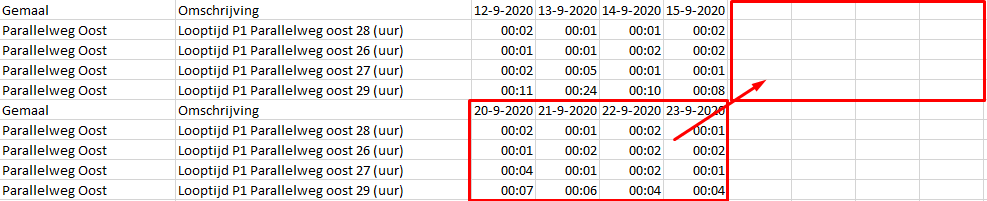
I have a csv file with a number of rows. After several rows there is a new header with new values. Is there a way to transpose these values to columns. I have tried with a chunk loop in combination with a group by, but it is not working. Is this possible?
1 Like
I have tried with a chunk loop in combination with a group by, but it is not working.
What does this mean exactly? In what way(s) is this not working? What result do you get?
How many rows are there total?
How many new header rows are there?
I think that the simplest approach would be to use multiple CSV/File readers, each one limited to a “chunk” of rows. You can then join all the resulting tables.
It might even be easier to modify the CSV file before reading it into KNIME.
Hi @havi1970
is it possible to upload an example file? That makes it easier to come up with a solution.
My first thoughts:
-
give each group starting with key word ‘Gemaal’ an id number (first 5 records have ID=1, next 5 records have ID=2 and so on.
-
loop over those groups
- transform 1st row to column header
- unpivot the data with retaining column ‘Gemaal’ and ‘Omschrijving’ (Enforce inclusion) annd the date columns as Value columns (Enforce exclution)
- after loop over the whole table (end loop node) use pivot node to transpose the values.
BR
This is what I mean, but then al the new rows start met new columns. The file has about 10000 rows, but can be larger, depending on the date range.
Hi @havi1970
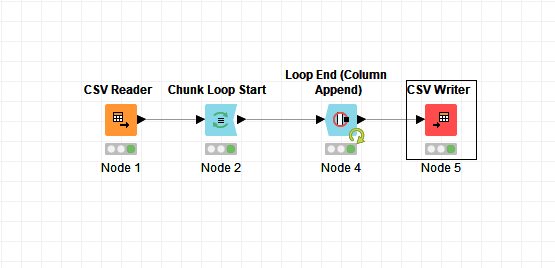
this is an example flow. I recommend to read your excel file without column headers and convert your data in knime if necessary for e.g. sorting. You also should keep in mind that your last entries are not complete and causes problems. But this should be manageable.


BR
Example.knwf (85.7 KB)
3 Likes
Thanks a lot, I will try it today! 
This topic was automatically closed 182 days after the last reply. New replies are no longer allowed.