRELON HAIR MASK DELUXE CURL&SHINE |
| XBA01A | 2 | RAVENSBURGER NIJNTJE 65 JAAR |
| XBA01B | 3 | ANDRELON HAIR MASK DELUXE REPAIR&SHINE |
| XBA01B | 4 | ANDRELON HAIRSPRAY TEMPTINGLY SHORT EXTR |
| XBA01C | 6 | AXE DEOSPRAY 150ML NEW DESIGN YOU |
Data structure #2 - catalogs per store
| StoreID | CatalogID |
|---|---|
| 10003 | XBA01A |
| 10004 | XBA01B |
| 10005 | XBA01C |
Based on these two data structures I want to create a full list of all StoreID / ProductID combinations; basically a full assortiment list per store. Normally I would use a full outer join linking the CatalogID’s and that would be it.
Problem is the legacy data structure, where the last symbol in the CatalogID actually represents the catalog size (A is smallest, G is largest). And a catalog also includes all products in the smaller catalog sizes (i.e. each catalog size only includes the incremental products). For example: catalog XBA01C also includes products from catalog XBA01B and XBA01A (because A < B < C).
Desired output for store 1005 (single example store)
| StoreID | CatalogID | ProductID | ProductName |
|---|---|---|---|
| 10005 | XBA01C | 1 | ANDRELON HAIR MASK DELUXE CURL&SHINE |
| 10005 | XBA01C | 2 | RAVENSBURGER NIJNTJE 65 JAAR |
| 10005 | XBA01C | 3 | ANDRELON HAIR MASK DELUXE REPAIR&SHINE |
| 10005 | XBA01C | 4 | ANDRELON HAIRSPRAY TEMPTINGLY SHORT EXTR |
| 10005 | XBA01C | 6 | AXE DEOSPRAY 150ML NEW DESIGN YOU |
Therefore a full outer join doesn’t cut it, because it will not include the products from the smaller catalogs to the store assortment. My proposed solution in pseudocode:
- Loop row-by-row through data structure #2 (catalogs per store)
- For every row, isolate the CatalogID and look at the last symbol representing the CatalogSize
- Loop from A to Catalogsize, and insert all products from data structure #1 (products in catalog) associated into a new table (StoreID, CatalogID, ProductID).
Help is needed to validate this approach and convert it into a KNIME model. Some guidance is appreciated! Thnx!