This workflow is, let’s say, L2 KNIME level where it is needed to use loops and variables.
The word $${SWords}$$ means variable Words, which appears in the “Flow Variable List”. It is named with an S character at the beginning to indicate that it is of type String.
The variable $${SWords}$$ is created by the -Table Row to Variable- node and it provides as a variable to the -String Manipulation- node the word to be replaced at every iteration of the recursive loop.
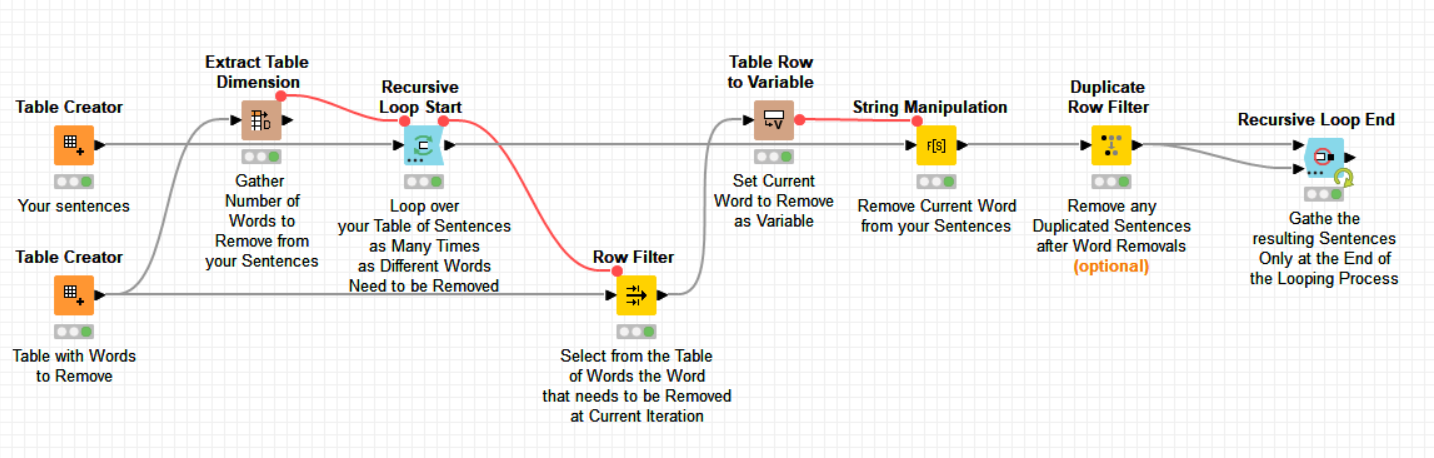
A recursive loop is needed because I guess you need to eliminate ‘ANY’ word appearing in your table of words (2nd Table) if several words to eliminate appear in the same sentence. The recursive loop injects back the same table of sentences into next loop iteration, and at every new iteration, a word is checked and eliminated. So for instance, ‘new york’ is eliminated in first iteration from your sentences and once this is done, then ‘paris’ is eliminated from those updated sentences in the second iteration. And so on so forth until all the words of the table of words are checked. The final number of iterations is necessarily the number of words to check, and this information is gathered by the -Extract Table Dimension- node.
Eventually, all the sentences are tested for all the words.
Hope it is clear. Otherwise, plese reach out again for further help
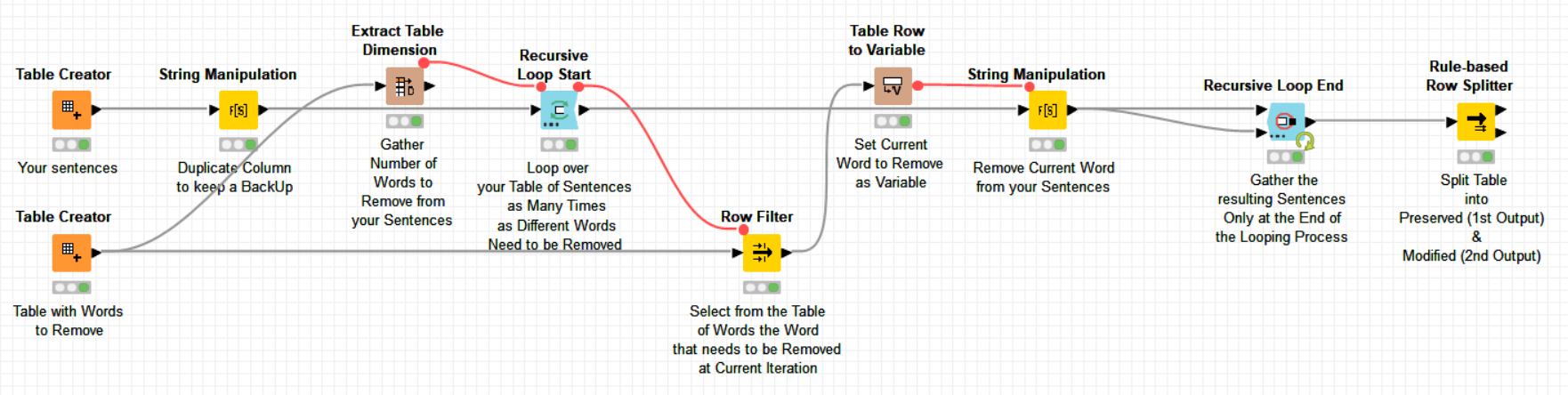
Sentences are not really filtered out. What are filtered out are words from sentences. If you remove the -Duplicate Row Filter- node, the sentences at the beginning and at the end will remain in same number and position. If you duplicate the column of sentences at the beginning to keep a trace of the "initial sentences before changing, you will be able at the end of the process to check which sentences have changed and which are those that haven’t.
I let you do it as exercice while I do it on my side to eventually upload it here
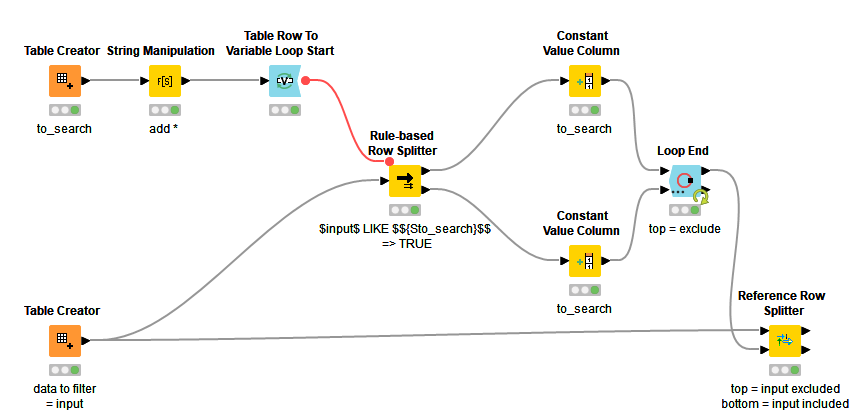
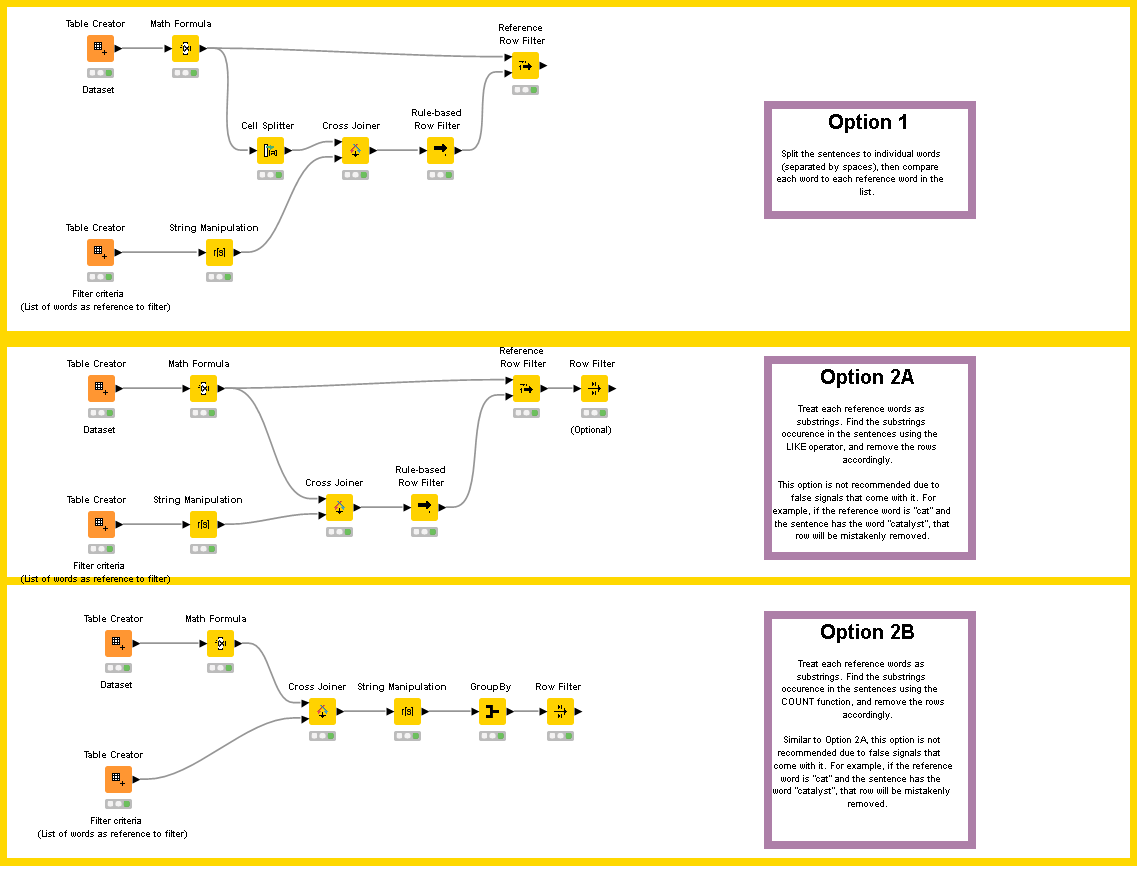
This can be done without loops using the Rule Based Row-Splitter (Dictionary). It is my standard approach since additional criteria can easily be added to an existing process when necessary.
Hello @phil21oo
Have you already had a look search in forum?
I would follow an approach similar to this one based in Regex, as you can easily deal letter case… You can avoid of using loops as well.
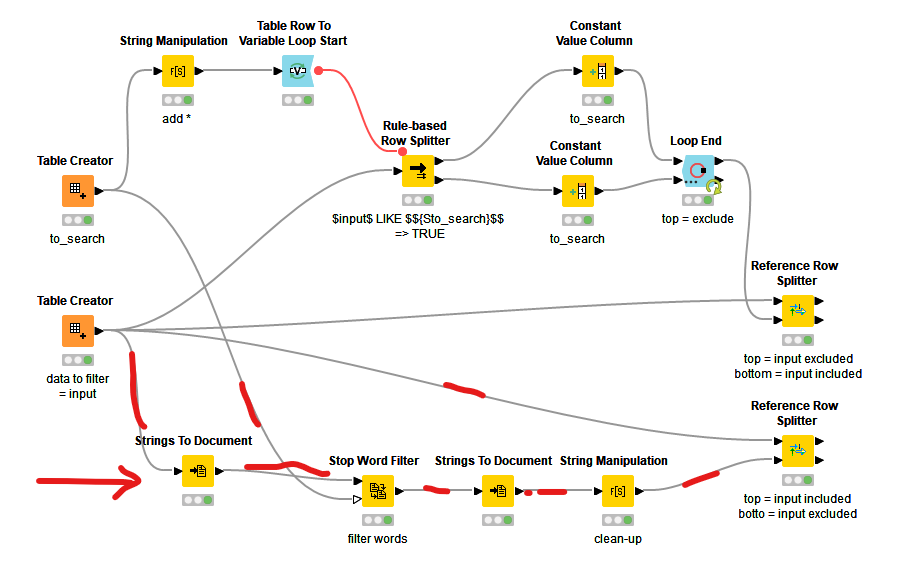
Interesting dicussion, I added an alternative to my wf filter_out_rows.knwf (79.4 KB). I think I can be done much easier with no loops, but making use of the KNIME TextProcessing nodes. I used a StopWord filter to filter out the words. And by using the ReferenceRow Splitter you have both the modified and unmodified records.