Dear all,
Example:
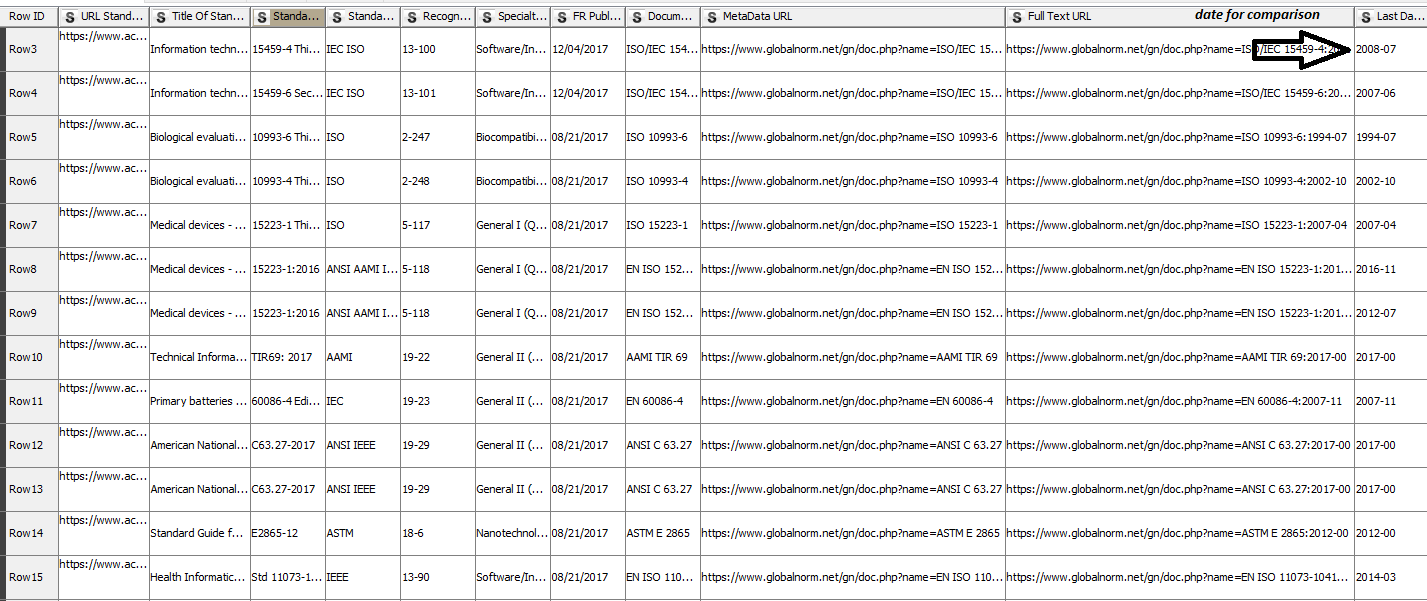
OutPUT need to be like that:
Standards | link | update date
Bests.
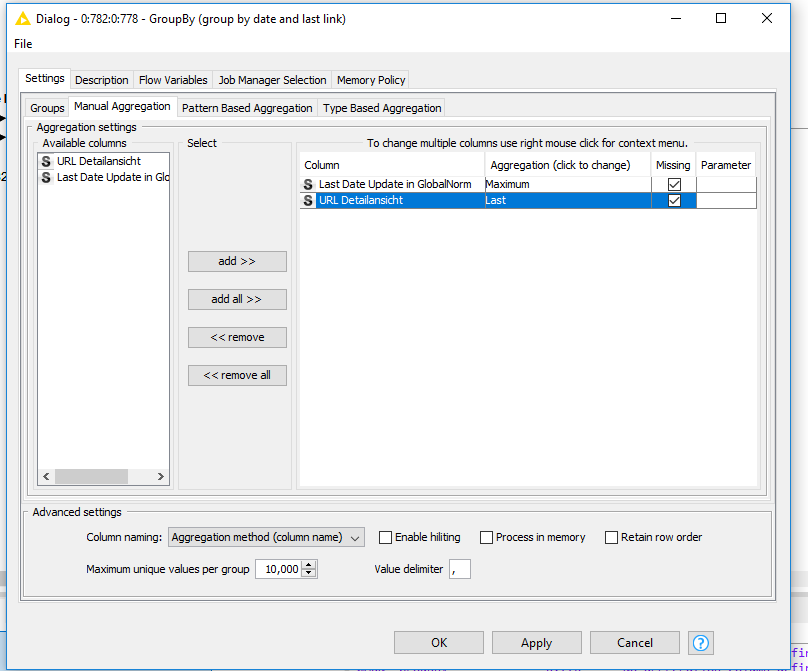
Hi @Mokrani GroupBy node, add the columns that stay the same in the Group Column(s) table and use the aggregation method Maximum on the update date column.
Could you send me an example to understand more? im quit new in knime?
Here you go:
GroupBy demo.knwf (6.0 KB)
best,
1 Like
Thank you!!
Example:
OutPUT need to be like that:
Standards | link | update date
but in your workflow I got
Could you help about that?
I find a solution about that by adding aggregation get the last URL (because I notice that knime can sort automatically the string date )
Thanks again.
1 Like
system
May 31, 2018, 1:29pm
9
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.