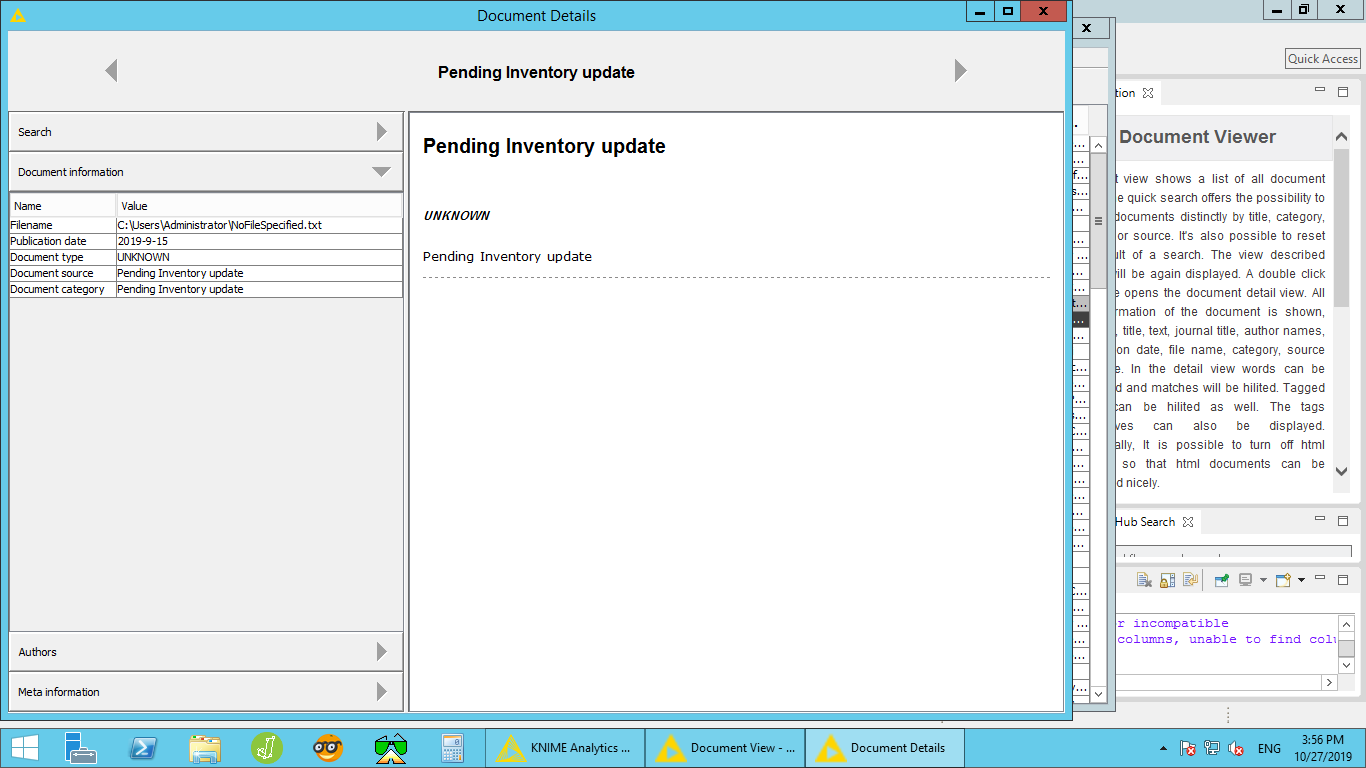
how the document’s category, title, author, etc are read? In other words, during view the document using “document view”, the category is the same as the document column. So, according to what determine the category, author, etc?
Another note, the text is repeated for title and body. why?
In that case, I would carefully check the settings of that node to see if the category, author, and other meta information were originally assigned as you intended.
There are several workflow examples on the Hub using the String to Document node if you need additional clarification.
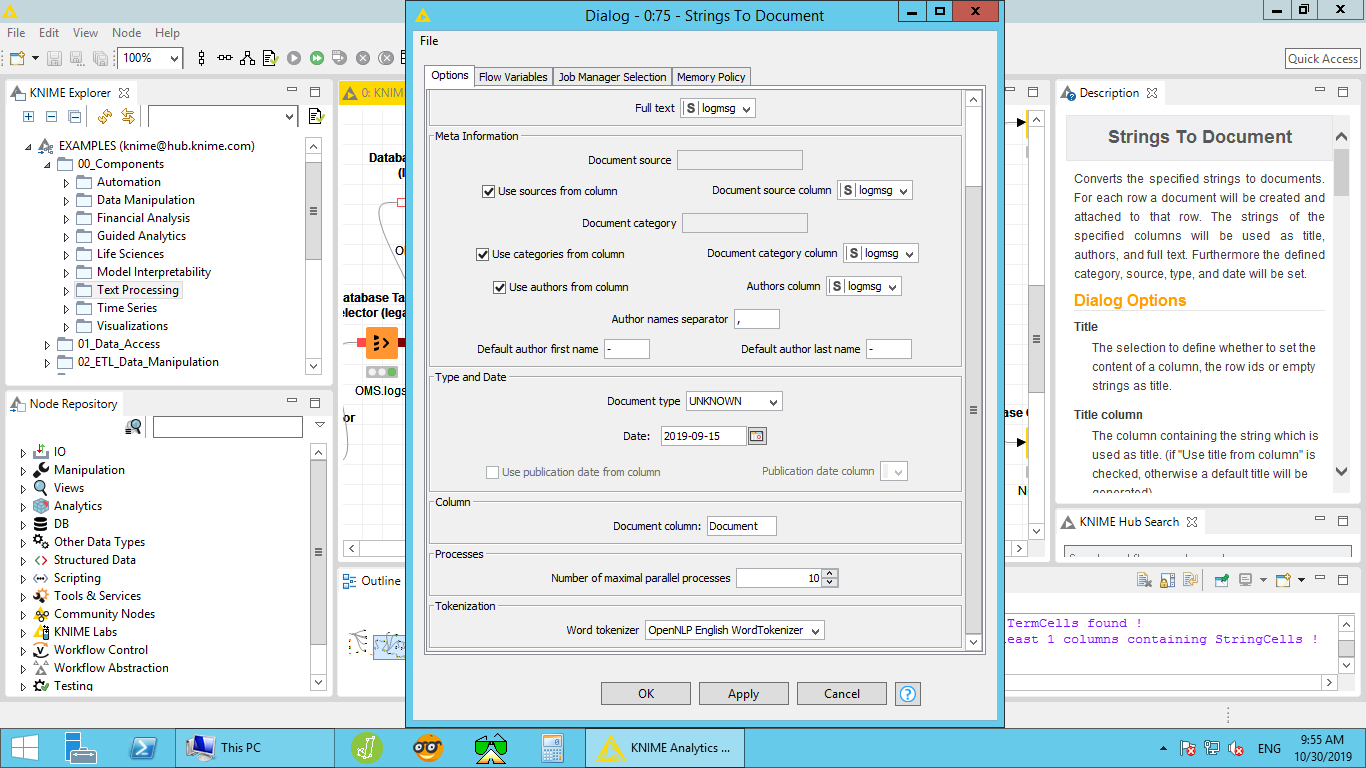
Here you are the configuration of string to document node.
Is that probable because of I read a large text column from the DB directly?
Could you please provide the examples path on the Hub?
Many Thanks in Advance.
According to your screenshots, you’re pulling the meta-info (source, category, author) all from the same field as the text. If you don’t actually have meta-info, you can just untick the boxes and those variables won’t be assigned.
In this example workflow, you can see the meta-info being assigned in the Strings to Document node, based on fields in the original text file. Let me know if you have more questions.