Thank you for using my example with H2O.ai and Spark. You will have to connect the MOJO File (Reader) to a compatible model from H2O. At the moment they connect to a classification model.
As far as I can see MOJOs for Dimension reduction are not yet represented with individual KNIME/H2O nodes. It might be possible to import such model from R or Python implementations of H2O. I would have to investigate.
It should be possible to build a wrapper for KNIME like I demonstrated for H2O’s AutoML.
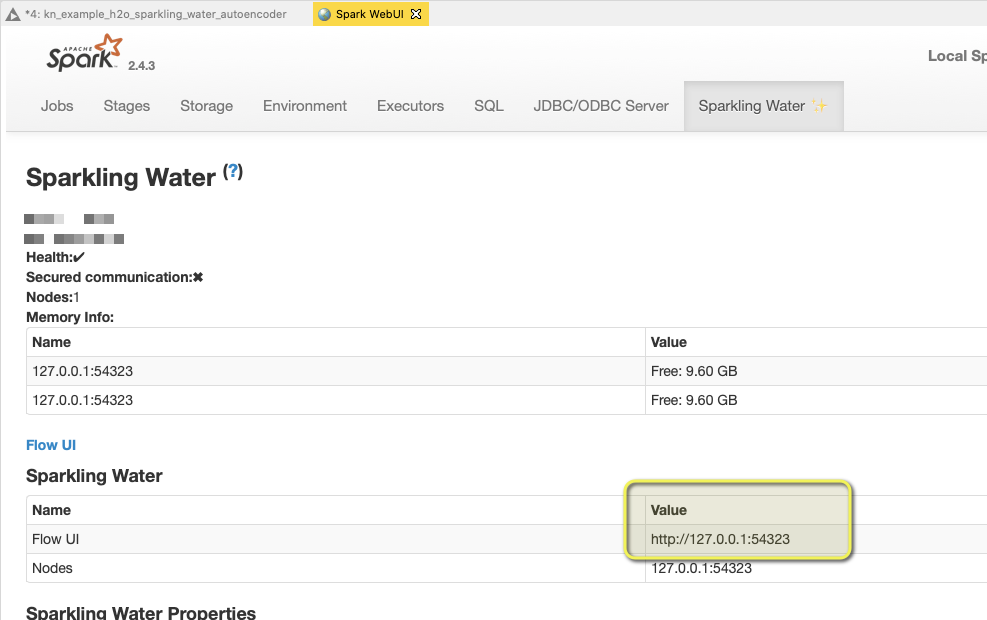
Regarding your other question. If you check the context of the local big data node with right click it will provide you with a link. There is also a tab with Sparkling Water information. But unfortunately I was not immediately able to open the GUI.