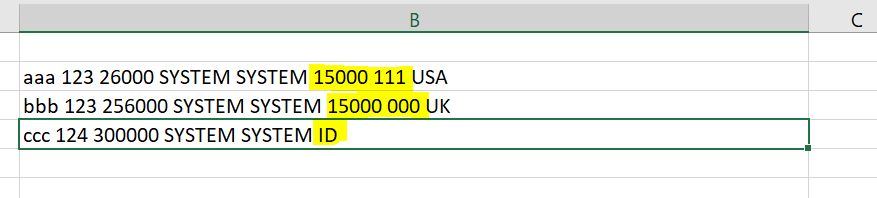
Consider that each row must be having 8 values in it and each one of it has to be going into separate column. But here, row 3 has only 6 values and so the next value present takes up the missing value’s position. How do I fix the same in KNIME? Anyhelp would be appreciated!
Thank you!
The yellow highlighted part is where the value shouldnt be present, but when I do some transformation for bringing the values into columns, the next values occupies it’s place.
PS this is a notepad file which I’m reading and the format of the file is uneven