Let me give you an overview on what I am doing, so that you can have better idea and easily guide me to the right direction.
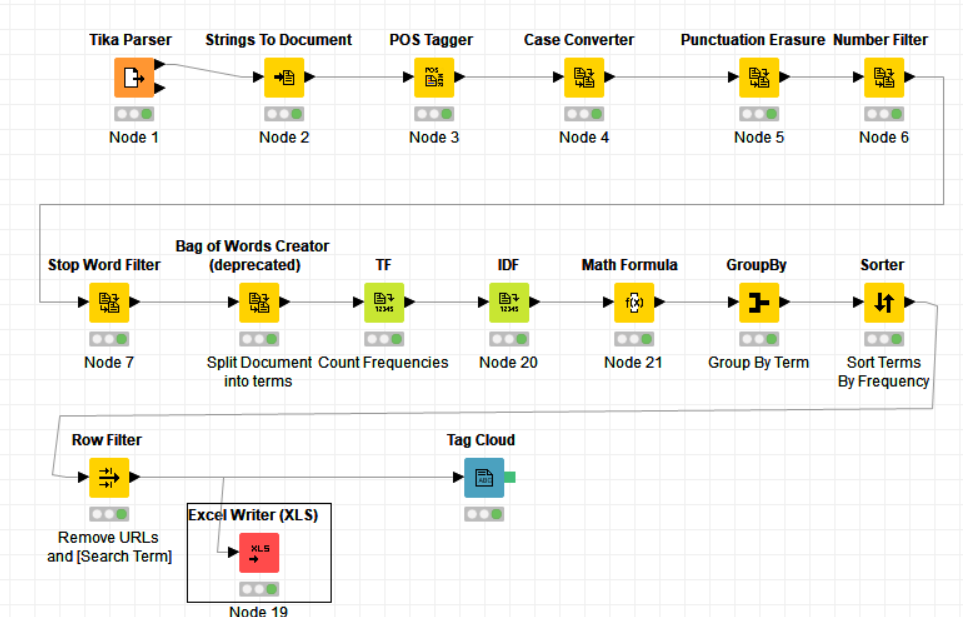
So, I’m using KNIME for extracting information from PDF’s files (mostly these files are Future Trend Reports). I’m using following workflow in order to capture common information out of these files.
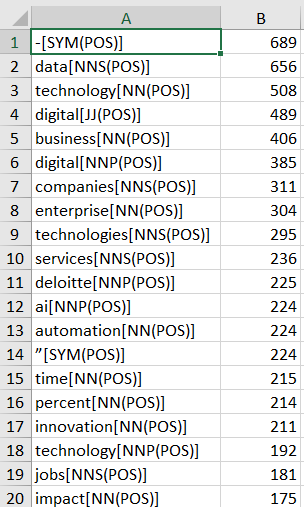
As a result, I am getting common words like “digital”, “data”, “automation” etc etc, I got the common words out of it, but they are not making sense. I need to detect common phrases which has been used in those documents (reports) to have better understanding because as an individual word, it doesn’t make any sense that what does e.g data mean in these documents. Is it like “more data is needed” or “data threat” or something like that, similarly to automation and other words too.
So, I need to detect multi-words/phrases out of these documents (PDF’s report). Would you like to tell me how is that possible as I haven’t found any example on KNIME platform.
You can create n-grams using the NGram Creator node with different N and select the most frequent ones (you will get Corpus frequency, Document frequency and Sentence frequency statistics for each n-gram in the output table).
Thank you for your reply. I have used NGram node and got the frequent corpus which are occurring most.
Might be my question is a little wage, after using this, still I’m not getting what I need. Like, the phrases which I need to detect are the ones which are related to “trends” e.g. If I get the trend out of these PDF’s is “Artificial Intelligence”, so what are the most frequent phrases or multi-words associated with artificial intelligence. That’s what I am looking for.
Does it relate to “Association rule” type node or something other? If so, is it possible through using pdf files as I have see association rules’ example videos, they are using tables and csv files but I have pdf’s files having text only.
There is the Term Co-Occurence Counter node, which counts the number of co-occurrences for the given list of terms within the selected parts e.g. sentence, paragraph, section and title of the corresponding document, which I believe will help you with your problem.
Hi @izaychik63
Would you like to be little more clear, as I am not that used to this tool, can you tell me which node to use as I haven’t found node for topic thesaurus.
Sorry, Rashid. I’m not talking about nodes. Just try to bring your attention to the fact that you look at the task as unmanageable automatic classification. But it is manageable/supervised. You need to specify criteria what corresponds to the topic and why.