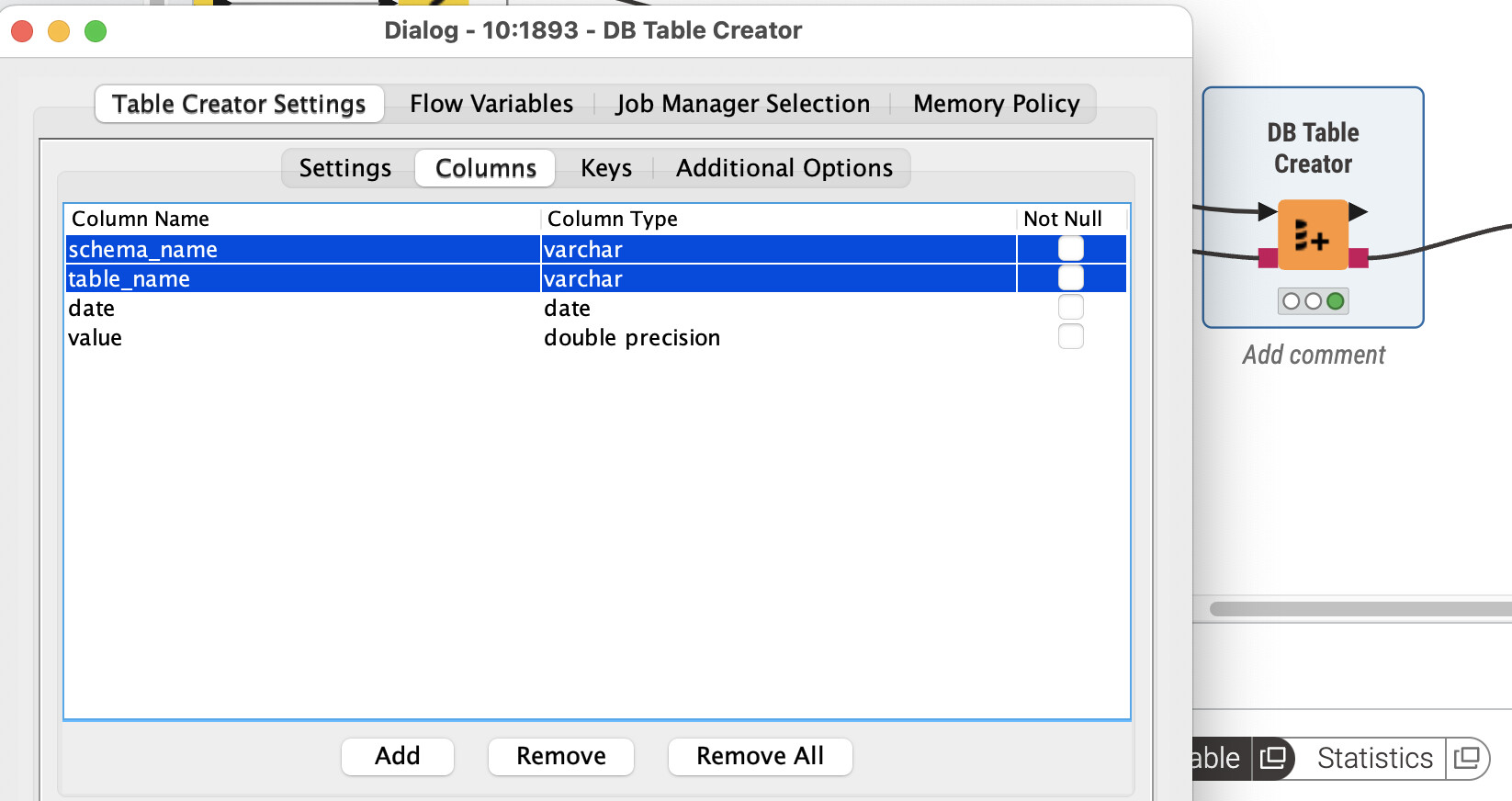
The error was in the syntax of that SQL snippet, I have since fixed it but still no PK is being added.
The error was in the syntax of that SQL snippet, I have since fixed it but still no PK is being added.
Do you have any further info re the above? thanks.
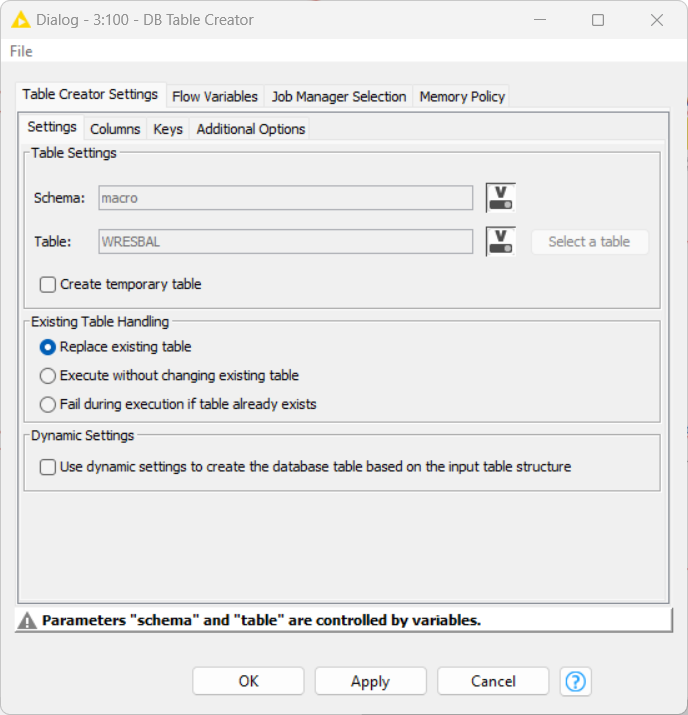
I did not change any default config anywhere. You can see the relevant screenshots above or tell me what you would like to see.
@dataHoarder your schema does not have quotation marks BTW
@dataHoarder can you try and run my example on your database maybe with another name of the schema and show us a screenshot of the results in the configuration of the database if you have access to a Postgres GUI.
@dataHoarder , Can you upload a workflow containing an example of what you are doing, with some representative dummy data, the postressql connector and the loop which demonstrates the problem. Make sure it can be executed against your database, then remove the database host details & password and upload the workflow here.
In all my own attempts at reproducing what you say you are doing it always creates a constraint, and when requested always creates a pk, so it’s really difficult to remotely suggest what it is about your setup that doesn’t work. I need to be able to execute what you’re executing and see what happens on my db.
I’ll take a look through at mine using DBeaver later to see if that makes any difference to what I see.
I have run your workflow, just needed to update the postgres connection settings and it worked flawlessly to create a table with the PK as defined in the SQL query.
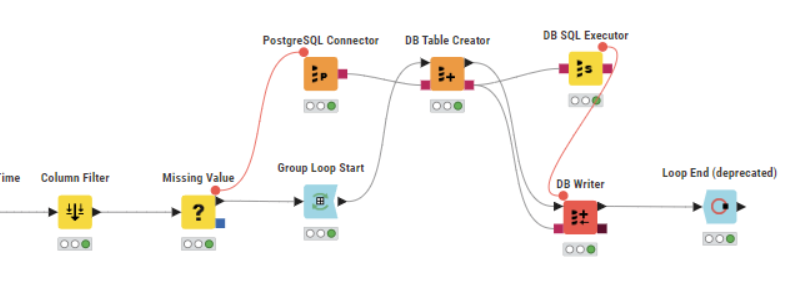
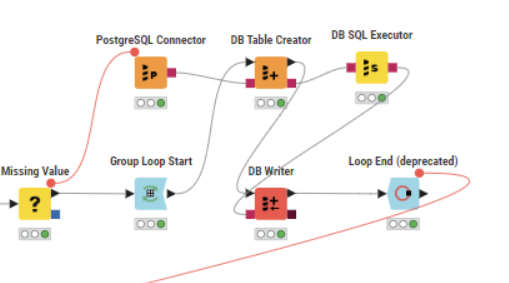
I wonder why they used the Table Selector in that workflow, that too twice. Same for DB Writer?
If you look at my workflow in the above screenshot, it is quite simple. But still does not work.
Please find the sample workflow attached here, just need to set the Postgres connection details and execute the workflow.
I have added a BD Table Selector node following your example, though I am not sure if we need thast node at all for my workflow(??).
Please reply to me with screenshots of the issue and a solution to fix it.
Highly appreciate your time and kind help mate ![]()
@dataHoarder if the syntax does work you will have to work on the flow variables and if the quotation marks are handled correctly. I will see if I can investigate.
I have shared the workflow but replied to @takbb, please find the file in the link ![]()
thanks for the workdlow @dataHoarder. That makes life a little easier ![]()
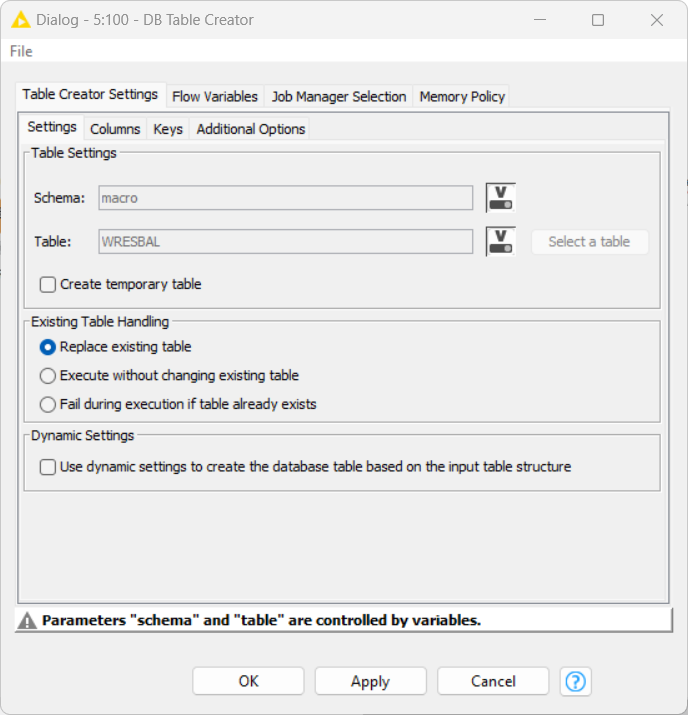
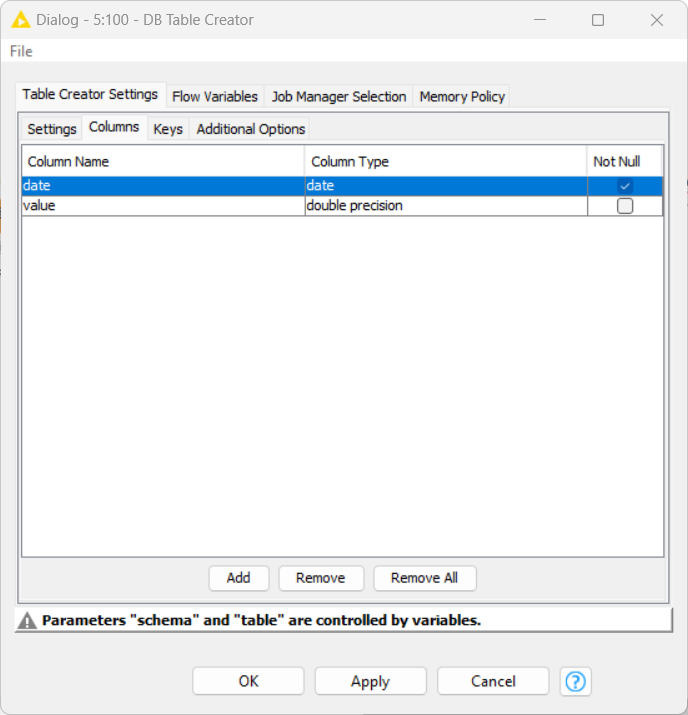
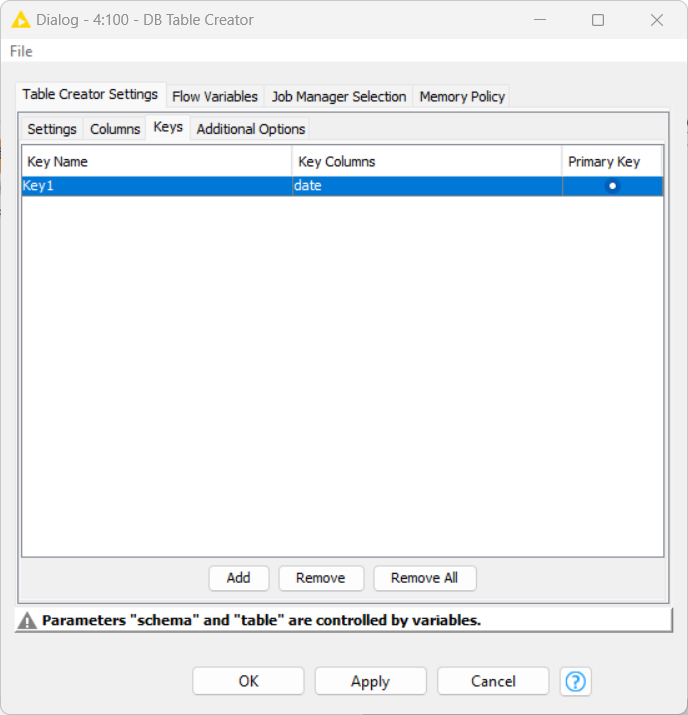
I have been getting some interesting results which I feel sure have not been totally consistent. However I think the problem is related to the date column being dynamically created and therefore not getting a “not null” constraint.
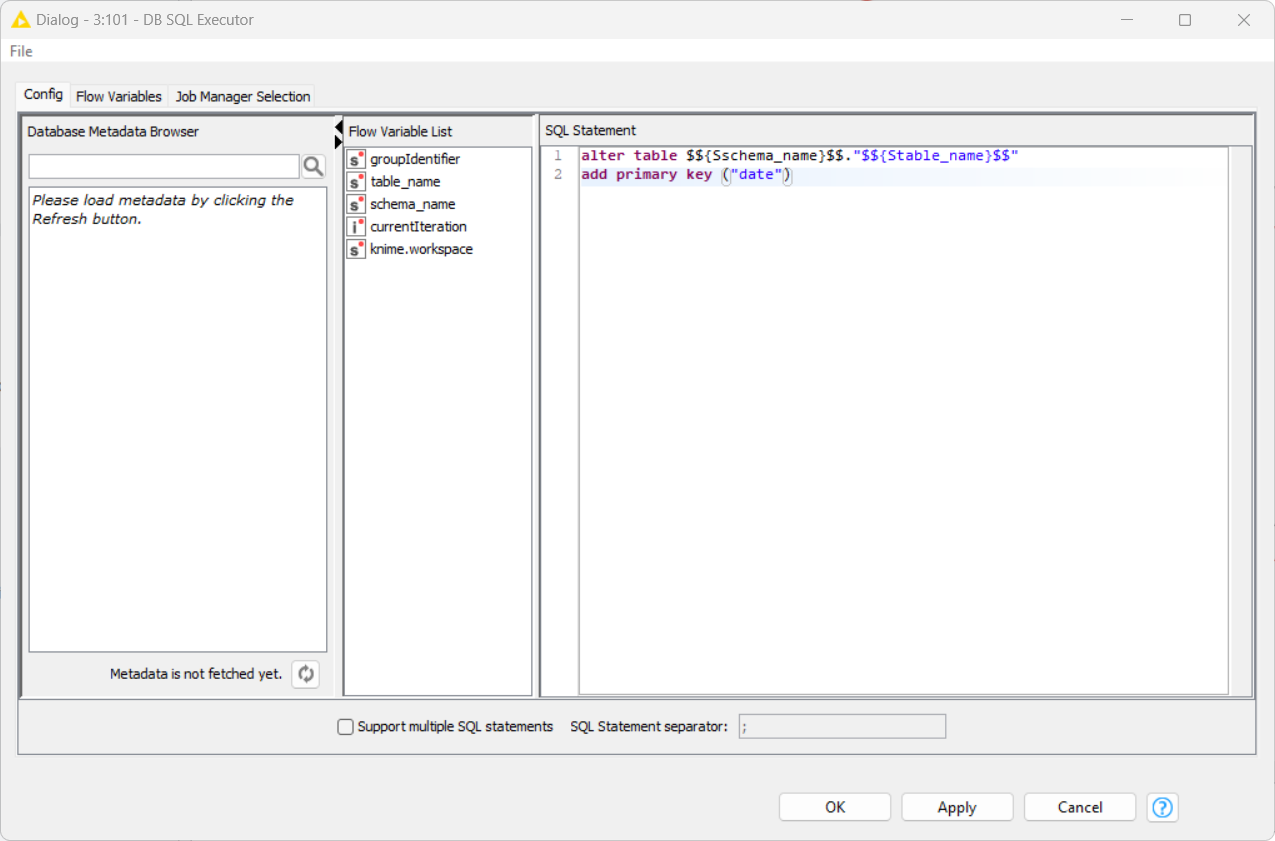
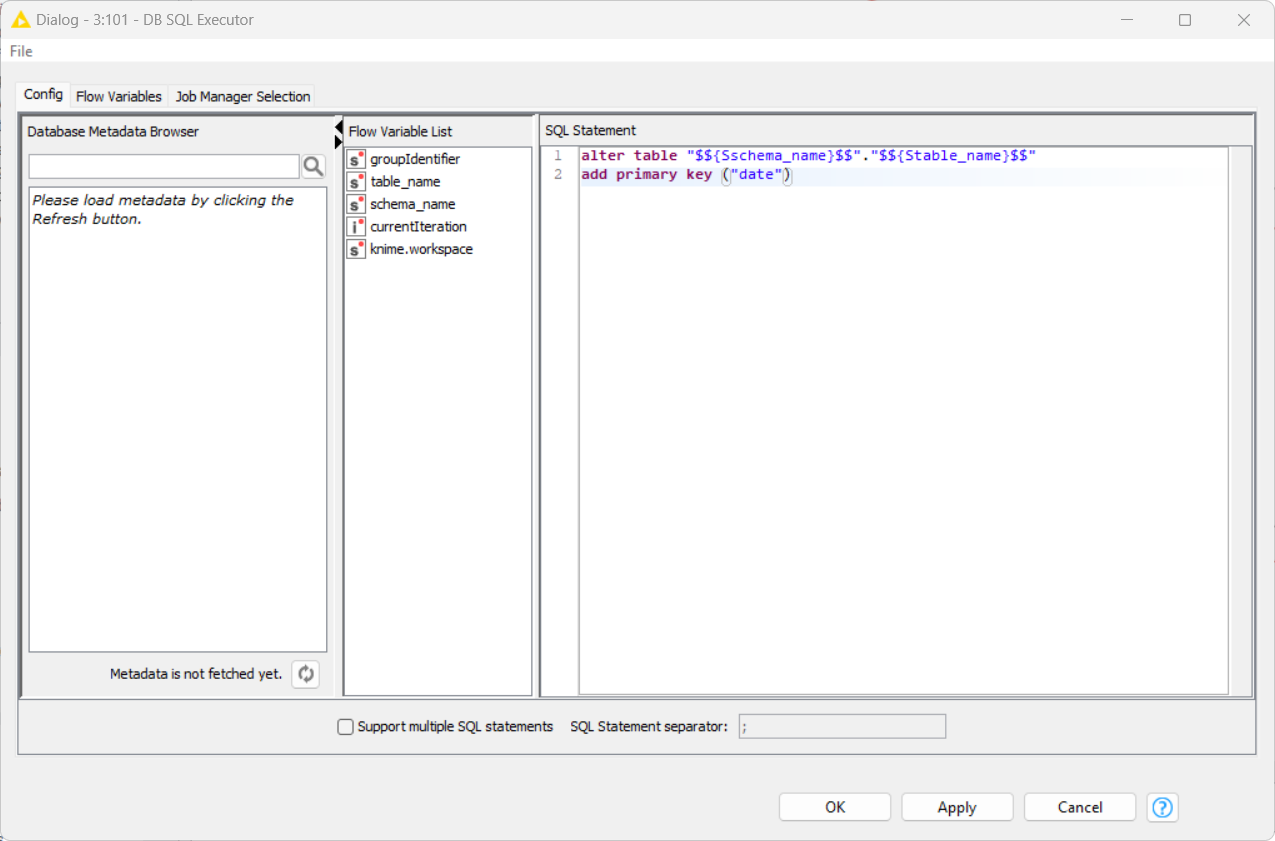
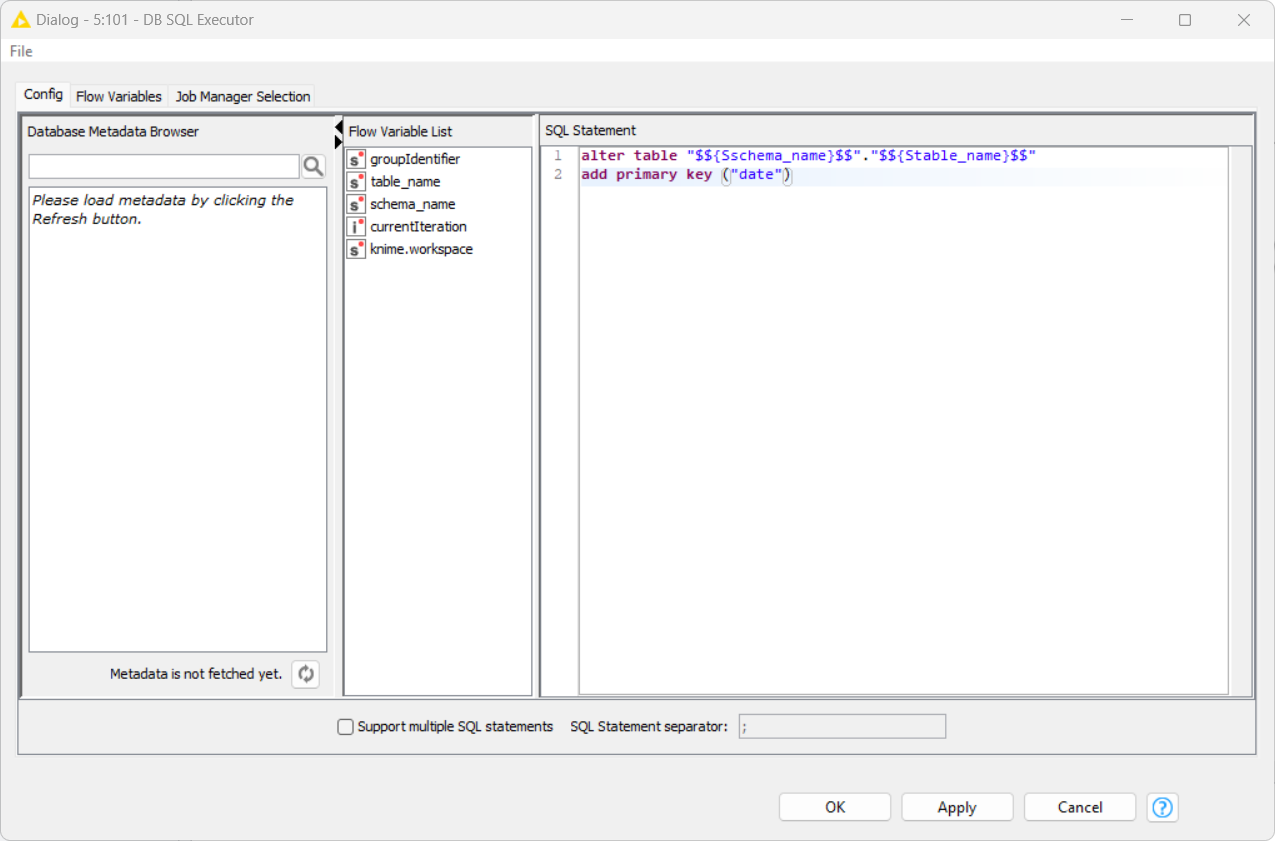
Can you try configuring the DB SQL Executor as follows:
alter table "$${Sschema_name}$$"."$${Stable_name}$$"
alter column "date" set not null;
alter table "$${Sschema_name}$$"."$${Stable_name}$$"
add primary key ("date")
If that works for you, let me know and I’ll see if I can make it work consistently within DB Table Creator, and do away with the DB SQL Executor.
(I did also find myself having to refresh the table details on DBeaver to make it pick up on the new PK constraint)
@dataHoarder it seems it has to do with the use of the group loop. When you just execute the first part of the loop the Primary Key will get created and is there. When you let the loop continue it seems the key gets somehow deleted maybe thru dynamic settings.
I would suggest you find a way to create these tables once and then only fill them and maybe not use dynamic settings.
Edit: Ah ok and you have activated the remove existing table in the DB Writer. So all the work done before gets eliminated … uncheck that …
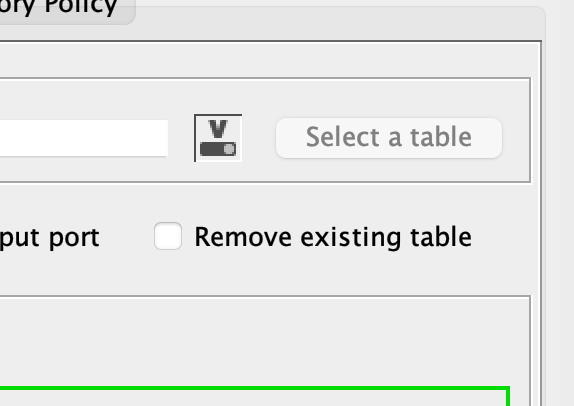
You are correct, I have unchecked it but now I have 2 more NULL columns:
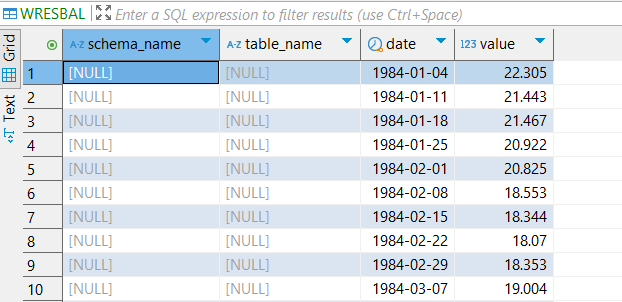
@dataHoarder you might have to remove them from the DB Table creator. With KNIME it makes sense to check all the configurations since the nodes are quite powerful to do what you want. But you will have to configure them.
For the fun of it you can check the definitions of your table with this code. You will have to set the table name and schema.
WITH table_info AS (
SELECT
c.oid AS table_oid,
c.relname AS table_name,
n.nspname AS schema_name
FROM pg_class c
JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE c.relname = 'WRESBAL' AND n.nspname = 'macro'
)
SELECT
-- Schema and Table Information
ti.schema_name AS schema_name,
ti.table_name AS table_name,
-- General column information
col.attname AS column_name,
pg_catalog.format_type(col.atttypid, col.atttypmod) AS data_type,
NOT col.attnotnull AS is_nullable,
pg_catalog.pg_get_expr(def.adbin, def.adrelid) AS default_value,
-- Constraints
CASE
WHEN pk.colname IS NOT NULL THEN 'PRIMARY KEY'
WHEN fk.colname IS NOT NULL THEN 'FOREIGN KEY'
WHEN uk.colname IS NOT NULL THEN 'UNIQUE'
WHEN ck.colname IS NOT NULL THEN 'CHECK'
ELSE NULL
END AS constraint_type,
-- Foreign key details
fk.ref_table AS referenced_table,
fk.ref_column AS referenced_column,
-- Index information
idx.index_name AS index_name,
idx.index_definition AS index_definition
FROM table_info ti
JOIN pg_attribute col ON ti.table_oid = col.attrelid
LEFT JOIN pg_attrdef def ON col.attrelid = def.adrelid AND col.attnum = def.adnum
LEFT JOIN (
SELECT
con.conname AS constraint_name,
a.attname AS colname
FROM pg_constraint con
JOIN pg_attribute a ON con.conrelid = a.attrelid AND a.attnum = ANY(con.conkey)
WHERE con.contype = 'p'
) pk ON col.attname = pk.colname
LEFT JOIN (
SELECT
con.conname AS constraint_name,
a.attname AS colname,
conf.relname AS ref_table,
af.attname AS ref_column
FROM pg_constraint con
JOIN pg_attribute a ON con.conrelid = a.attrelid AND a.attnum = ANY(con.conkey)
JOIN pg_class conf ON con.confrelid = conf.oid
JOIN pg_attribute af ON conf.oid = af.attrelid AND af.attnum = ANY(con.confkey)
WHERE con.contype = 'f'
) fk ON col.attname = fk.colname
LEFT JOIN (
SELECT
con.conname AS constraint_name,
a.attname AS colname
FROM pg_constraint con
JOIN pg_attribute a ON con.conrelid = a.attrelid AND a.attnum = ANY(con.conkey)
WHERE con.contype = 'u'
) uk ON col.attname = uk.colname
LEFT JOIN (
SELECT
con.conname AS constraint_name,
a.attname AS colname
FROM pg_constraint con
JOIN pg_attribute a ON con.conrelid = a.attrelid AND a.attnum = ANY(con.conkey)
WHERE con.contype = 'c'
) ck ON col.attname = ck.colname
LEFT JOIN (
SELECT
i.relname AS index_name,
pg_catalog.pg_get_indexdef(ix.indexrelid) AS index_definition,
a.attname AS colname
FROM pg_index ix
JOIN pg_class i ON i.oid = ix.indexrelid
JOIN pg_attribute a ON ix.indrelid = a.attrelid AND a.attnum = ANY(ix.indkey)
) idx ON col.attname = idx.colname
WHERE col.attnum > 0
AND NOT col.attisdropped
ORDER BY col.attnum
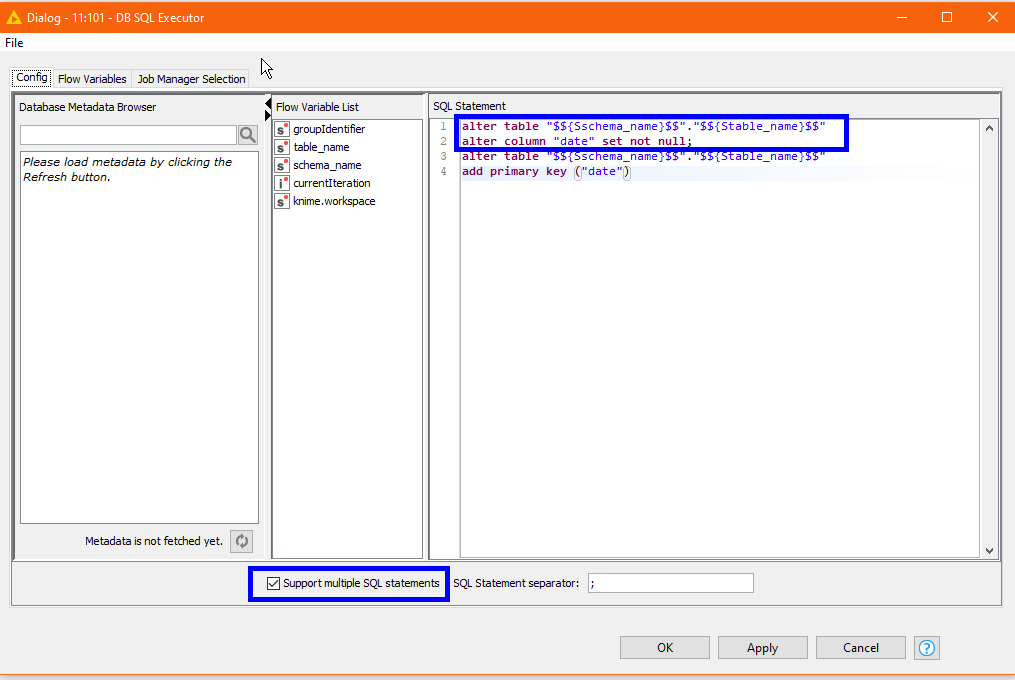
That is exactly what I did, It is working now.
I have also removed the DB Table Selector node:
Settings:
Do we need the DB SQL Executor node separately? Can we incorporate the SQL query into the DB Table Creator node?
I think we don’t need it, as I was able to set PK in DB Table Creator Node.
Revised workflow:
The use of Dynamic Settings in the DB Table Creator node is problematic, turning that off and unchecking the “Remove Existing Table” in the DB Writer node solved it all.
Thanks, everyone!
All is good but facing problems when there is more than one table that needs to be written.
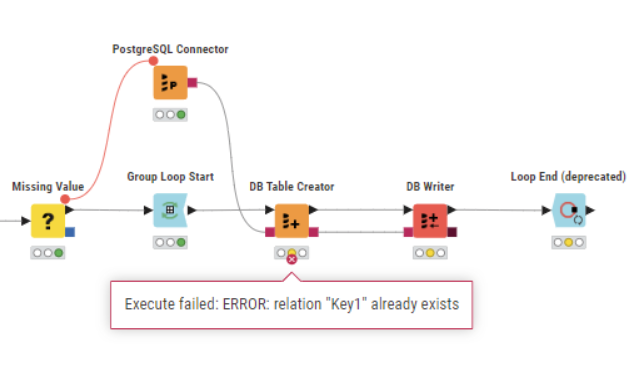
Please find the workflow here, appreciate the help @mlauber71 @takbb ![]()
@dataHoarder most likely you will have to create a unique key name for each iteration