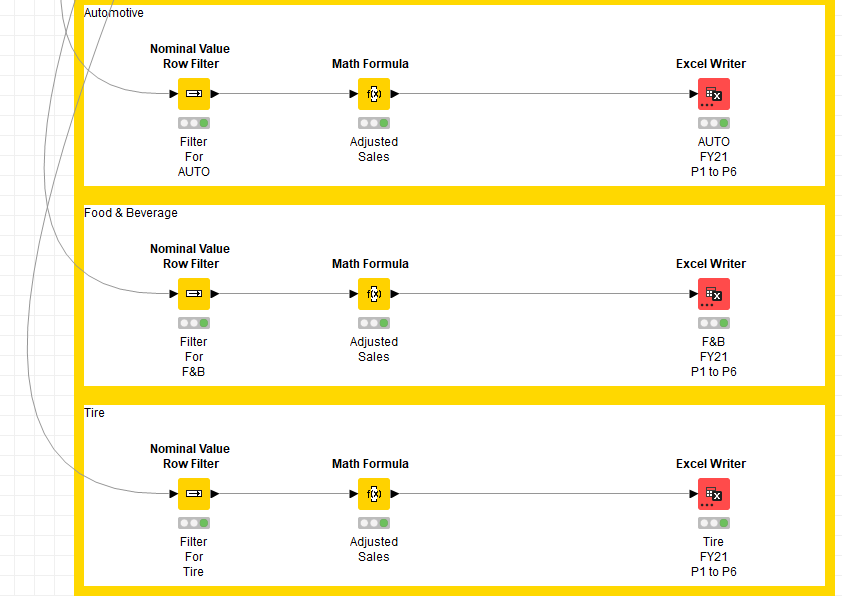
I am creating sales reports for a number of industries. All industries are processed the same way. An account is associated with an industry by a STRING (AUTO, TIRE, etc.). I am using a NOMINAL VALUE ROW FILTER node to filter on only the accounts for that industry. All industries work fine, except one (TIRE). The resulting Excel file is huge, and contains 6 tabs. What am I doing wrong?
You really haven’t given us much to work with here.
The resulting Excel file is huge
What does that mean exactly? More rows than you expected? More columns than you expected? Something else? These are different issues and could be a clue as to how the problem arose.
and contains 6 tabs.
Is this bad? How many tabs were you expecting? If there are more tabs than you expected, is there any data on the extra tabs? If so, what data is on the extra tabs, and where is that data coming from?
A screenshot doesn’t help much. Without a workflow, data, or even a glimpse at how the nodes are configured, it’s going to be very difficult for anyone here to figure out what might be going wrong.
3 Likes
I am expecting one tab. This one file is much larger than the other identically processed files. I apologize company sales data is pretty confidential.
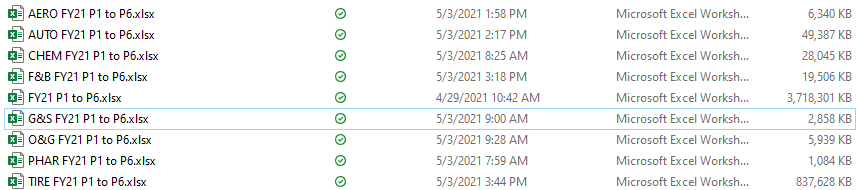
The tabs are duplicates.
Hi @Bob_Nelson , you are probably getting 6 tabs because you are calling the Excel Writer 6 times.
If you want only 1 tab, and all the data to be in that 1 tab, you should just concatenate your 6 results into 1 table first, and then write to Excel

Sorry @Bob_Nelson , I thought from your screenshot that these multiple Excel Writer were writing to the same file. I am assuming then that they are not based on what you said that you are calling the Excel Writer only once.
Can you share the Excel Writer configurations?
1 Like
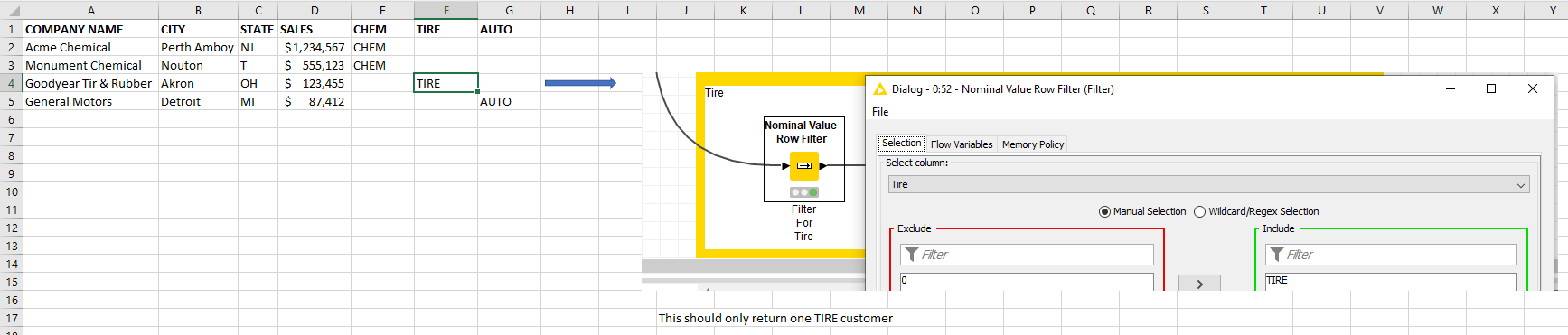
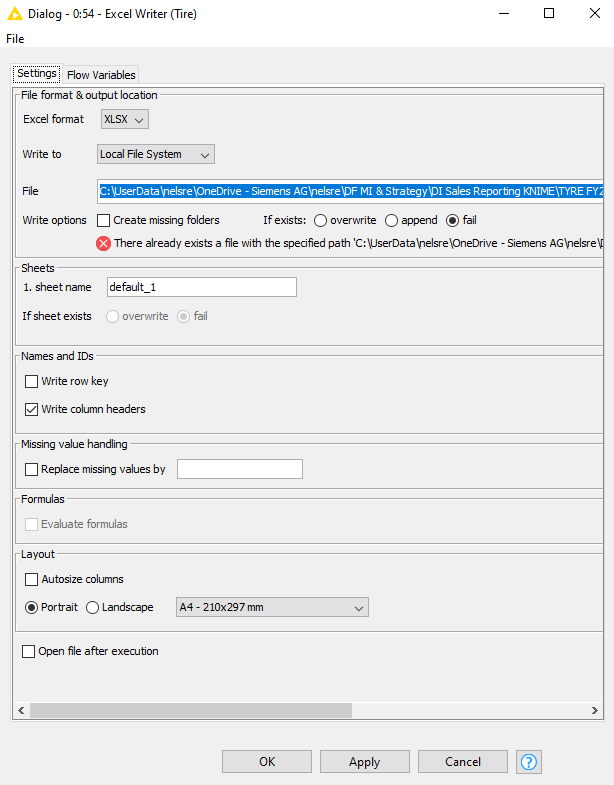
Config looks ok… if you open the node before the Excel Writer, does the data look as expected?
Also, can you check all of the Excel Writer nodes to make sure they are actually writing to different files and not adding new tabs to existing excel file? (This is what happens sometimes when we do copy/paste of nodes  )
)
All nodes are writing to different files. When I am the node before the EXCEL WRITER the data looks fine. I even changed the order, and the anomaly stayed with TIRE. I even tried changing the spelling to TYRE.
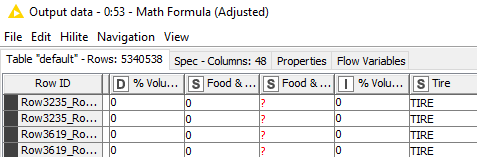
Thanks for additional info @Bob_Nelson . Based on your last screenshot, you have 5.34 million rows. I wonder if Excel Writer is creating additional tabs in case Excel cannot handle 5.34 million rows in 1 tab.
5.34 million rows an 48 columns, this is bound to create a big file (size-wise)
2 Likes
The raw data file has over 1 million rows (why I’m not using Excel). Of those, at most 100,000 are marked TIRE.
Your Math Formula node says that have 5.34 million rows with 48 columns. If this is the node before the Excel Writer, then it means you are sending 5.34 million rows with 48 columns to that Excel file, not just 100,000.
That’s strange. Food & Beverage has far less (should have more hits).
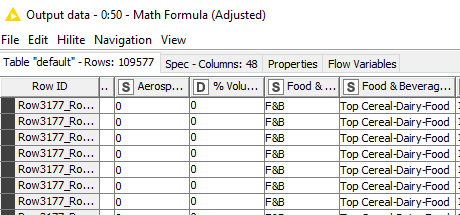
Based on the 5.34 million rows, it makes sense that you get 6 tabs if you are using Excel 2007 and above.
From this:
" * .xls format: This is the file format which was used by default up until Excel 2003. The maximum number of columns held by a spreadsheet of this format is 256. If the input data table has more than 65536 rows, it is split into multiple spreadsheets.
- .xlsx format: The Office Open XML format is the file format used by default from Excel 2007 onwards. The maximum number of columns held by a spreadsheet of this format is 16384. If the input data table has more than 1048576 rows, it is split into multiple spreadsheets."
5340538 / 1048576 = 5.09, which gives you 6 tabs
4 Likes
I think that’s what’s happening. The question is why. Why is only TIRE behaving this way?
Don’t forget, Excel Writer is just writing what it’s being given
It looks like it’s a data issue in your workflow.
If there are 8 industries, all with the same workflow, why are 7/8 behaving as expected, and 1/8 differently?