The project is as following:
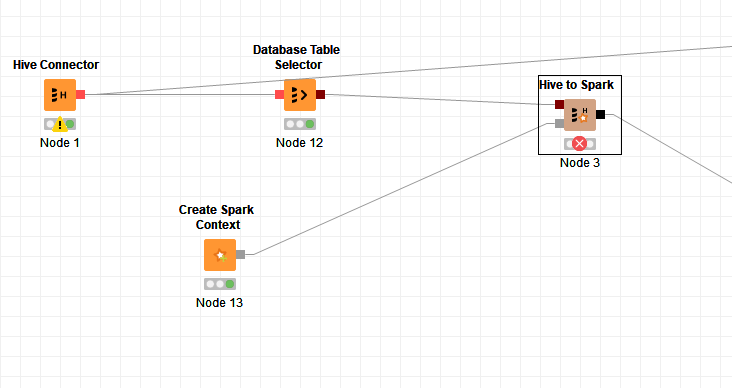
When I execute the “Hive to Spark” node,it throws an error as folloing:
2019-04-12 21:13:45,730 : DEBUG : KNIME-Worker-128 : Node : Hive to Spark : 0:3 : Execute failed: Table or view not found: wjzsy; line 1 pos 14 (AnalysisException)
org.apache.spark.sql.AnalysisException: Table or view not found: wjzsy; line 1 pos 14
at org.apache.spark.sql.catalyst.analysis.package$AnalysisErrorAt.failAnalysis(package.scala:42)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$.org$apache$spark$sql$catalyst$analysis$Analyzer$ResolveRelations$$lookupTableFromCatalog(Analyzer.scala:459)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$$anonfun$apply$8.applyOrElse(Analyzer.scala:478)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$$anonfun$apply$8.applyOrElse(Analyzer.scala:463)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan$$anonfun$resolveOperators$1.apply(LogicalPlan.scala:61)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan$$anonfun$resolveOperators$1.apply(LogicalPlan.scala:61)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:70)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveOperators(LogicalPlan.scala:60)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan$$anonfun$1.apply(LogicalPlan.scala:58)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan$$anonfun$1.apply(LogicalPlan.scala:58)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$5.apply(TreeNode.scala:331)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:188)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformChildren(TreeNode.scala:329)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveOperators(LogicalPlan.scala:58)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$.apply(Analyzer.scala:463)
at org.apache.spark.sql.catalyst.analysis.Analyzer$ResolveRelations$.apply(Analyzer.scala:453)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1$$anonfun$apply$1.apply(RuleExecutor.scala:85)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1$$anonfun$apply$1.apply(RuleExecutor.scala:82)
at scala.collection.LinearSeqOptimized$class.foldLeft(LinearSeqOptimized.scala:124)
at scala.collection.immutable.List.foldLeft(List.scala:84)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1.apply(RuleExecutor.scala:82)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1.apply(RuleExecutor.scala:74)
at scala.collection.immutable.List.foreach(List.scala:381)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.execute(RuleExecutor.scala:74)
at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:64)
at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:62)
at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:50)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:63)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:592)
at org.knime.bigdata.spark2_1.jobs.hive.Hive2SparkJob.runJob(Hive2SparkJob.java:52)
at org.knime.bigdata.spark2_1.jobs.hive.Hive2SparkJob.runJob(Hive2SparkJob.java:1)
at org.knime.bigdata.spark2_1.base.JobserverSparkJob.runJob(JobserverSparkJob.java:65)
at com.knime.bigdata.spark.jobserver.server.KNIMESparkJob.runJob(KNIMESparkJob.scala:24)
at spark.jobserver.JobManagerActor$$anonfun$getJobFuture$4.apply(JobManagerActor.scala:318)
at scala.concurrent.impl.Future$PromiseCompletingRunnable.liftedTree1$1(Future.scala:24)
at scala.concurrent.impl.Future$PromiseCompletingRunnable.run(Future.scala:24)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
It always says that table ‘wjzs’ can’t be found although we can find it by the way of spark-sql in the server directly. Why knime can’t?What should I do?