I am looking at a colleagues workflow that was written using Alteryx and I want to convert it if possible to Knime to see if there is the possibility to change some of the workflow into an Loop for ease of use.
I looked at quite a few of the examples and videos but most seem to have only one looping feature where as I think I have 2 separate data loops needed.
The Data is coming from the SAP systems which is a set of nested “folders” and "objects wtihin folders
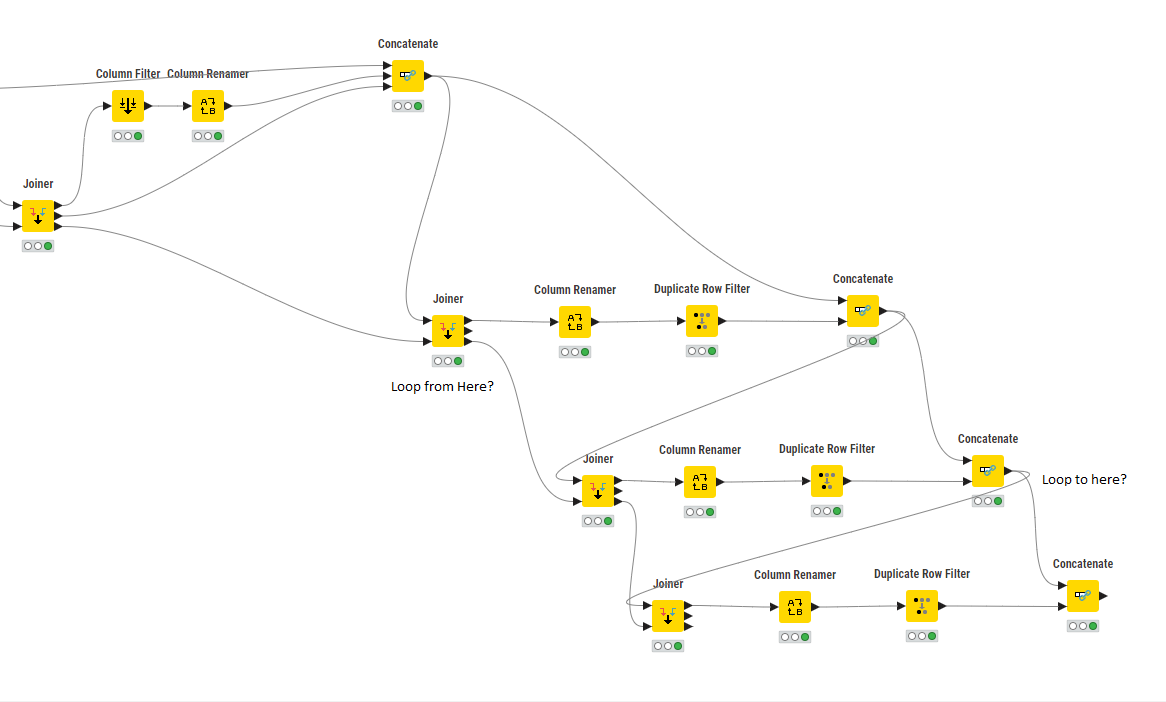
The workflow takes the input data from the first Concatenate and does a filter against the output of the previous Joiner node Right Unjoined output
From this Joiner node- The joined data is then added to a new Concatenate and the output of this Concatenate becomes the new input to the next Joiner nodes Left input, and the previous Joiner nodes Right Unjoined data is then the next Joiner nodes Right input.
This continues until the Joiner nodes Join Data is empty. When this occures the Data set in the last Concatenate is passed on to the remainder of the workflow for further analysis.
Can anyone shed some logical light on making this loop into an Interactive macro ?
Unfortunately due to company policies I cant share the data or the full Alteryx workflow.
Do I understand it correct that your main data set is joined with different data sources until every item has been matched or all your sources have been “tried”?
If so a set up with a recursive loop may help where you define the end of recursion via flow variable - you’d have to check two conditions each iteration:
from what you shared, this looks like a case for Recursive Loop Start – KNIME Community Hub and Recursive Loop End – KNIME Community Hub.
Add a second port to the Start node. Connect the two ports to the inputs of the Joiner.
Also add an additional port to the End node to feed the non-joined rows back to the start of the loop.
I think Martin that the criteria is number 2, All the Join Sources are Exhausted
The core data is extracted from multiple SAP tables with multiple Joins containing SAP objects related to use of many applications.
If I understand correctly, what the workflow is doing is
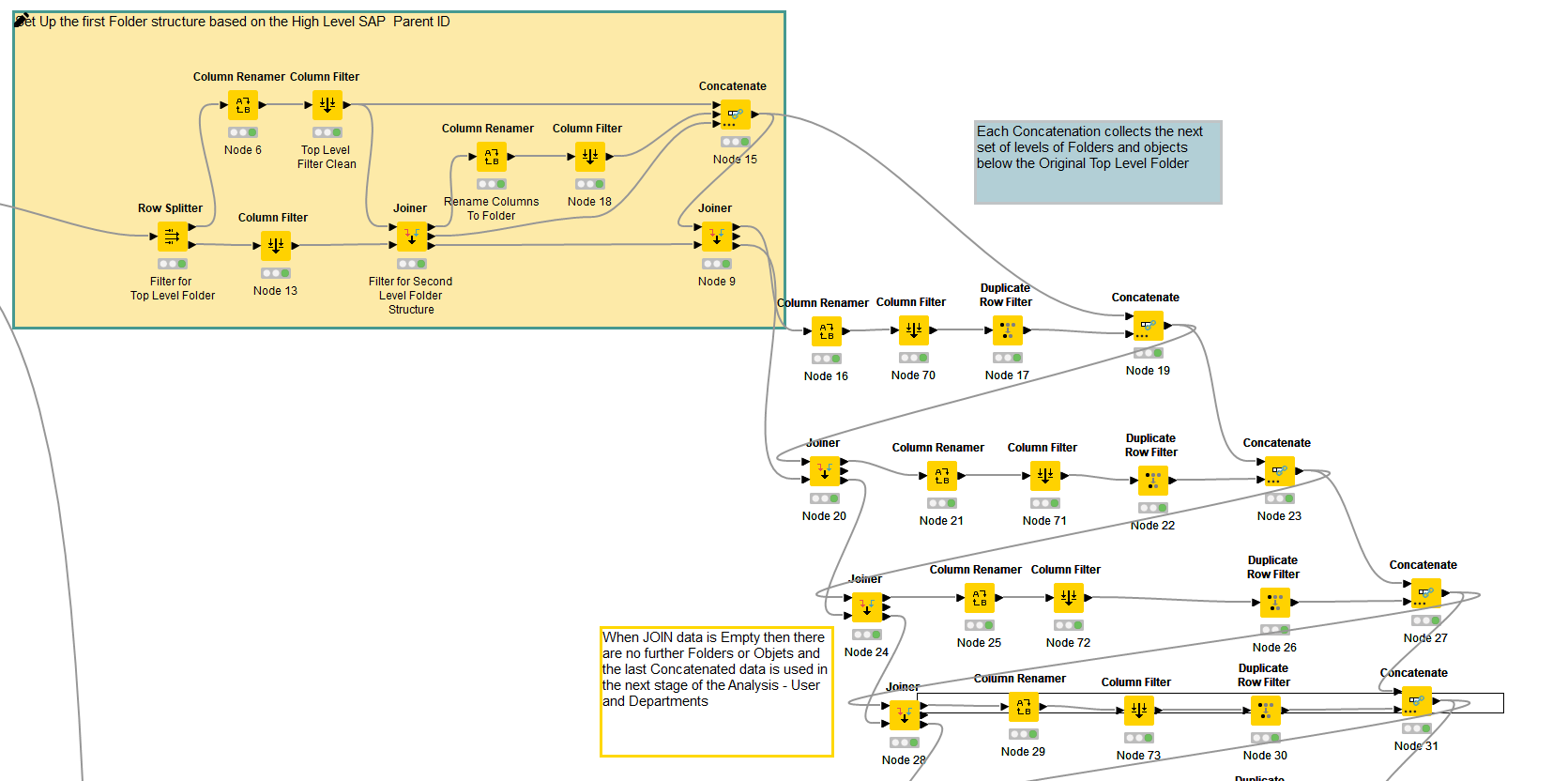
With the a first Row Splitter (Highest level Folder ID) it is filtering a list of related Next level Folders IDs,
This is then used to interrogate the data again to find the next level down in the folder structure and so on until there are no further related folders and the Joiner Node “Join” output will be empty.
The concatenations are keeping the records of all the found objects in the workflow
So we have aprox 50 thousand rows in the original SAP file dump and we end up with aprox 2900 “foldes and objects” at the end of the workflow
I would love to provide some dummy data, however its SAP object data ( such as E1391659C22C7C24E10000000A6C9945) which is complicated to understand with regards to obvious connections. I am def not any expert on how SAP data is related.
Perhaps this is a clearer view of the Workflow and where the looping is happening
Sorry I’m not a SAP expert either, only a StAmPs colector
With false data (dummy) I meant an example like
Input 4 lines
“Aa”
“Aa\Bb”
“Aa\Bb\objA”
“Aa\Bb\objB”
Output 4 lines
“Aa”
“Bb”
“objA”
“objB”
or similar.
That would really help us.
Hi - Sorry for not replying earlier, but I asked a colleague to put together some dummy data that might help, as the actual SAP data definetly requires subject knowledge. I attached what he provided so I hope this helps . . . . knimeDummy.xlsx (12.2 KB)