Hello,
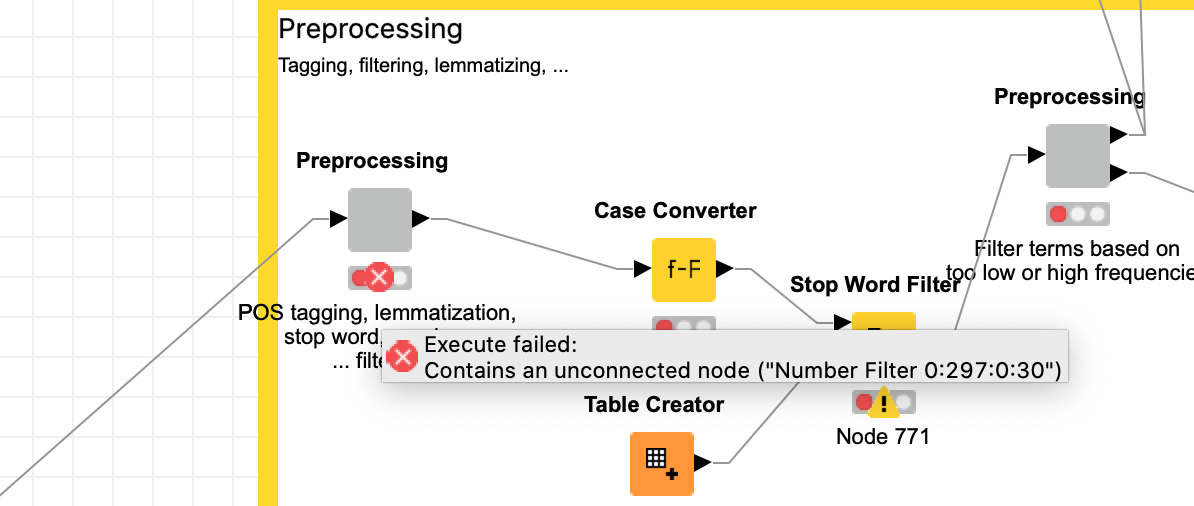
I keep on getting an error in the topic extraction workflow. I attached the screenshot of the error along with my workflow and would be glad if you can help me with that. Thanks!
topic extraction beg 1.knar.knwf (328.5 KB)
Hello,
I keep on getting an error in the topic extraction workflow. I attached the screenshot of the error along with my workflow and would be glad if you can help me with that. Thanks!
topic extraction beg 1.knar.knwf (328.5 KB)
Take a look inside the preprocessing component (which you can do by right-clicking and selecting Component --> Open, or by simply Ctrl-double clicking). You will see that as the error message suggests, there is a break in the workflow between the Stanford Lemmatizer and the Number Filter.
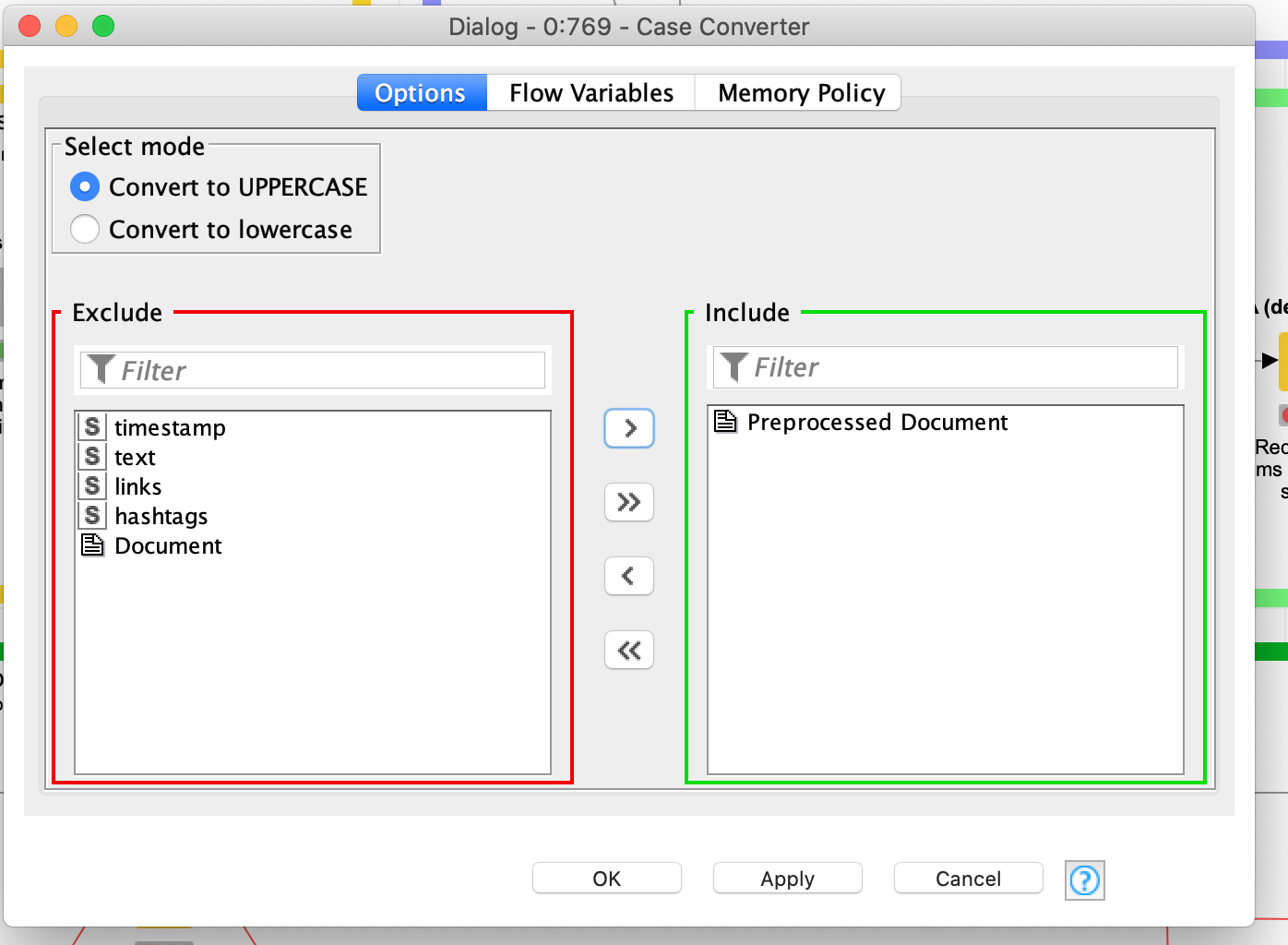
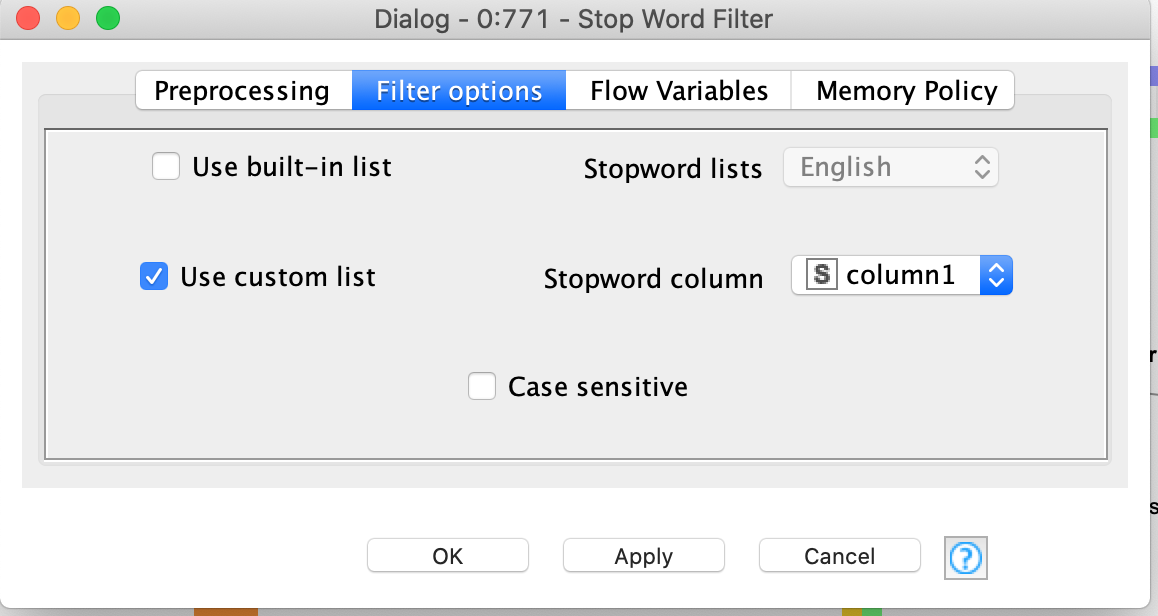
Oh thank you! I corrected it and now it is working however after the first preprocessing, now I am having problems with the case converter node. I want to include only the preprocessed document which I attached the screenshot but then after the case converter node, there is a stop filter node and it does not give me a choice to select the preprocessed document. I could only select “document” there and when I did that then I got error from the second preprocessed node. I attached the screenshots for those. I would be glad if you can help me with these as well.
It turns out that there are two Case Converter nodes - one for dealing with strings in KNIME data tables (from KNIME Core), and the other for handling text in documents (from the KNIME TextProcessing Extension). You want the latter:

Sorry for the confusion.
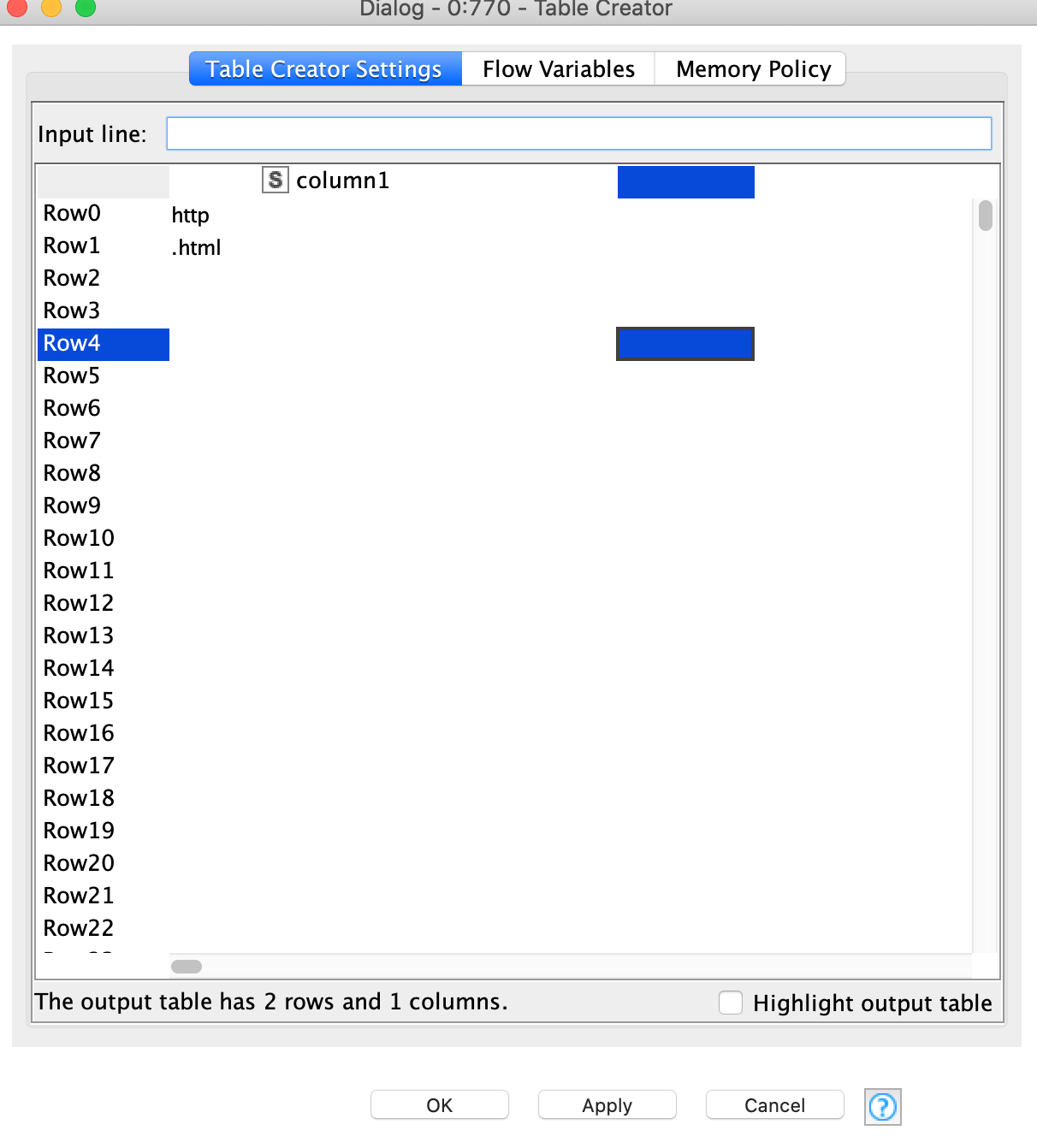
I see! I used the latter one but still having problems with the exclusion. I want to exclude two words “http” and “.html” in which both do not have meanings but occurring a lot in the document. However, even though I included them in the stop filter node, I am still seeing those among the topic terms. Not sure where I am doing wrong. I attached the screenshot along with my workflow. I really appreciate your help.
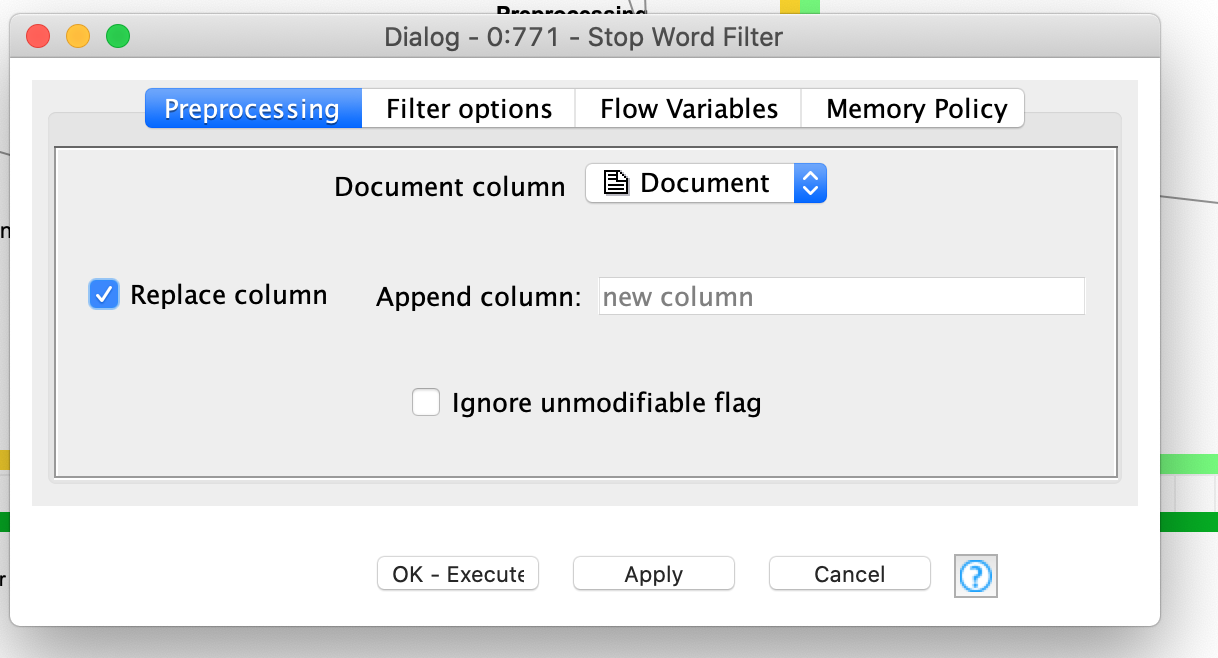
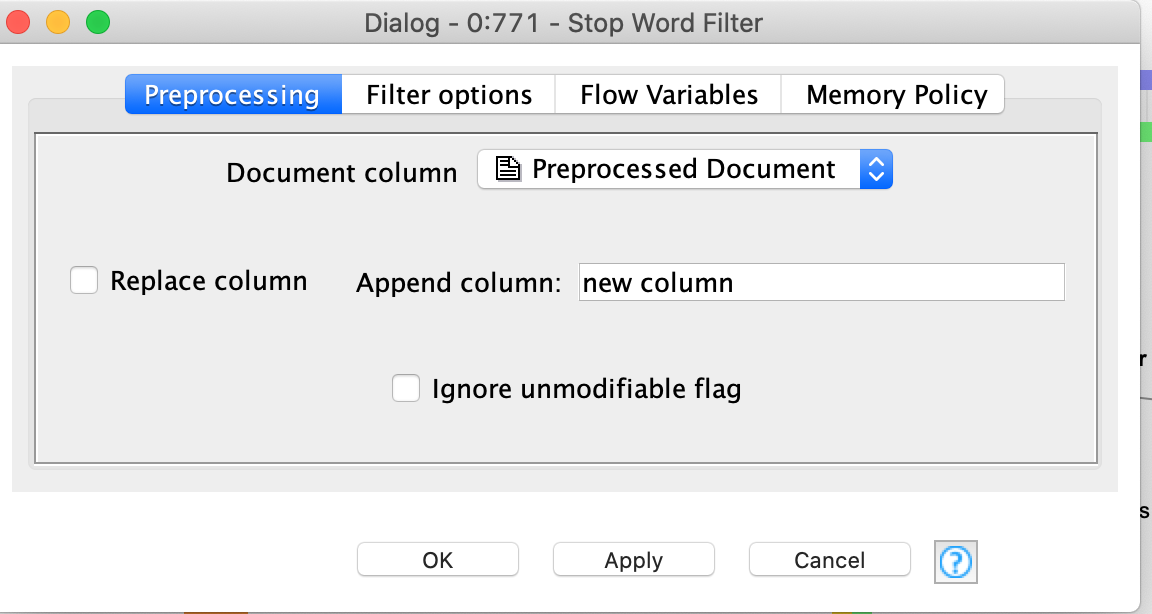
Looks like it’s because you are creating a column called “new column” in the Stop Word Filter. You want to replace the existing Preprocessed Document column instead.
Thank you very much! Now it works. I also have one more question related to this workflow. How can I create a tag cloud for each topic term? Currently, it is creating only one tag cloud and having few terms from each topic. Thanks in advance!
Here is the result data table from the final component. This is what you need, yes? Maybe you were looking at the interactive view of the component (which only shows one tag cloud at a time)?
Exactly, this is what I am looking for. Thank you! Is there a way to view this in a large format with a better image quality?
If you drag the edges of the rows/columns in the table shown above, the images will adjust in size to fit the space.
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.