Hi @davehansen , that’s because it’s a CSV file, and csv file starts with a BOM character.
To overcome this, set encoding to UTF-8:
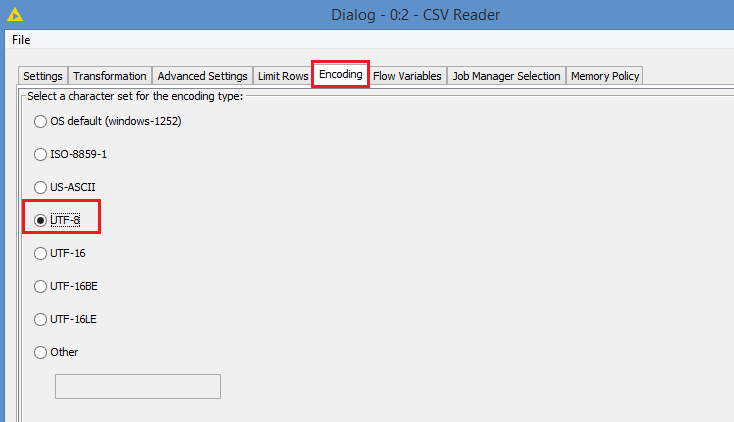
Same thing for File Reader
Hi @davehansen , that’s because it’s a CSV file, and csv file starts with a BOM character.
To overcome this, set encoding to UTF-8:
Same thing for File Reader