@AnthonyCREng I put this task to ChatGPT and this is the quick result after some small tweaking …
# you will have to install tesseract. On MacOS this would look like this:
# brew install tesseract
import cv2 # opencv
import pytesseract # pytesseract
import pandas as pd
# Read the image file
image = cv2.imread('image1.png')
# Convert the image to grayscale
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Apply Otsu's thresholding
thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)[1]
# Run Tesseract OCR on the image
text = pytesseract.image_to_string(thresh)
# Split the text by new line characters
lines = text.split('\n')
# Create a dataframe from the lines
df = pd.DataFrame([x.split() for x in lines])
# Print the dataframe
print(df)
# export the file to excel
df.to_excel('image1.xlsx', index=True, sheet_name='Sheet1')
This is the result you could then further use:
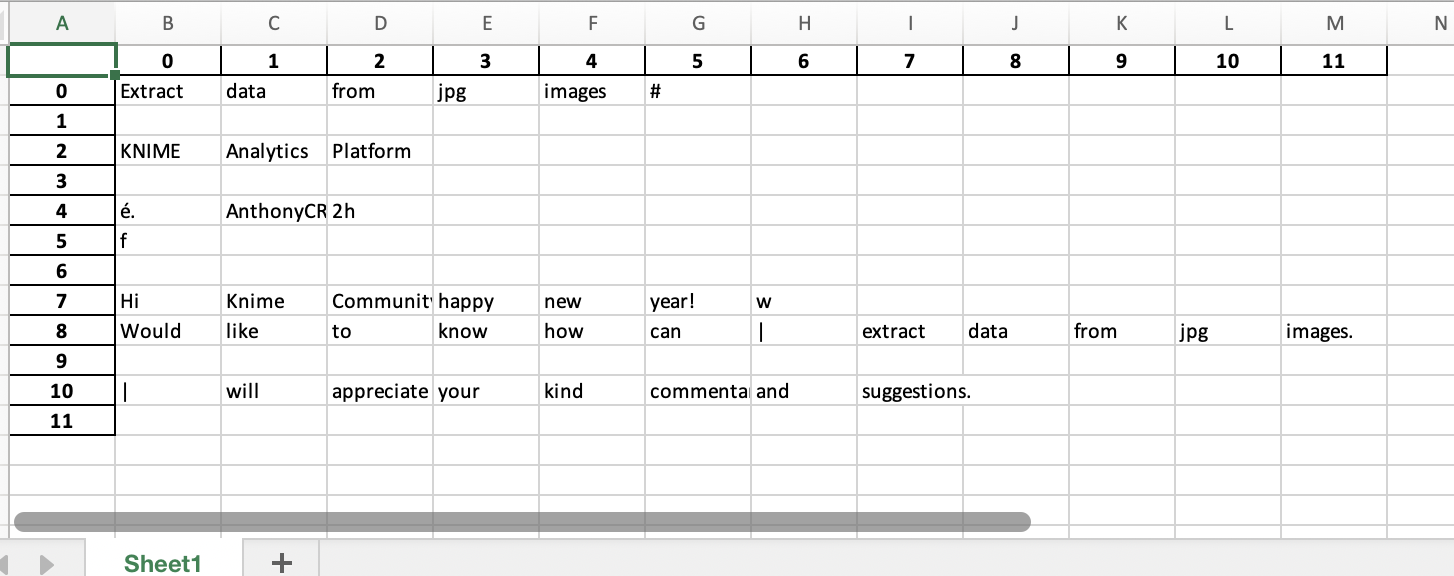
image1.xlsx (5.8 KB)
Will have to turn this into a KNIME workflow, maybe tomorrow ![]()