Hello,
So basically I was trying to join 2 tables and that is what happened and I have no idea why it did not work…
Here is the screenshot of the error:
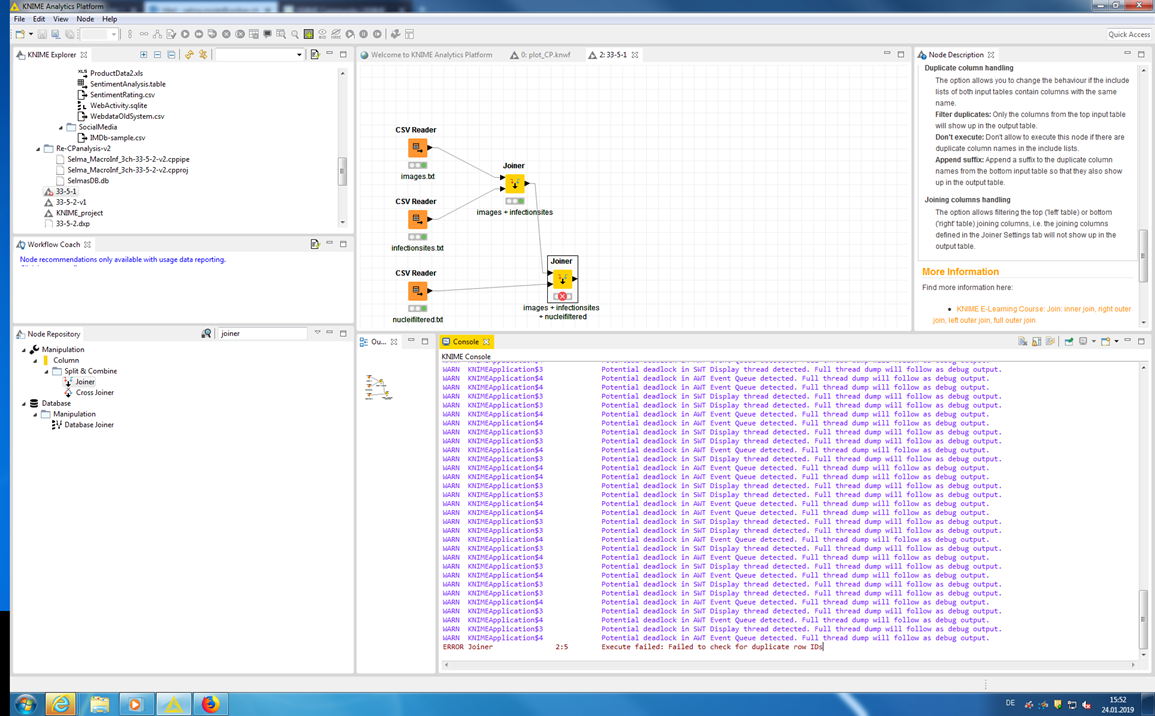
Thank you for your help!
Selma
Hello,
So basically I was trying to join 2 tables and that is what happened and I have no idea why it did not work…
Here is the screenshot of the error:
Thank you for your help!
Selma
Hi @SeMo,
unfortunately the attached workflow does not contain any data. Could you maybe include the data in your workflow (uncheck the ‘reset workflow’ option upon export)?
Sorry about that, as it is too big to be uploaded here, here is the link to a drive https://drive.google.com/open?id=1F6nFkiQS90ZGWTobxI1gsW8AthAhNGZ5
I hope it works
Cheers
Selma
Hi @SeMo,
thanks for the workflow. It seems that you want to do an extremely large join as there are many duplicate keys in the input tables of the joiner node that fails. I calculated that the resulting table would contain 952069475 rows which is probably the reason for the failing node (we are looking into that). However, is that really the goal you want to achieve? Usually keys should be unique. Could you maybe elaborate on how you would like the table to look like?
Cheers
David
So basically I ran a cell profiler analysis which gave me 3 output files “images.txt”, “infectionsites.txt” and “nucleifiltered”. The name of the wells only appear in the “image.txt” file. Each well contains 25 sites that are named “Image number” in those 3 files. For my analysis I need to compile all the sites (image number) from one well together for later display my data on graph for each well. Regarding the biggest file “nucleifiltered” I am actually only interested in the column named “Neighbors_NumberOfNeighbors_infectionsites_Expanded”, I don’t know if it makes it easier…
I am just starting to use KNIME, so far I would load my .txt files in Spotfire but this software can not compile several files so it was very complicated to associate the Image number with the name of a specific well.
I don’t know if it is clear and whether those informations help…
Let me know if you need more informations!
Thank you!
Selma
Hi @SeMo,
Do you mean you want to do some kind of aggregation on the sites? If that’s the case you could just use a GroupBy node after the “infectionsites” and “nucleifiltered” and choose the ‘ImageNumber’ as group column. Then chose the type of aggregation you’d like to do in the Aggregation Tab. This way you would end up with a unique key and then just join on ‘ImageNumber’ with the “images” file to get the name of the wells into the table.
Also, if you are only interested in a specific column for one of the files you could filter out all other columns using a Column Filter node. Doing the filtering as early in the workflow as possible (hence reducing the amount of data) is always a good idea to speed up the processing.
Cheers
David
Hi David,
Thanks a lot for your help! I eventually manage to combine my data within a Tab by grouping them ahead.
Cheers
Selma
https://drive.google.com/open?id=1sHu4sq1TvvyvcX6AGu-Yec1TIvtFfp_S
Hi @SeMo
I’m glad that I could help. One more thing: Could you maybe mark one of the answers with the ‘solve’ flag? (there should be some button under the answers) This way the thread shows up as solved in the search.
Thanks
David
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.