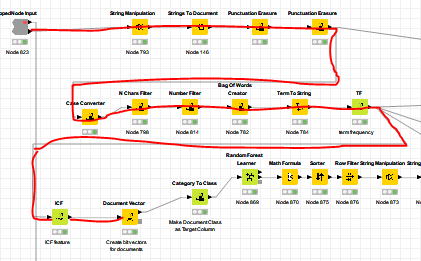
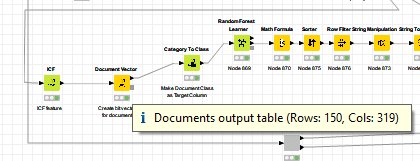
the DocumentVector node requires a column containing DocumentCells. For each row of the input table a row in the output table is created. The KeywordExtractor Node extracts a certain number of keywords for each documents. Using the output table of the KeywordExtractor, thus leads to more than one row (vector) per document. You can use the GroupBy node after the KeywordExtractor node and group over the Documents, which creates an output table containing one row per document. This table can be used as input table for the DocumentVector node.
in my last post in this thread i wrote that the DocumentVector node creates a Row (document vector) for each document in the input table. This is not true, i apologize for this misinformation. The way you used the DocumentVector node is the right way. You can apply the node on a bag of words input table. This is the way the node is ment to be used. The node should create for each unique document in this bag of words input table exactly one row (document vector).
Obviously this is not the case in your workflow. Can you give me some more information about the nodes you are using? What is the exact preprocessing chain and how do you extract the keywords? Are you using the Frequency Filter node to extract keywords? A screenshot of your workflow, or the workflow itself without data would be really helpful. I think there might be a problem but not in the DocumentVector node itself but maybe in the keyword extraction process/node. In the DocumentVector node simply the equals method of a document is used to compare them.
@asenkron What may be happening here is that, due to the BoW, I would expect any empty document (after preprocessing) to be removed. The solution should be to join the filtered ones back in using Document Vector Applier first and then Joiner.