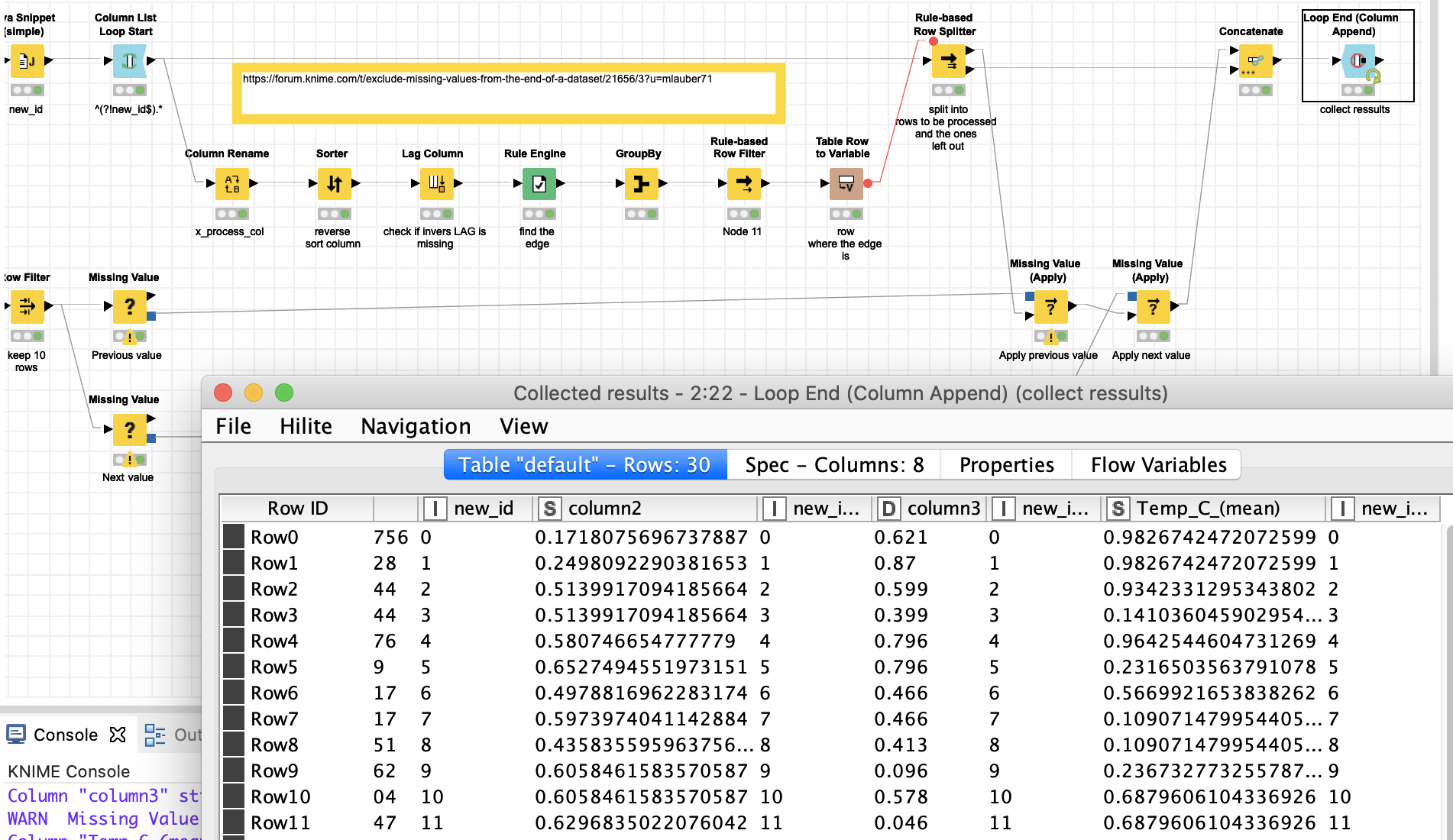
OK here comes the latest instalment. It should handle:
- column names with brackets
- it uses @HansS idea of column list loop start (much more comfortable)
- stores the Missing value rules in (non-standard) PMML and applies them to strings and numbers
- uses first the following value then the previous one if there are still missings in the non-empty lines
Please check if everything works and check if the order of Previous and Following is the one you want (otherwise switch the order).
Exclude_Only_Last_NA_values3.knwf (46.7 KB)