Hi,
I meet a challenge to classify a highly unbalanced dataset, where False type data are only round 1% of total dataset. I have tried SMOTE over-sampling but it didn’t solve the problem.
Thanks in advance for your helpful answers!
BR
iperez
April 5, 2021, 1:12pm
2
Hi @Meihong . I’ve used the SMOTE node. It works well but heavily increases the computation time.
1 Like
What does your workflow look like? Build in python or all in KNIME?
@Meihong you could take a look at this debate
@w0rdz this really sounds like an unbalanced dataset and it could be difficult to come up with a perfect solution. It may well depend on the strength of the ‘signals’ that are within the data and how they are correlated to what you want (unfortunately in a lot of cases the signals are not that strong otherwise some simple rule might work.
You could check out the [unbalanced] section of this machine learning collection with some links and discussions.
Then one idea could be to explore Kaggle …
3 Likes
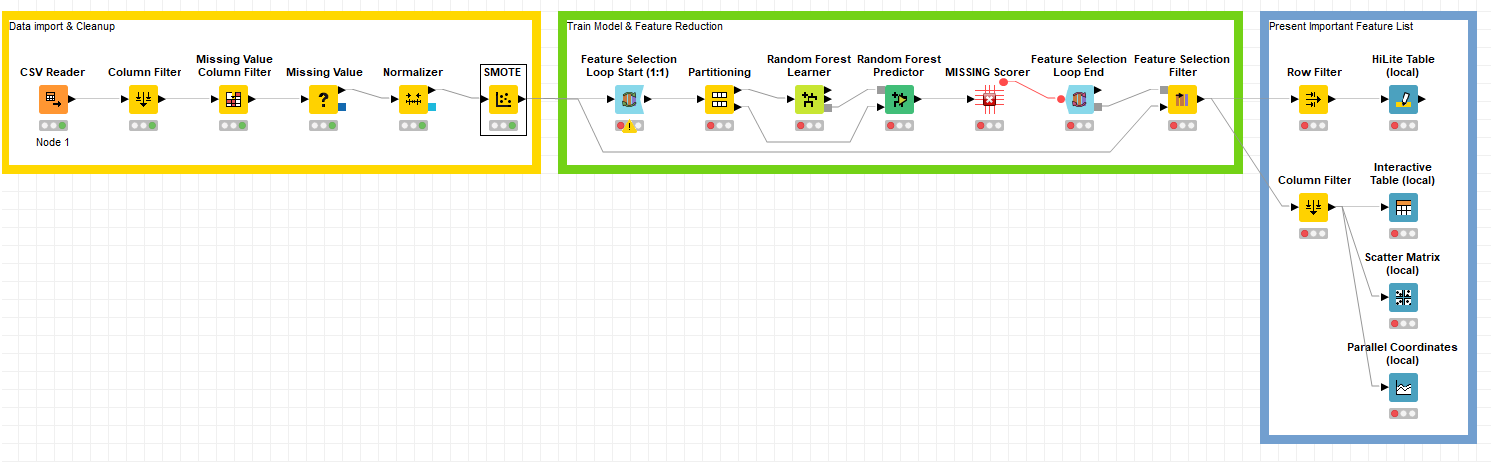
It build in all with KNIME node.
The purpose of this task is to find the key feature which cause the fail.
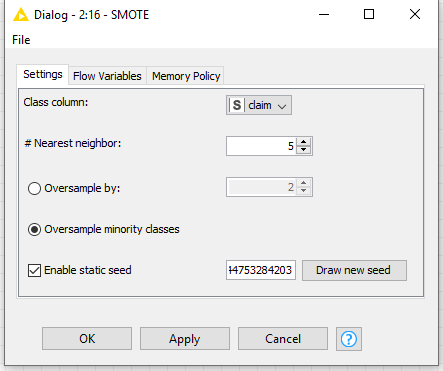
Is that because the settings that I made for SMOTE are not suitable? This is what I used in SMOTE now
Is that Tomek link doesn’t have node in KNIME? We need to use Python to build it?
iperez
April 7, 2021, 12:17am
8
No those are reasonable values for the parameters. The issue must be the signal is weak as explained by @mlauber71 in the thread
ipazin
April 7, 2021, 1:22pm
9
Hello @Meihong ,
To my knowledge there is no dedicated node in KNIME to perform Tomek Links method to do undersampling. Python is probably a way to go.
Adding link to KNIME Python integration guide in case you don’t have it configured and not aware of it:https://docs.knime.com/latest/python_installation_guide/index.html
And link to new blog post with steps on how to configure it fast and easy:
Br,
3 Likes
system
October 7, 2021, 1:23am
10
This topic was automatically closed 182 days after the last reply. New replies are no longer allowed.