I am a pretty new at knime analytics platform, so I am still wondering how to make a flow of my sample project.
Say I have 2 tables, table 1 named T1 and table 2 named T2.
The structure of T1 is shown below
ID
VALUE
1
90
2
70
3
125
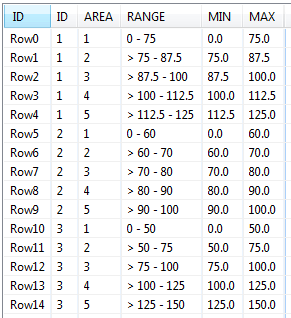
and T2 is shown below
ID
AREA
RANGE
1
1
0 - 75
1
2
> 75 - 87.5
1
3
> 87.5 - 100
1
4
> 100 - 112.5
1
5
> 112.5 - 125
2
1
0 - 60
2
2
> 60 - 70
2
3
> 70 - 80
2
4
> 80 - 90
2
5
> 90 - 100
3
1
0 - 50
3
2
> 50 - 75
3
3
> 75 - 100
3
4
> 100 - 125
3
5
> 125 - 150
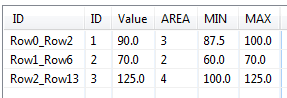
and then I want to make the final table named T3 like shown below
ID
VALUE
AREA
1
90
3
2
70
2
3
125
4
the value of column AREA in T3 got from column AREA of T2 with reference column ID of T1 and T2, and also based on the column VALUE of T1 that matched in column RANGE in T2.
can anyone please help me to create worflow to generate T3 like example above ???
any sugestion are apreciated.
Thanks…
Hi.
Do the values in T2 ever change? If not, this would be easier if you could replace table T2 with a Rule Engine node. The configuration would look something like the following (only a few rules shown)…
Hi dnaki, thanks for your attention…
Yes, the value of T2 is dinamically change and the T2 above is just a sample. In my real case, I have more than 100 ID and each ID has 5 AREA that I must match with the data of T1. If I work with the RULE ENGINE NODE, I think maybe it’s not efficient if write all 100x5=500 condition. Maybe you can share another idea of yours, cause i’m still confuse
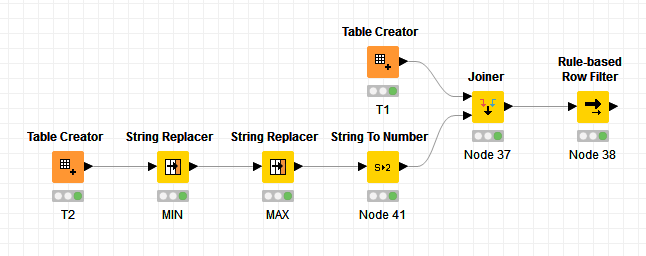
OK, no problem. We’ll try to break down the problem into discrete, manageable steps:
First create separate columns for the min and max values of each range in T2. This will make our task much easier. I used String Replacer nodes with regular expressions to do this, followed by a String To Number node to convert the Strings to numbers (the workflow .knwf file is attached and can be imported into your KNIME Explorer).
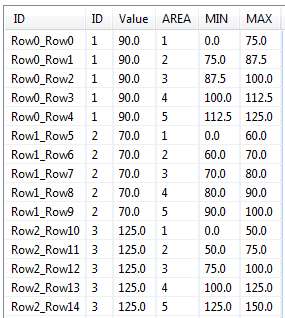
Then use the Joiner node to create a table where each ID row in T1 is joined to each ID row in T2.
So for each row in T1 you’ll get 5 rows in the joined table:
Finally you can use the Rule-Based Row Filter node to keep only the rows where T1.value > MIN and <= MAX. (Note: filter the MIN and MAX columns from the table if you like, using the Column Filter node).
Hi dnaki, i just explore your workflow and i am interesting in String Replacer Node that you used.
In configuration window, you type (>\s*)([-+]?[0-9].?[0-9]+)(\s*-\s*)([-+]?[0-9]*.?[0-9]+) in pattern field.
can you explain how that code works ?
thx before…
Hi. The pattern is called a ‘regular expression’, which is a sequence of characters that define a text search pattern. There isn’t space to go into much detail here, but there are quite a few tutorials on the web.
In the pattern I used: “(>\s*)([-+]?[0-9].?[0-9]+)(\s*-\s*)([-+]?[0-9]*.?[0-9]+)”
there are 4 groups delineated by parenthesis. Each group matches a part of the input String (in your case the values in the Range column). The first group matches a ‘greater than’ sign and optional white space. The next one matches a floating point number. The next one matches optional space and a hyphen and optional space. The next one matches a floating point number.
Again, I would suggest you find a good tutorial on the web to learn more. Regular expressions can be very useful!
Hi dnaki. Thank you so much for your explanation. It’s very helpfull.
Maybe i still need your assistance whenever i got problem in my workflow with knime…