KNIME Forum Archive
Excel Goal Seek function in KNIME
KNIME Analytics Platform
elsamuel
April 8, 2021, 4:45pm
5
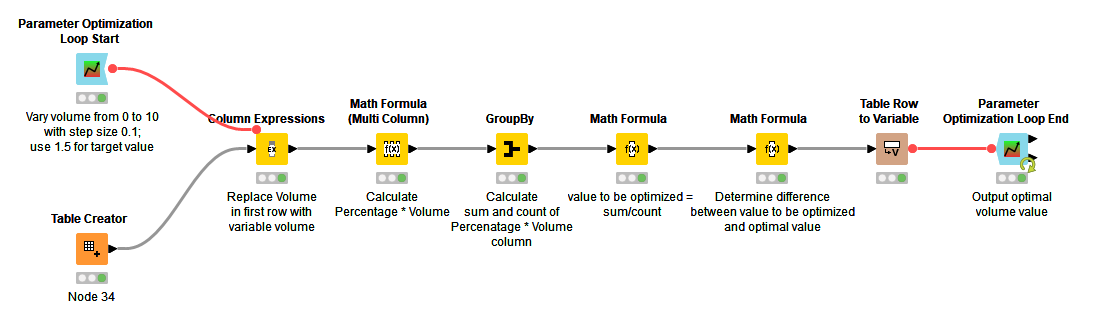
I think a simpler way to go is to use a Parameter Optimization loop:
image
1120×331 17.5 KB
4 Likes
Perform "Goal Seek" function in Knime
show post in topic