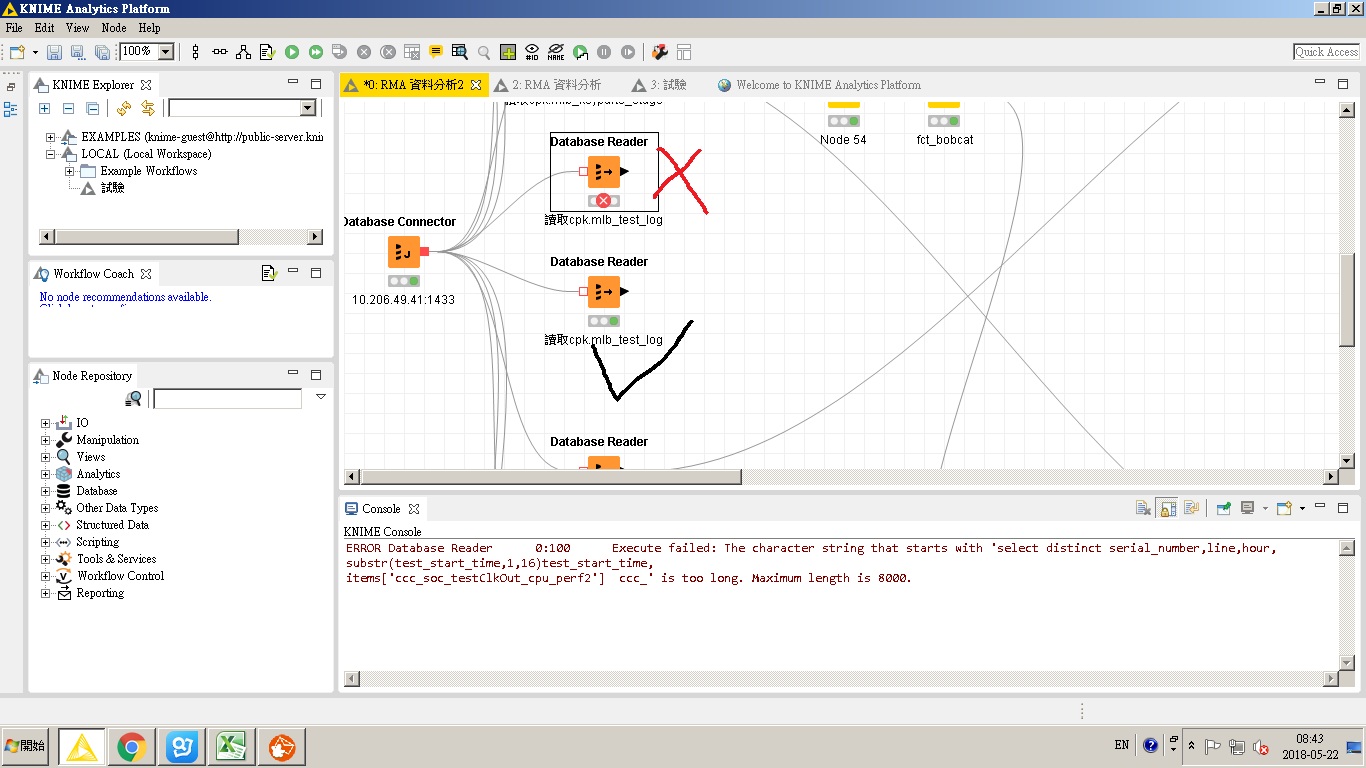
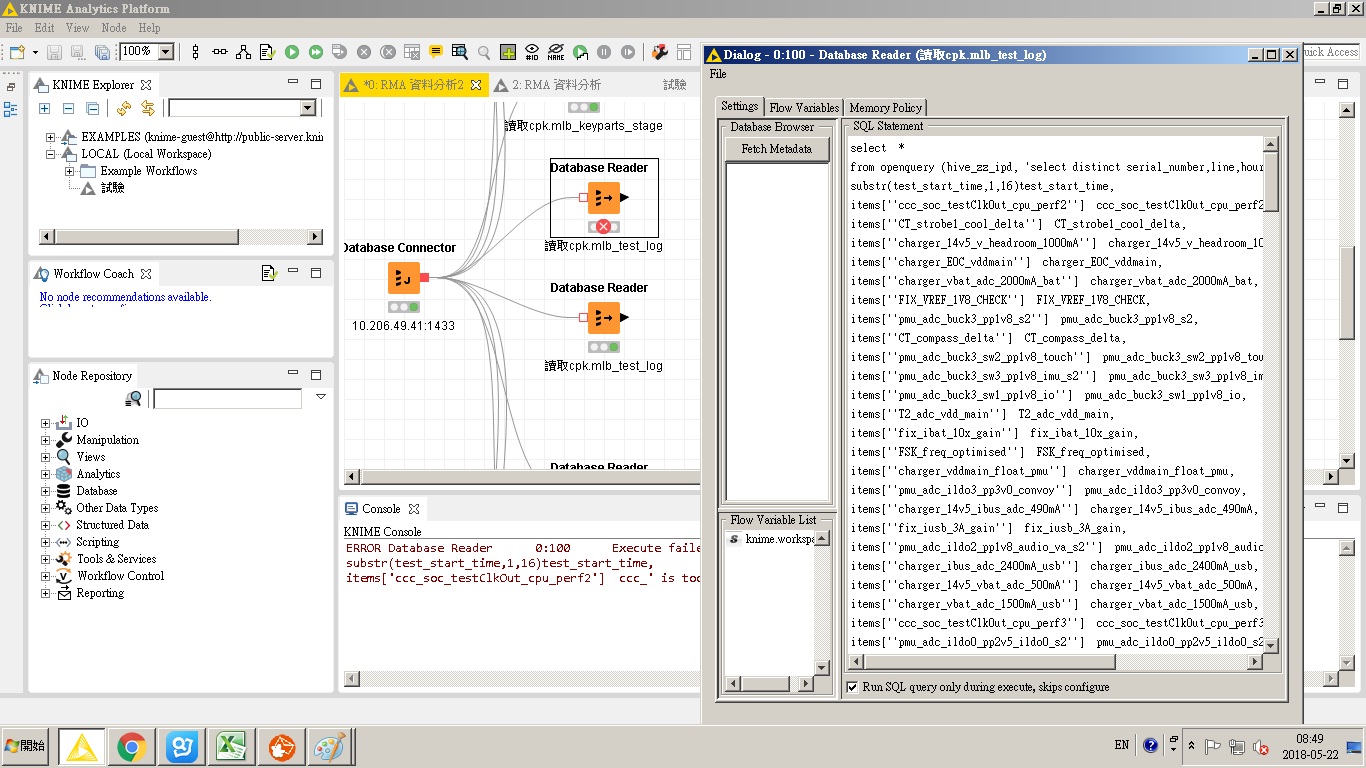
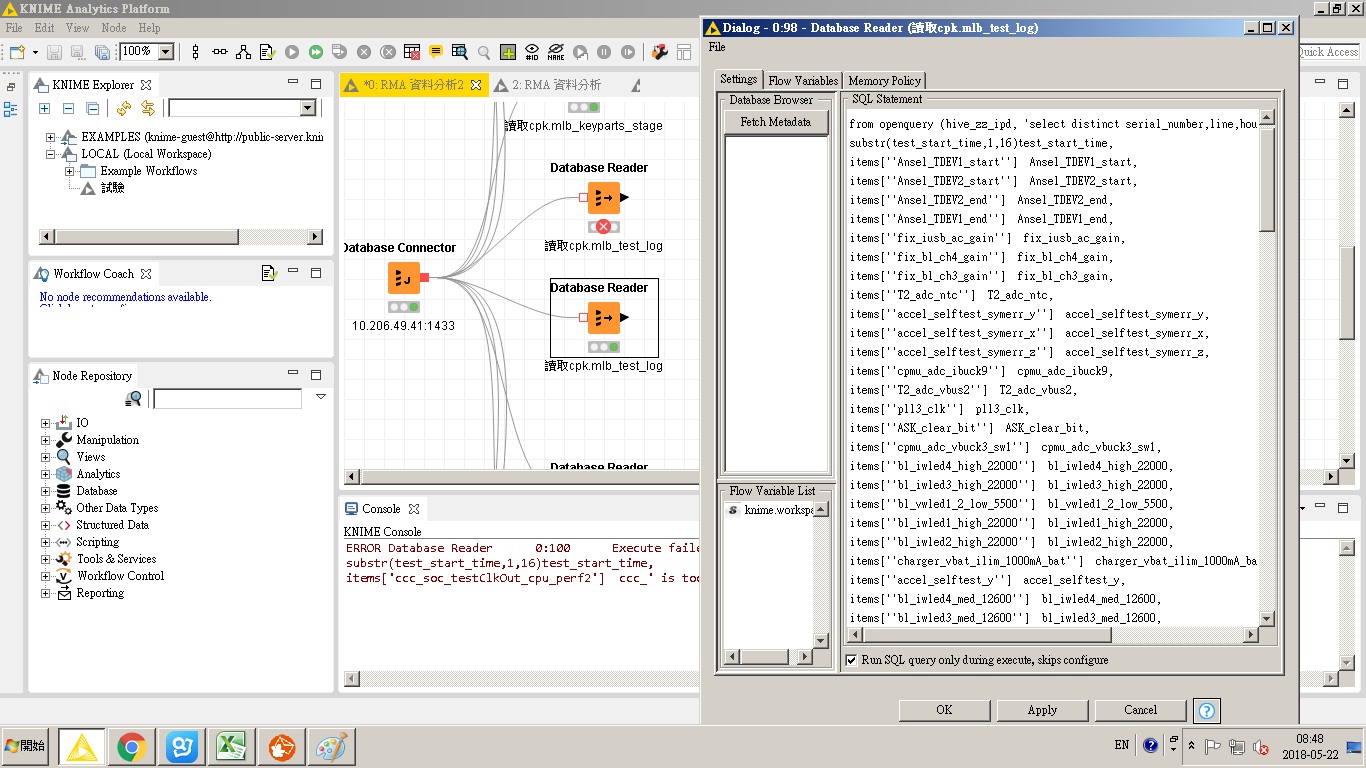
I encountered a problem When reading the database,It seems to be about the Maximum number of columns:
ERROR Database Reader 0:100 Execute failed: The character string that starts with ‘select distinct serial_number,line,hour,
substr(test_start_time,1,16)test_start_time,
items[‘ccc_soc_testClkOut_cpu_perf2’] ccc_’ is too long. Maximum length is 8000.
Hey @irving-ccc,
please give a little bit more insight. Ideally, upload the workflow or a screenshot.
Especially, please tell us:
- Is " ‘select distinct serial_number, line, hour, substr(test_start_time,1,16)test_start_time, items[‘ccc_soc_testClkOut_cpu_perf2’] ccc_’ your query or part of the result?
- What DB do you use?
- There is no “,” after the substr-expression. Intended or in error?
Kind regards,
Patrick
Patrick:
Thanks for your support!
The following are answers to your doubts:
1.‘select distinct serial_number, line, hour, substr(test_start_time,1,16)test_start_time, items[‘ccc_soc_testClkOut_cpu_perf2’] ccc_’ is part of the my query ,This result is based on my query,so some of them are the same.
2.the DB queried is hadoop,
3.There is no “,” after the substr-expression.It is a way to omit the’‘as’’.
substr(test_start_time,1,16)test_start_time=substr(test_start_time,1,16) as test_start_time
best regard!
irving
Hey @irving-ccc,
thanks for your swift response. Based on the error message, it does look like that the query itself is more than 8000 chars long - please check this one.
If it’s the case (i.e., query longer 8k chars), the only solution I can think of is checking hadoops manual on limitations or check the db-connectors limitations.
Kind regards,
Patrick
Patrick:
Thank you for your time and helps!
I will keep looking for other ways to solve this problem.
best regard!
Irving