Hi! so I’m pretty new to KNIME and we’re supposed to work on a model to predict whether a student will pass or fail based on a series of attributes. However, after building the decision tree model, we’ve found out that the decision tree learner predicts that a student will pass more than they will fail, regardless of how much we change the settings. Is it something to do with our data or what settings should we change? Thank you in advance for your help!
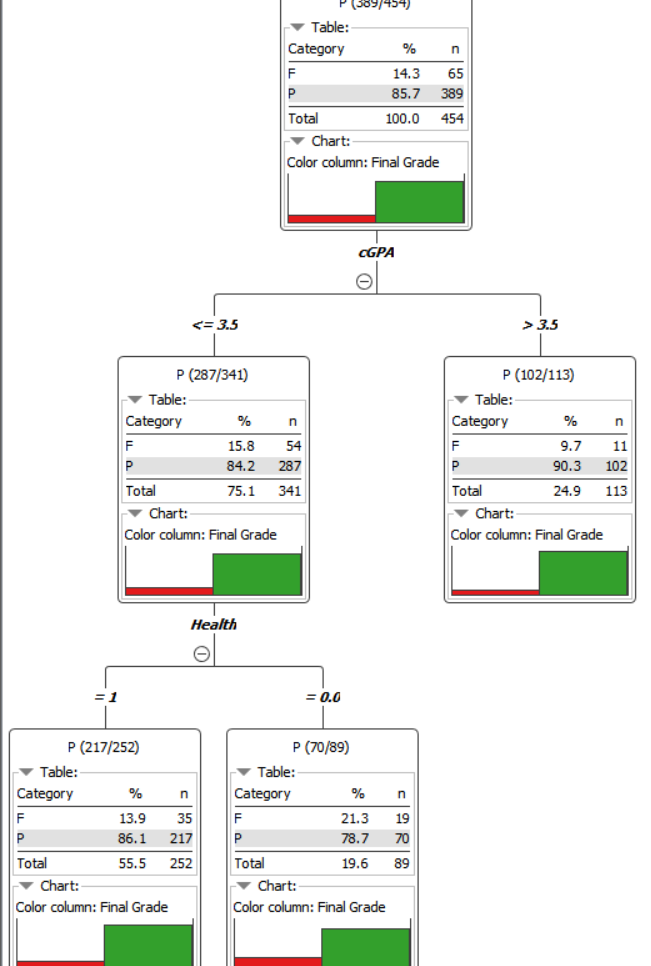
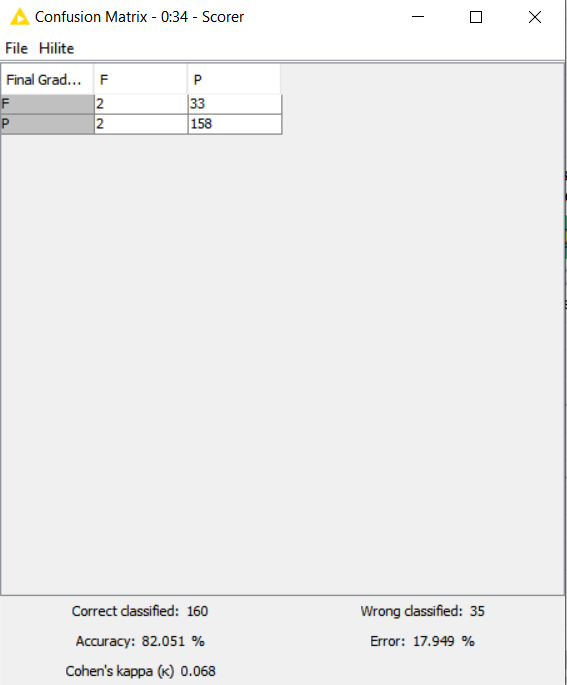
This isn’t really a Knime issue, it’s a decision tree issue. D Tree basically just finds the variables that are most correlated with differences in an outcome, splits on that variable, then go within that split group, and repeats the process. D Trees are good for having a peek at what variables might be the most associated, and subsequent interactions, but really aren’t good for much beyond that for small data sets. Random forest or XG Boost may be better suited for your needs.
The bigger problem is that there are a lot of variables that are highly influential on grades which you couldn’t possibly have in your data set, so you’re only going to be able to speak to a few trends that you can observe.
1 Like
This topic was automatically closed 182 days after the last reply. New replies are no longer allowed.