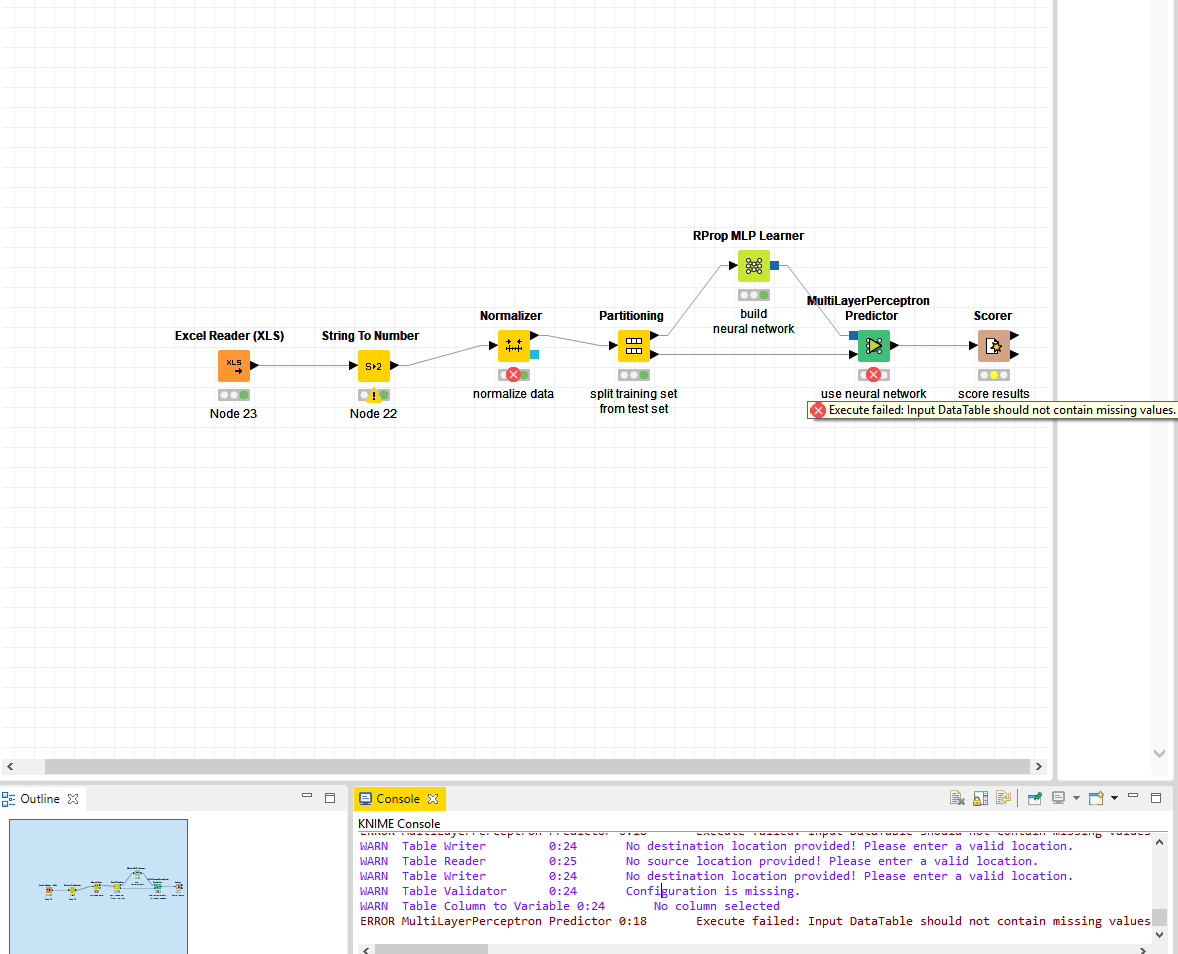
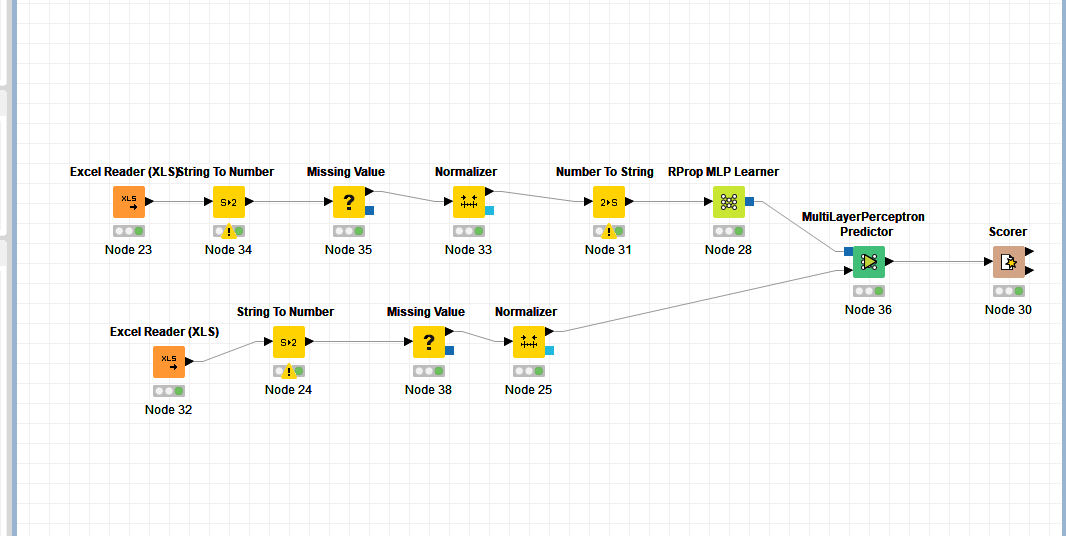
I have such a problem with NN. Here is a screenshot of my workflow. What should I do to fix this error “ERROR MultiLayerPerceptron Predictor 0:18 Execute failed values”?
Dear @Freud,
the error message indicates that your data contains missing values which the MultiLayer Perceptron Predictor can’t deal with.
One way to fix this issue is to use the Missing Value node to remove the missing values.
However, there seems to be more awry in your workflow indicated by the error sign on the Normalizer node.
Could you provide me with the error displayed on the Normalizer node?
Kind regards,
Adrian
Can you please tell me how to remove missing values? I only see a fix.
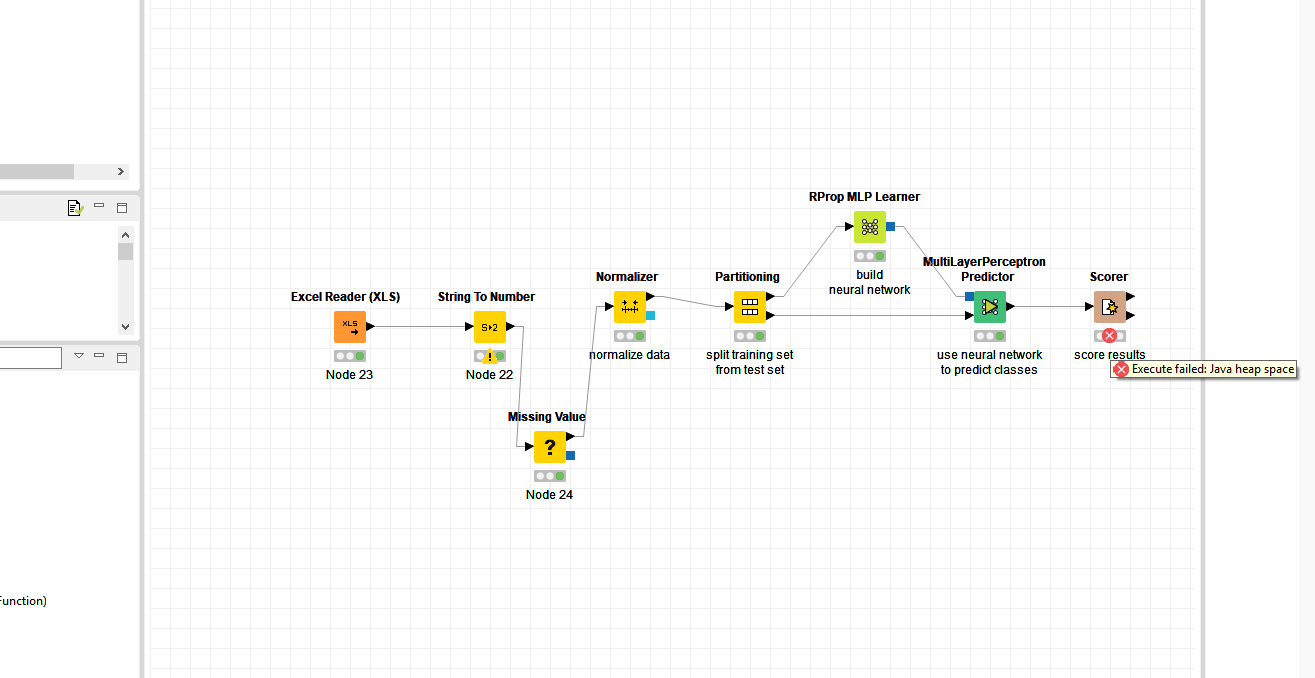
After I added the node “Missing value”, the error from the node “Normalizer” was fixed, but appeared in the node “score”.
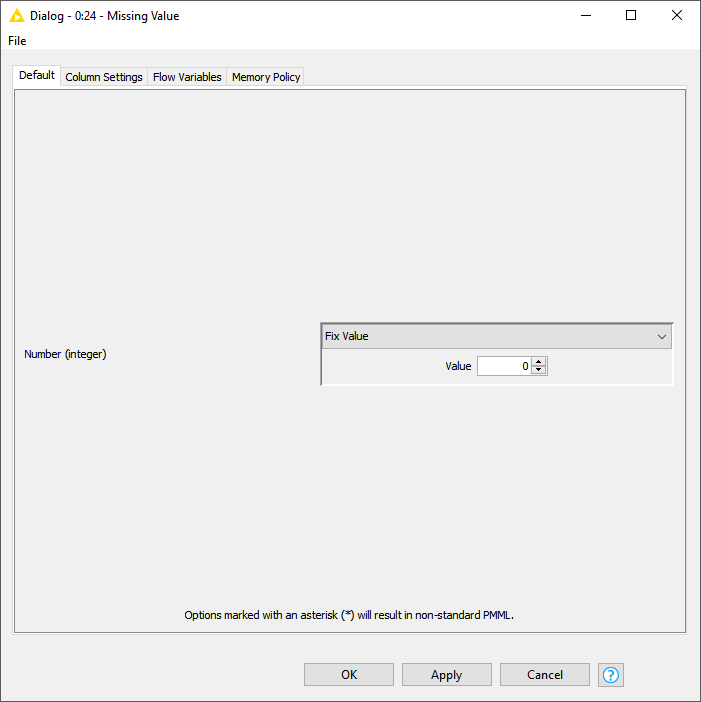
If you click on the dropdown menu that currently displays “Fix Value”, you can choose among different strategies to fix missing values. Which one works best depends on your data and use-case.
Could you provide a screenshot of your data or even the workflow?
The error displayed on the Scorer might be due to a problem with the configuration.
Did you select the column that contains the true class and the column that contains the predictions?
1 Like
 but maybe you can help me with my settings?
but maybe you can help me with my settings?
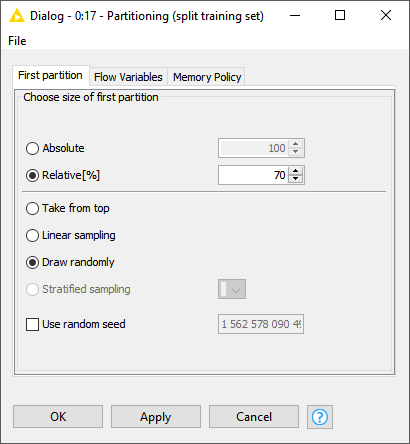
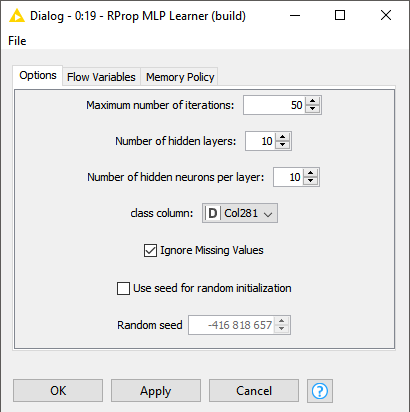
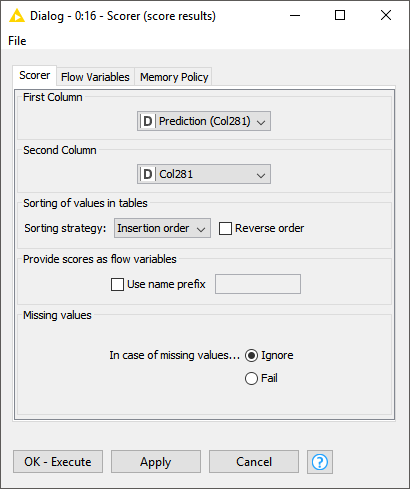
Ok, then can you tell me what the goal of your workflow is?
Currently it looks like you are trying to learn a classification model on a numerical double column which is unlikely to succeed (hence also the error in the scorer node).
@nemad I want to classify data using a neural network. The data is stored in the Excel file and consists of both numbers and words. Also, there are categorical values and numeric values. Please tell me what I need to fix?
Currently you selected the numerical column Col281 as class column in the RProp MLP Learner node (and consequently in the scorer node as well), are you sure that this is your class column?
Class columns are typically of type String.
@nemad Yes, column 281 contains the error code (281, 658, 1, 0, etc.) that I need to predict. Isn’t that a numeric column?
If this is a class column then you should convert it to String (using the Number to String node) to indicate this to the learner. The learner currently performs a regression on the column which is probably not what you want. Furthermore, how many unique error codes do you have and how large is your dataset (how many rows)?
1 Like
In that case you just need to insert the Number to String node in front of the learner and you are good to go.
Maybe some advice regarding your choice of model: While neural networks are very popular due to the success of deep learning, they almost always require a lot of fine tuning to work in practice, especially on tabular data such as yours. Random Forests and Gradient Boosted Trees usually require far less tuning to achieve similar results (e.g. they don’t need any fine-tuning and can deal with missing values).
Yes, this could work but make sure that you only convert Col281 to String.
Your other question I can’t answer because the answer depends on your data which I don’t know.
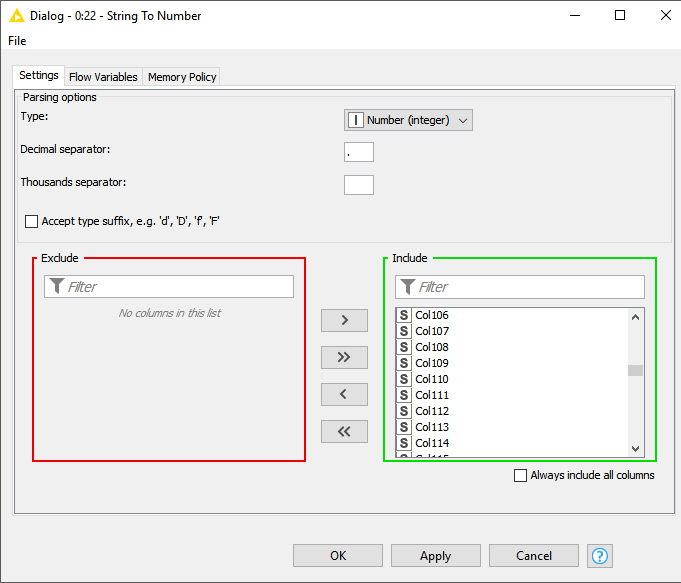
Use the String To Number node if your input table contains numbers that are of type String after the reader if these are really numbers and don’t encode some nominal feature.
E.g. revenue could be a true numerical feature but your error codes are actually a nominal feature encoded as numbers.
1 Like
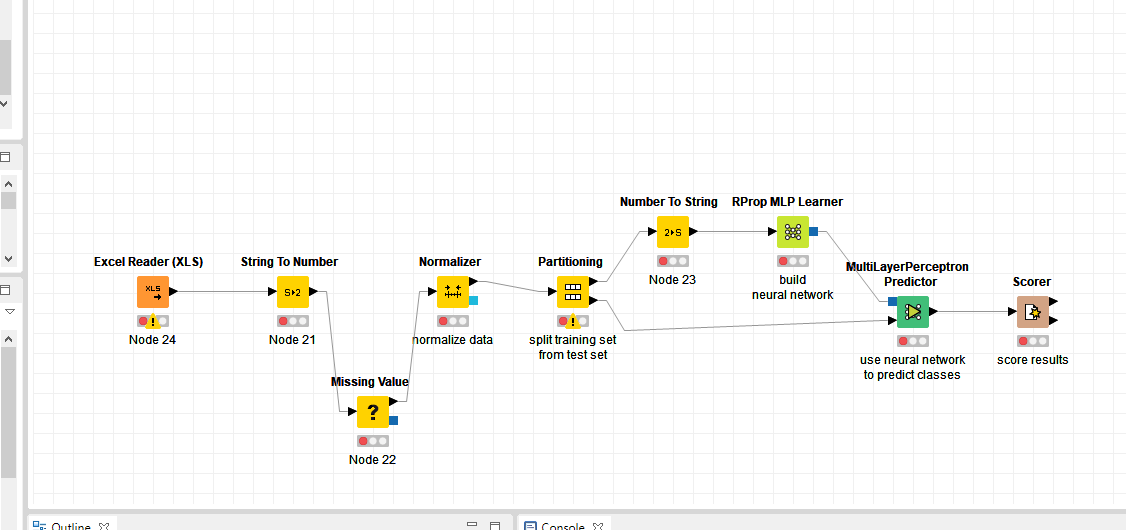
@nemad Really earned! The only thing is that only the values 1 and 0 are predicted. I tried to change the settings of the RProp Learner, but this does not help. Now I decided to separate the data. The first Excel Reader contains the data for training, and the second for the test. Do you know why there may be problems with the prediction of other values?
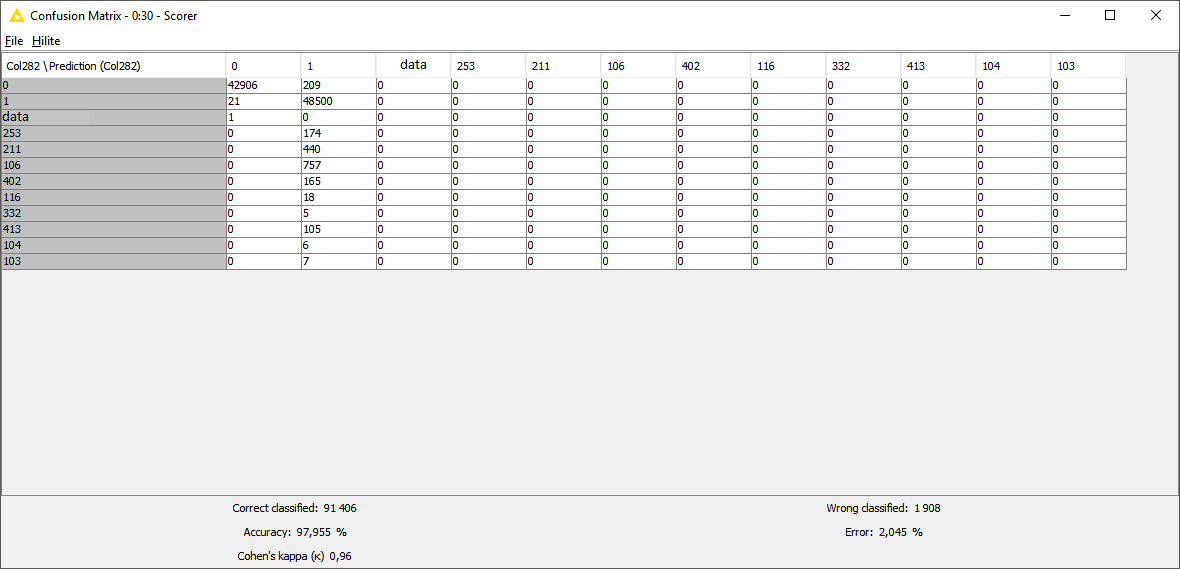
It looks like your data is highly imbalanced i.e. the classes 0 and 1 make up the majority of your training examples, consequently any model will learn that predicting one of the two is a relatively save bet.
Unfortunately, while this is a common problem, there does not exist a one-fits-all solution I could recommend you.
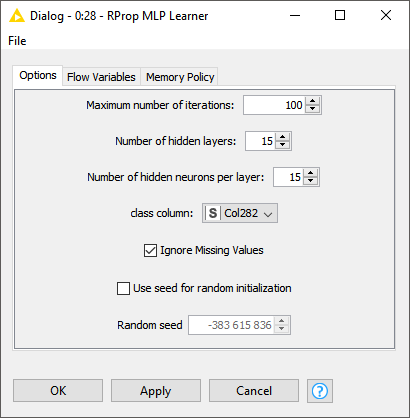
Regarding your settings for the RProp Learner: I would recommend to reduce the number of hidden layers to a value between 5 and 10 and instead increase the number of hidden neurons per layer to maybe 100.
However, these are just guesses based on my experience that might not work at all for your data.
Anyway, I have to reiterate that random forests and gradient boosted trees tend to be much easier to configure and often end up producing superior results for tabular data such as yours.
1 Like
@nemad thank you very much for your help! I have another question: what is normalizer for? And what will happen without it?
The normalizer ensures that the selected numerical columns (by default all of them) satisfy certain criteria depending on the configuration. The default normalizes all values between 0 and 1 i.e. all values in your numerical columns will be in the interval [0,1].
This actually might be the reason why your model predicts only class 0 and 1 because you inadvertently normalize it. You can solve this by making sure your target column is a String before you use the normalizer.
Back to your question: What will happen without the normalizer?
That depends on your model. In case of Gradient Boosted Trees and Random Forest there won’t be any difference since they are invariant with respect to feature scale.
Other models like neural networks and logistic regression are extremely sensitive to scale so it is quite possible that they won’t be able to learn anything without the normalization.
1 Like
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.