@hhkim it might not help you in this case. But with the Parquet file format and the Parquet writer you could write out large data in chunks of your own choosing (and would have a fast compression with “snappy” at hand also).
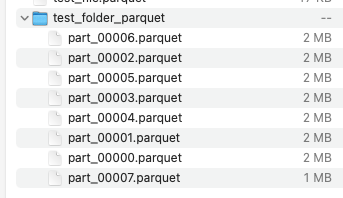
You could (and should) change the values about the size of the chunks. The 2 MB is just for the example:

The data would then look like this. The single files could be used as individual files and they would have the additional benefit of storing the column types and have compression:
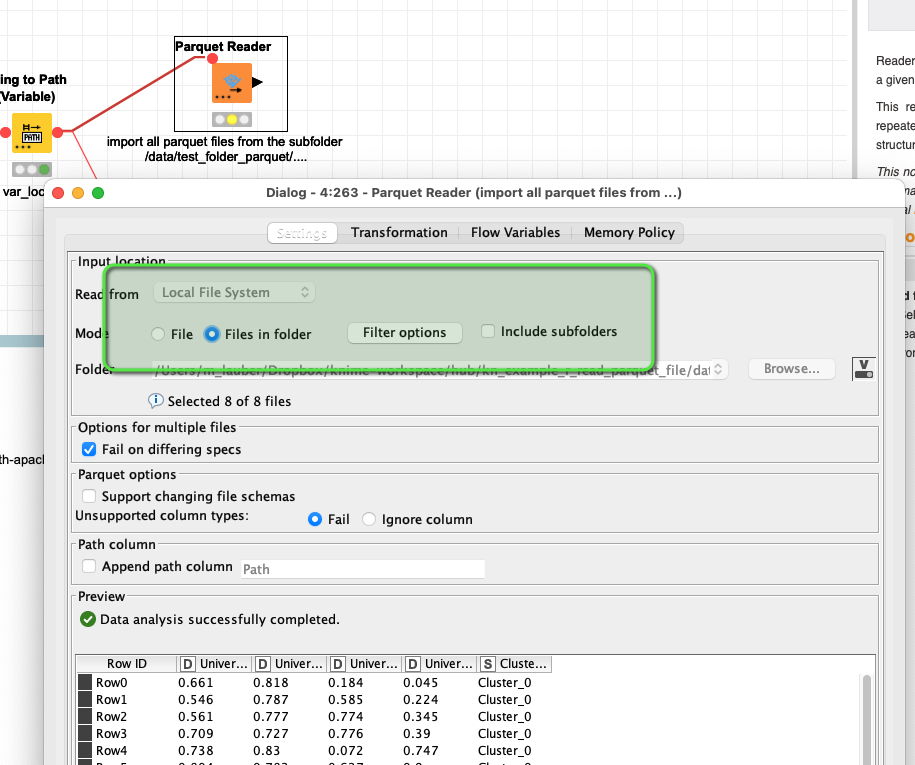
You could later read the files back in one single step:
This example is about R and Parquet but you can just use the part about Parquet with folders: